Multilingual Serverless XLM RoBERTa with HuggingFace, AWS Lambda
Currently, we have 7.5 billion people living on the world in around 200 nations. Only 1.2 billion people of them are native English speakers. This leads to a lot of unstructured non-English textual data.
Most of the tutorials and blog posts demonstrate how to build text classification, sentiment analysis, question-answering, or text generation models with BERT based architectures in English. In order to overcome this missing, we are going to build a multilingual Serverless Question Answering API.
Multilingual models describe machine learning models that can understand different languages. An example of a multilingual model is mBERT from Google research. This model supports and understands 104 languages.
We are going to use the new AWS Lambda Container Support to build a Question-Answering API with a xlm-roberta.
Therefore we use the Transformers library by HuggingFace,
the Serverless Framework, AWS Lambda, and Amazon ECR.
The special characteristic about this architecture is that we provide a "State-of-the-Art" model with more than 2GB and that is served in a Serverless Environment
Before we start I wanted to encourage you to read my blog philschmid.de where I have already wrote several blog posts about Serverless, how to deploy BERT in a Serverless Environment, or How to fine-tune BERT models.
You can find the complete code for it in this Github repository.
Transformers Library by Huggingface
The Transformers library provides state-of-the-art machine learning architectures like BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, T5 for Natural Language Understanding (NLU) and Natural Language Generation (NLG). It also provides thousands of pre-trained models in 100+ different languages.
AWS Lambda
AWS Lambda is a serverless computing service that lets you run code without managing servers. It executes your code only when required and scales automatically, from a few requests per day to thousands per second.
Amazon Elastic Container Registry
Amazon Elastic Container Registry (ECR) is a fully managed container registry. It allows us to store, manage, share docker container images. You can share docker containers privately within your organization or publicly worldwide for anyone.
Serverless Framework
The Serverless Framework helps us develop and deploy AWS Lambda functions. It’s a CLI that offers structure, automation, and best practices right out of the box.
The Architecture
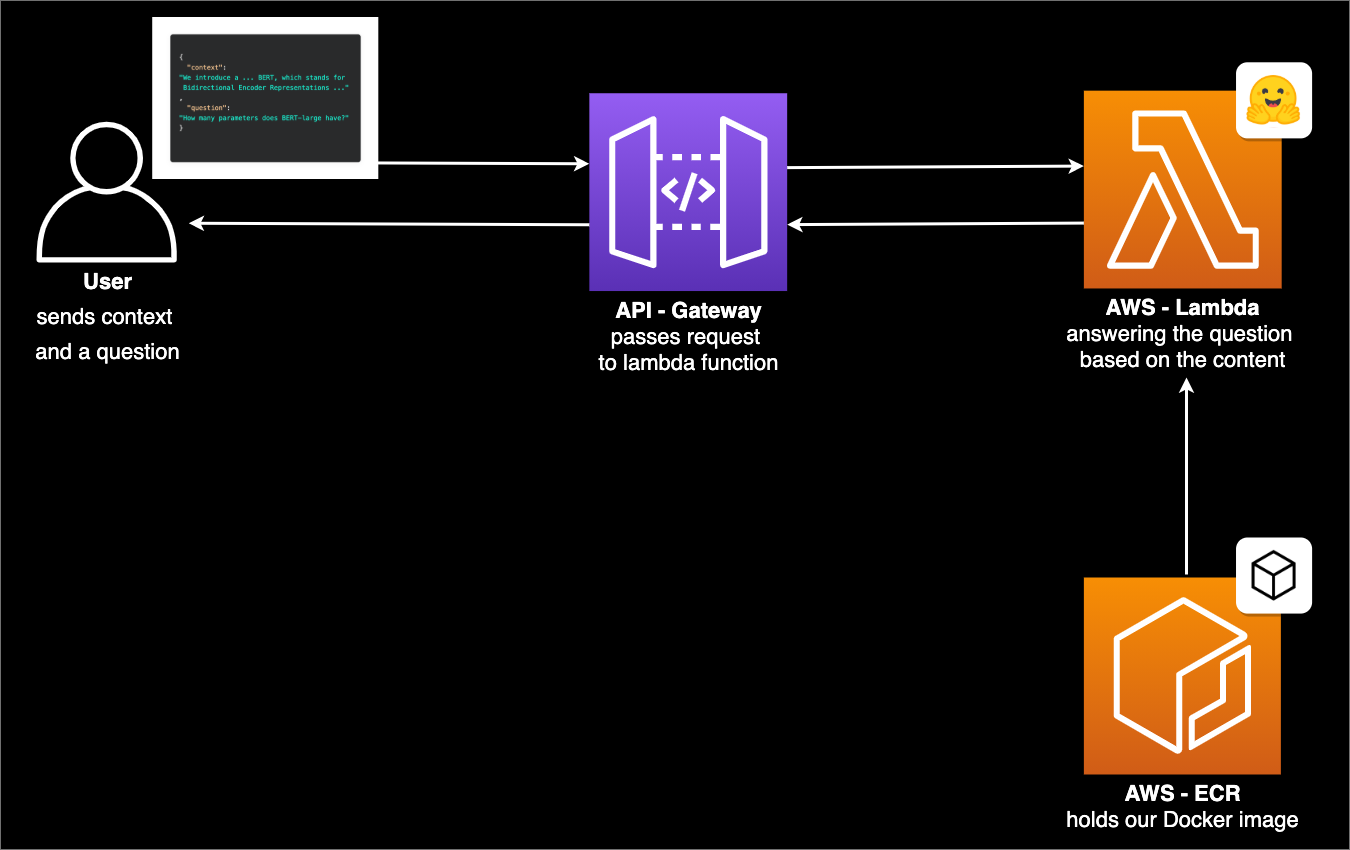
Tutorial
Before we get started, make sure you have the Serverless Framework configured and set up. You
also need a working docker environment. We use docker to create our own custom image including all needed Python
dependencies and our multilingual xlm-roberta model, which we then use in our AWS Lambda function. Furthermore, you
need access to an AWS Account to create an IAM User, an ECR Registry, an API Gateway, and the AWS Lambda function.
We design the API in the following way:
We send a context (small paragraph) and a question to it and respond with the answer to the question. As model, we are
going to use the xlm-roberta-large-squad2 trained by deepset.ai from the
transformers model-hub. The model size is more than 2GB.
It's huge.
What are we going to do:
- create a
PythonLambda function with the Serverless Framework. - add the multilingual
xlm-robertamodel to our function and create an inference pipeline. - Create a custom
dockerimage and test it. - Deploy a custom
dockerimage to ECR. - Deploy AWS Lambda function with a custom
dockerimage. - Test our Multilingual Serverless API.
You can find the complete code in this Github repository.
1. Create a Python Lambda function with the Serverless Framework
First, we create our AWS Lambda function by using the Serverless CLI with the aws-python3 template.
serverless create --template aws-python3 --path serverless-multilingualThis CLI command will create a new directory containing a handler.py, .gitignore, and serverless.yaml file. The
handler.py contains some basic boilerplate code.
2. Add the multilingual xlm-roberta model to our function and create an inference pipeline
To add our xlm-roberta model to our function we have to load it from the
model hub of HuggingFace. For this, I have created a python script. Before we can
execute this script we have to install the transformers library to our local environment and create a model
directory in our serverless-multilingual/ directory.
mkdir model & pip3 install torch==1.5.0 transformers==3.4.0After we installed transformers we create get_model.py file and include the script below.
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
def get_model(model):
"""Loads model from Hugginface model hub"""
try:
model = AutoModelForQuestionAnswering.from_pretrained(model,use_cdn=True)
model.save_pretrained('./model')
except Exception as e:
raise(e)
def get_tokenizer(tokenizer):
"""Loads tokenizer from Hugginface model hub"""
try:
tokenizer = AutoTokenizer.from_pretrained(tokenizer)
tokenizer.save_pretrained('./model')
except Exception as e:
raise(e)
get_model('deepset/xlm-roberta-large-squad2')
get_tokenizer('deepset/xlm-roberta-large-squad2')To execute the script we run python3 get_model.py in the serverless-multilingual/ directory.
python3 get_model.pyTip: add the model directory to .gitignore.
The next step is to adjust our handler.py and include our serverless_pipeline(), which initializes our model and
tokenizer. It then returns a predict function, which we can use in our handler.
import json
import torch
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, AutoConfig
def encode(tokenizer, question, context):
"""encodes the question and context with a given tokenizer"""
encoded = tokenizer.encode_plus(question, context)
return encoded["input_ids"], encoded["attention_mask"]
def decode(tokenizer, token):
"""decodes the tokens to the answer with a given tokenizer"""
answer_tokens = tokenizer.convert_ids_to_tokens(
token, skip_special_tokens=True)
return tokenizer.convert_tokens_to_string(answer_tokens)
def serverless_pipeline(model_path='./model'):
"""Initializes the model and tokenzier and returns a predict function that ca be used as pipeline"""
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForQuestionAnswering.from_pretrained(model_path)
def predict(question, context):
"""predicts the answer on an given question and context. Uses encode and decode method from above"""
input_ids, attention_mask = encode(tokenizer,question, context)
start_scores, end_scores = model(torch.tensor(
[input_ids]), attention_mask=torch.tensor([attention_mask]))
ans_tokens = input_ids[torch.argmax(
start_scores): torch.argmax(end_scores)+1]
answer = decode(tokenizer,ans_tokens)
return answer
return predict
# initializes the pipeline
question_answering_pipeline = serverless_pipeline()
def handler(event, context):
try:
# loads the incoming event into a dictonary
body = json.loads(event['body'])
# uses the pipeline to predict the answer
answer = question_answering_pipeline(question=body['question'], context=body['context'])
return {
"statusCode": 200,
"headers": {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
"Access-Control-Allow-Credentials": True
},
"body": json.dumps({'answer': answer})
}
except Exception as e:
print(repr(e))
return {
"statusCode": 500,
"headers": {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
"Access-Control-Allow-Credentials": True
},
"body": json.dumps({"error": repr(e)})
}3. Create a custom docker image and test it.
Before we can create our docker we need to create a requirements.txt file with all the dependencies we want to
install in our docker.
We are going to use a lighter Pytorch Version and the transformers library.
https://download.pytorch.org/whl/cpu/torch-1.5.0%2Bcpu-cp38-cp38-linux_x86_64.whl
transformers==3.4.0To containerize our Lambda Function, we create a dockerfile in the same directory and copy the following content.
FROM public.ecr.aws/lambda/python:3.8
# Copy function code and models into our /var/task
COPY ./ ${LAMBDA_TASK_ROOT}/
# install our dependencies
RUN python3 -m pip install -r requirements.txt --target ${LAMBDA_TASK_ROOT}
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "handler.handler" ]Additionally we can add a .dockerignore file to exclude files from your container image.
README.md
*.pyc
*.pyo
*.pyd
__pycache__
.pytest_cache
serverless.yaml
get_model.pyTo build our custom docker image we run.
docker build -t multilingual-lambda .We can start our docker by running.
docker run -p 8080:8080 multilingual-lambdaAfterwards, in a separate terminal, we can then locally invoke the function using curl or a REST-Client.
ccurl --request POST \
--url http://localhost:8080/2015-03-31/functions/function/invocations \
--header 'Content-Type: application/json' \
--data '{
"body":"{\"context\":\"Saisonbedingt ging der Umsatz im ersten Quartal des Geschäftsjahres 2019 um 4 Prozent auf 1.970 Millionen Euro zurück, verglichen mit 1.047 Millionen Euro im vierten Quartal des vorangegangenen Geschäftsjahres. Leicht rückläufig war der Umsatz in den Segmenten Automotive (ATV) und Industrial Power Control (IPC). Im Vergleich zum Konzerndurchschnitt war der Rückgang im Segment Power Management & Multimarket (PMM) etwas ausgeprägter und im Segment Digital Security Solutions (DSS) deutlich ausgeprägter. Die Bruttomarge blieb von Quartal zu Quartal weitgehend stabil und fiel von 39,8 Prozent auf 39,5 Prozent. Darin enthalten sind akquisitionsbedingte Abschreibungen sowie sonstige Aufwendungen in Höhe von insgesamt 16 Millionen Euro, die hauptsächlich im Zusammenhang mit der internationalen Rectifier-Akquisition stehen. Die bereinigte Bruttomarge blieb ebenfalls nahezu unverändert und lag im ersten Quartal bei 40,4 Prozent, verglichen mit 40,6 Prozent im letzten Quartal des Geschäftsjahres 2018. Das Segmentergebnis für das erste Quartal des laufenden Fiskaljahres belief sich auf 359 Millionen Euro, verglichen mit 400 Millionen Euro ein Quartal zuvor. Die Marge des Segmentergebnisses sank von 19,5 Prozent auf 18,2 Prozent.\",\n\"question\":\"Was war die bereinigte Bruttomarge?\"\n}"}'
# {"statusCode": 200, "headers": {"Content-Type": "application/json", "Access-Control-Allow-Origin": "*", "Access-Control-Allow-Credentials": true}, "body": "{\"answer\": \"40,4 Prozent\"}"}%Beware we have to stringify our body since we are passing it directly into the function (only for testing).
4. Deploy a custom docker image to ECR
Since we now have a local docker image we can deploy this to ECR. Therefore we need to create an ECR repository with
the name multilingual-lambda.
aws ecr create-repository --repository-name multilingual-lambda > /dev/nullTo be able to push our images we need to login to ECR. We are using the aws CLI v2.x. Therefore we need to define some
environment variables to make deploying easier.
aws_region=eu-central-1
aws_account_id=891511646143
aws ecr get-login-password \
--region $aws_region \
| docker login \
--username AWS \
--password-stdin $aws_account_id.dkr.ecr.$aws_region.amazonaws.comNext we need to tag / rename our previously created image to an ECR format. The format for this is
{AccountID}.dkr.ecr.{region}.amazonaws.com/{repository-name}
docker tag multilingual-lambda $aws_account_id.dkr.ecr.$aws_region.amazonaws.com/multilingual-lambdaTo check if it worked we can run docker images and should see an image with our tag as name

Finally, we push the image to ECR Registry.
docker push $aws_account_id.dkr.ecr.$aws_region.amazonaws.com/multilingual-lambda5. Deploy AWS Lambda function with a custom docker image
I provide the complete serverless.yaml for this example, but we go through all the details we need for our docker
image and leave out all standard configurations. If you want to learn more about the serverless.yaml, I suggest you
check out
Scaling Machine Learning from ZERO to HERO. In
this article, I went through each configuration and explained the usage of them.
Attention: We need at least 9GB of memory and 300s as timeout.
service: multilingual-qa-api
provider:
name: aws # provider
region: eu-central-1 # aws region
memorySize: 10240 # optional, in MB, default is 1024
timeout: 300 # optional, in seconds, default is 6
functions:
questionanswering:
image: 891511646143.dkr.ecr.eu-central-1.amazonaws.com/multilingual-lambda@sha256:4d08a8eb6286969a7594e8f15360f2ab6e86b9dd991558989a3b65e214ed0818
events:
- http:
path: qa # http path
method: post # http methodTo use a docker image in our serverlss.yaml we have to add the image in our function section. The image has
the URL to our docker image also value.
For an ECR image, the URL should look like tihs <account>.dkr.ecr.<region>.amazonaws.com/<repository>@<digest> (e.g
000000000000.dkr.ecr.sa-east-1.amazonaws.com/test-lambda-docker@sha256:6bb600b4d6e1d7cf521097177dd0c4e9ea373edb91984a505333be8ac9455d38)
You can get the ecr url via the AWS Console.
In order to deploy the function, we run serverless deploy.
serverless deployAfter this process is done we should see something like this.
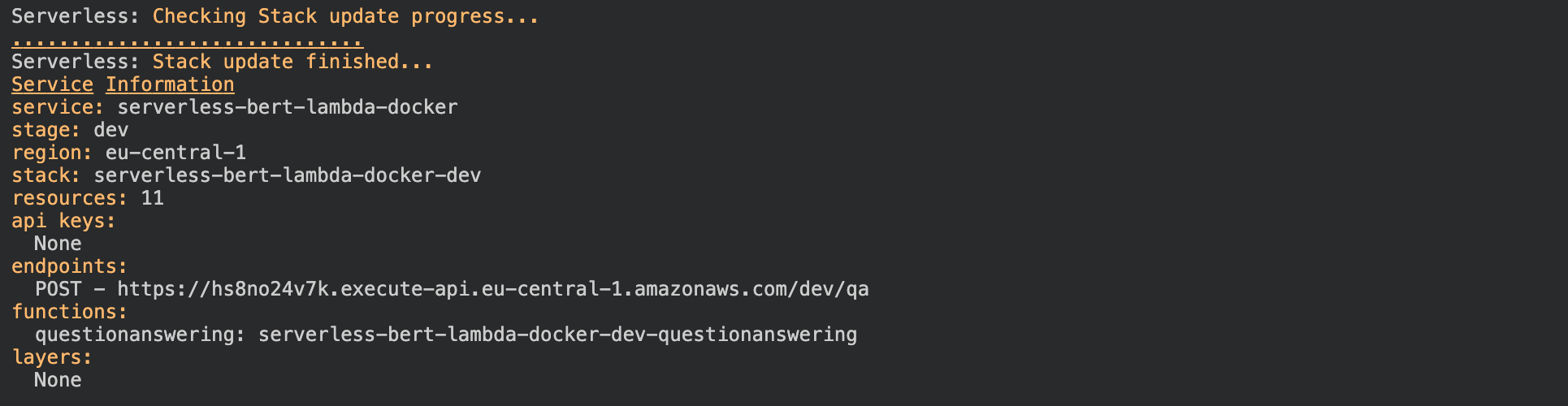
6. Test our Multilingual Serverless API
To test our Lambda function we can use Insomnia, Postman, or any other REST client. Just add a JSON with a context and
a question to the body of your request. Let´s try it with a German example and then with a French example.
Beaware that if you invoke your function the first time there will be an cold start. Due to the model size. The cold start is bigger than 30s so the first request will run into an API Gateway timeout.
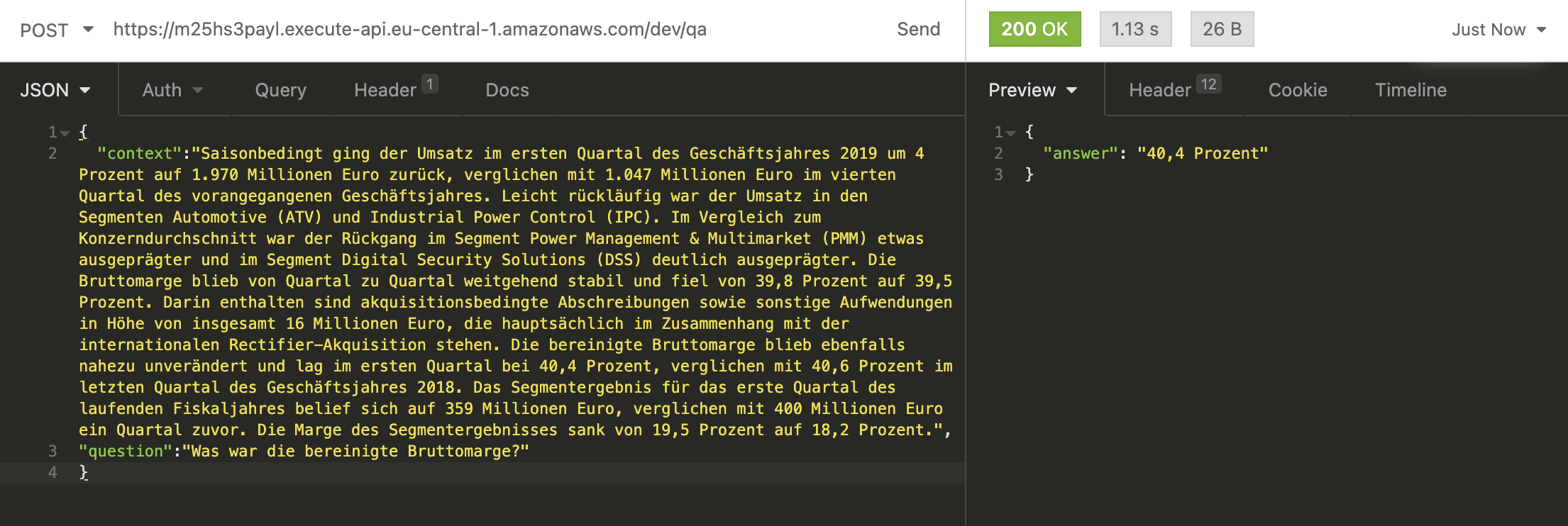
German:
{
"context": "Saisonbedingt ging der Umsatz im ersten Quartal des Geschäftsjahres 2019 um 4 Prozent auf 1.970 Millionen Euro zurück, verglichen mit 1.047 Millionen Euro im vierten Quartal des vorangegangenen Geschäftsjahres. Leicht rückläufig war der Umsatz in den Segmenten Automotive (ATV) und Industrial Power Control (IPC). Im Vergleich zum Konzerndurchschnitt war der Rückgang im Segment Power Management & Multimarket (PMM) etwas ausgeprägter und im Segment Digital Security Solutions (DSS) deutlich ausgeprägter. Die Bruttomarge blieb von Quartal zu Quartal weitgehend stabil und fiel von 39,8 Prozent auf 39,5 Prozent. Darin enthalten sind akquisitionsbedingte Abschreibungen sowie sonstige Aufwendungen in Höhe von insgesamt 16 Millionen Euro, die hauptsächlich im Zusammenhang mit der internationalen Rectifier-Akquisition stehen. Die bereinigte Bruttomarge blieb ebenfalls nahezu unverändert und lag im ersten Quartal bei 40,4 Prozent, verglichen mit 40,6 Prozent im letzten Quartal des Geschäftsjahres 2018. Das Segmentergebnis für das erste Quartal des laufenden Fiskaljahres belief sich auf 359 Millionen Euro, verglichen mit 400 Millionen Euro ein Quartal zuvor. Die Marge des Segmentergebnisses sank von 19,5 Prozent auf 18,2 Prozent.",
"question": "Was war die bereinigte Bruttomarge?"
}Our serverless_pipeline() answered our question correctly with 40,4 Prozent.
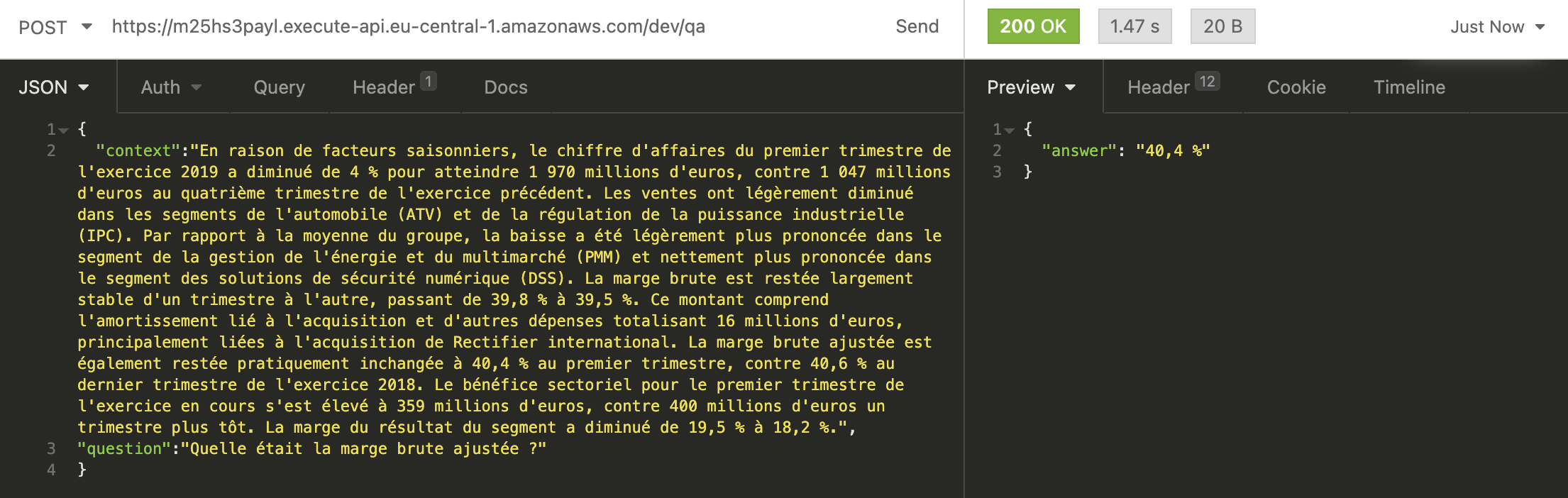
French:
{
"context": "En raison de facteurs saisonniers, le chiffre d'affaires du premier trimestre de l'exercice 2019 a diminué de 4 % pour atteindre 1 970 millions d'euros, contre 1 047 millions d'euros au quatrième trimestre de l'exercice précédent. Les ventes ont légèrement diminué dans les segments de l'automobile (ATV) et de la régulation de la puissance industrielle (IPC). Par rapport à la moyenne du groupe, la baisse a été légèrement plus prononcée dans le segment de la gestion de l'énergie et du multimarché (PMM) et nettement plus prononcée dans le segment des solutions de sécurité numérique (DSS). La marge brute est restée largement stable d'un trimestre à l'autre, passant de 39,8 % à 39,5 %. Ce montant comprend l'amortissement lié à l'acquisition et d'autres dépenses totalisant 16 millions d'euros, principalement liées à l'acquisition de Rectifier international. La marge brute ajustée est également restée pratiquement inchangée à 40,4 % au premier trimestre, contre 40,6 % au dernier trimestre de l'exercice 2018. Le bénéfice sectoriel pour le premier trimestre de l'exercice en cours s'est élevé à 359 millions d'euros, contre 400 millions d'euros un trimestre plus tôt. La marge du résultat du segment a diminué de 19,5 % à 18,2 %.",
"question": "Quelle était la marge brute ajustée ?"
}Our serverless_pipeline() answered our question correctly with 40,4%.
Conclusion
The release of the AWS Lambda Container Support and the increase from Memory up to 10GB enables much wider use of AWS Lambda and Serverless. It fixes many existing problems and gives us greater scope for the deployment of serverless applications.
I mean we deployed a docker container containing a "State-of-the-Art" multilingual NLP model bigger than 2GB in a Serverless Environment without the need to manage any server.
It will automatically scale up to thousands of parallel requests without any worries.
The future looks more than golden for AWS Lambda and Serverless.
You can find the GitHub repository with the complete code here.
Thanks for reading. If you have any questions, feel free to contact me or comment on this article. You can also connect with me on Twitter or LinkedIn.