Multi-Model GPU Inference with Hugging Face Inference Endpoints
Multi-model inference endpoints provide a way to deploy multiple models onto the same infrastructure for a scalable and cost-effective inference. Multi-model inference endpoints load a list of models into memory, either CPU or GPU, and dynamically use them during inference.
This blog will cover how to create a multi-model inference endpoint using 5 models on a single GPU and how to use it in your applications.
You will learn how to:
- Create a multi-model
EndpointHandlerclass - Deploy the multi-model inference endpoints
- Send requests to different models
The following diagram shows how multi-model inference endpoints look.
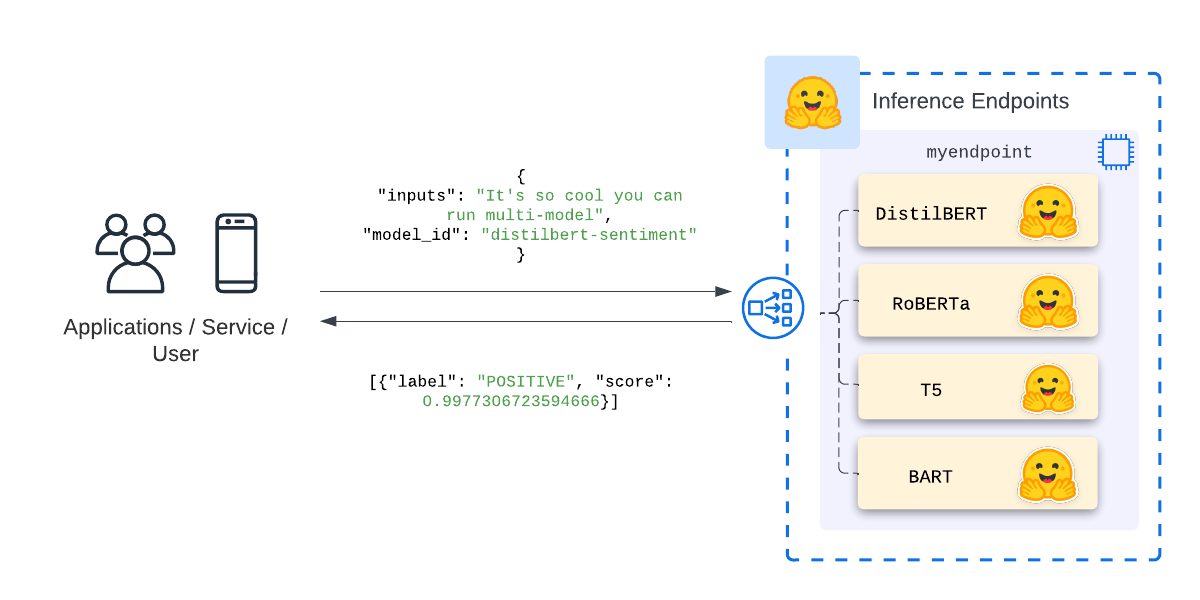
What are Hugging Face Inference Endpoints?
🤗 Inference Endpoints offer a secure production solution to easily deploy Machine Learning models on dedicated and autoscaling infrastructure managed by Hugging Face.
A Hugging Face Inference Endpoint is built from a Hugging Face Model Repository. It supports all the Transformers and Sentence-Transformers tasks and any arbitrary ML Framework through easy customization by adding a custom inference handler. This custom inference handler can be used to implement simple inference pipelines for ML Frameworks like Keras, Tensorflow, and scit-kit learn, create multi-model endpoints, or can be used to add custom business logic to your existing transformers pipeline.
1. Create a multi-model EndpointHandler class
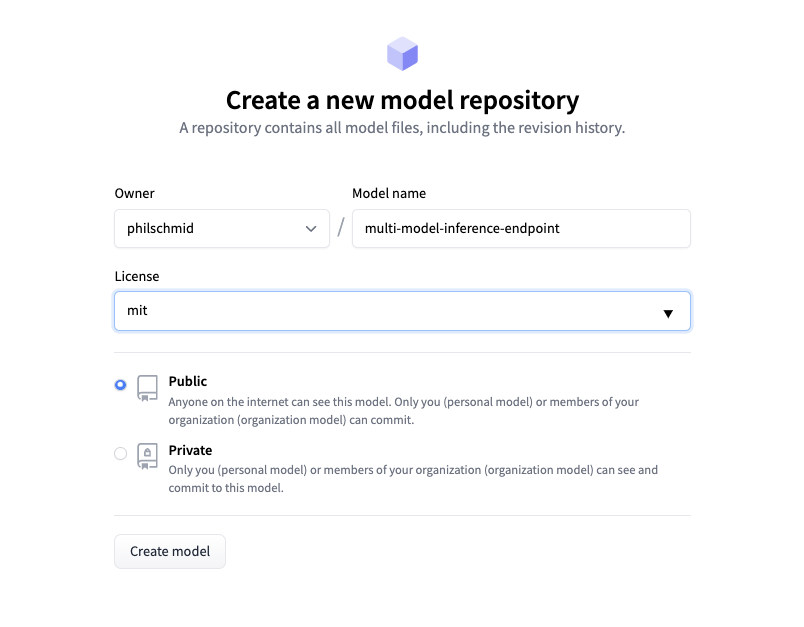
The first step is to create a new Hugging Face Repository with our multi-model EndpointHandler class. In this example, we dynamically load our models in the EndpointHandler on endpoint creation. Alternatively, you could add the model weights into the same repository and load them from the disk.
This means our Hugging Face Repository contains a handler.py with our EndpointHandler.
We create a new repository at https://huggingface.co/new.
Then we create a handler.py with the EndpointHandler class. If you are unfamiliar with custom handlers on Inference Endpoints, you can check out Custom Inference with Hugging Face Inference Endpoints or read the documentation.
An example of a multi-model EndpointHandler is shown below. This handler loads 5 different models using the Transformers pipeline.
# handler.py
import torch
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
# check for GPU
device = 0 if torch.cuda.is_available() else -1
# multi-model list
multi_model_list = [
{"model_id": "distilbert-base-uncased-finetuned-sst-2-english", "task": "text-classification"},
{"model_id": "Helsinki-NLP/opus-mt-en-de", "task": "translation"},
{"model_id": "facebook/bart-large-cnn", "task": "summarization"},
{"model_id": "dslim/bert-base-NER", "task": "token-classification"},
{"model_id": "textattack/bert-base-uncased-ag-news", "task": "text-classification"},
]
class EndpointHandler():
def __init__(self, path=""):
self.multi_model={}
# load all the models onto device
for model in multi_model_list:
self.multi_model[model["model_id"]] = pipeline(model["task"], model=model["model_id"], device=device)
def __call__(self, data):
# deserialize incomin request
inputs = data.pop("inputs", data)
parameters = data.pop("parameters", None)
model_id = data.pop("model_id", None)
# check if model_id is in the list of models
if model_id is None or model_id not in self.multi_model:
raise ValueError(f"model_id: {model_id} is not valid. Available models are: {list(self.multi_model.keys())}")
# pass inputs with all kwargs in data
if parameters is not None:
prediction = self.multi_model[model_id](inputs, **parameters)
else:
prediction = self.multi_model[model_id](inputs)
# postprocess the prediction
return predictionThe most important section in our handler is the multi_model_list, a list of dictionaries including our Hugging Face Model Ids and the task for the models.
You can customize the list to the models you want to use for your multi-model inference endpoint. In this example, we will use the following:
DistilBERTmodel forsentiment-analysisMarianmodeltranslationBARTmodel forsummarizationBERTmodel fortoken-classificationBERTmodel fortext-classification
All those models will be loaded at the endpoint creation and then used dynamically during inference by providing a model_id attribute in the request.
Note: The number of models is limited by the amount of GPU memory your instance has. The bigger the instance, the more models you can load.
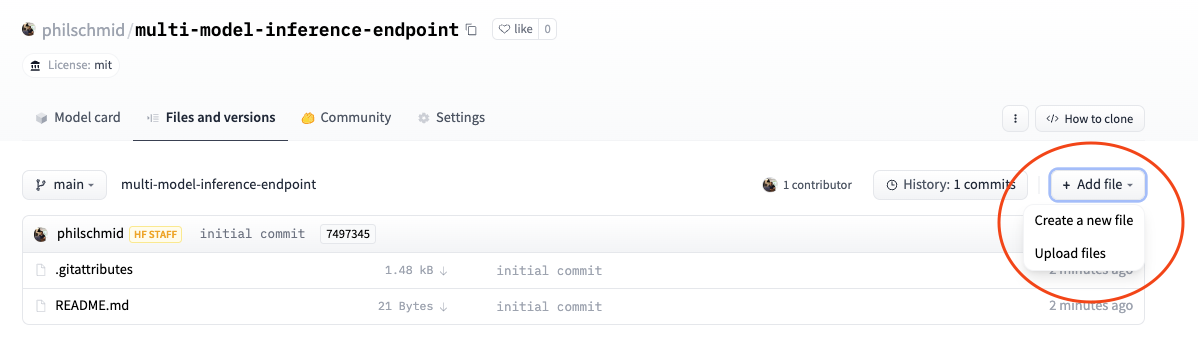
As the last step, we add/upload our handler.py to our repository, this can be done through the UI in the “Files and versions” tab.
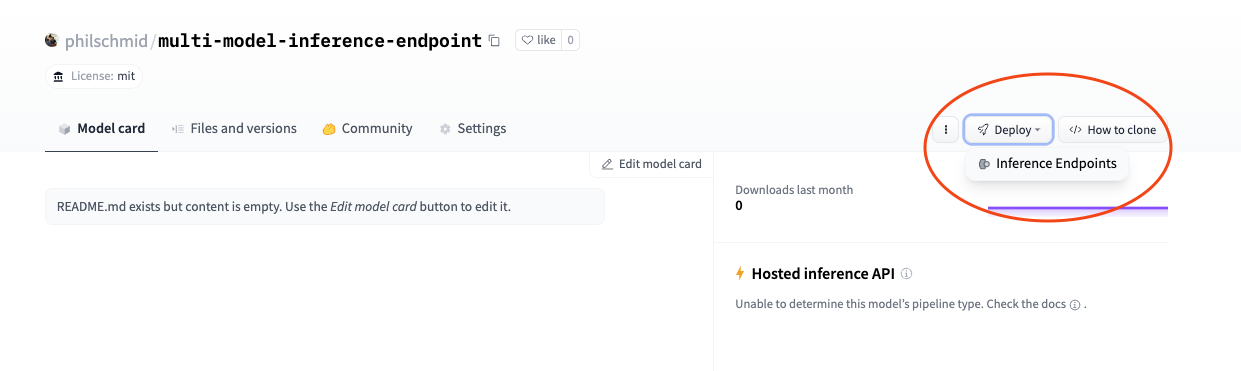
2. Deploy the multi-model inference endpoints
The next step is to deploy our multi-model inference endpoint. We can use the “deploy” button, which appeared after we added our handler.py. This will directly link us to the Inference Endpoints UI with our repository pre-select.
We change the Instance Type to “GPU [small]” to use an NVIDIA T4 and then click “Create Endpoint”
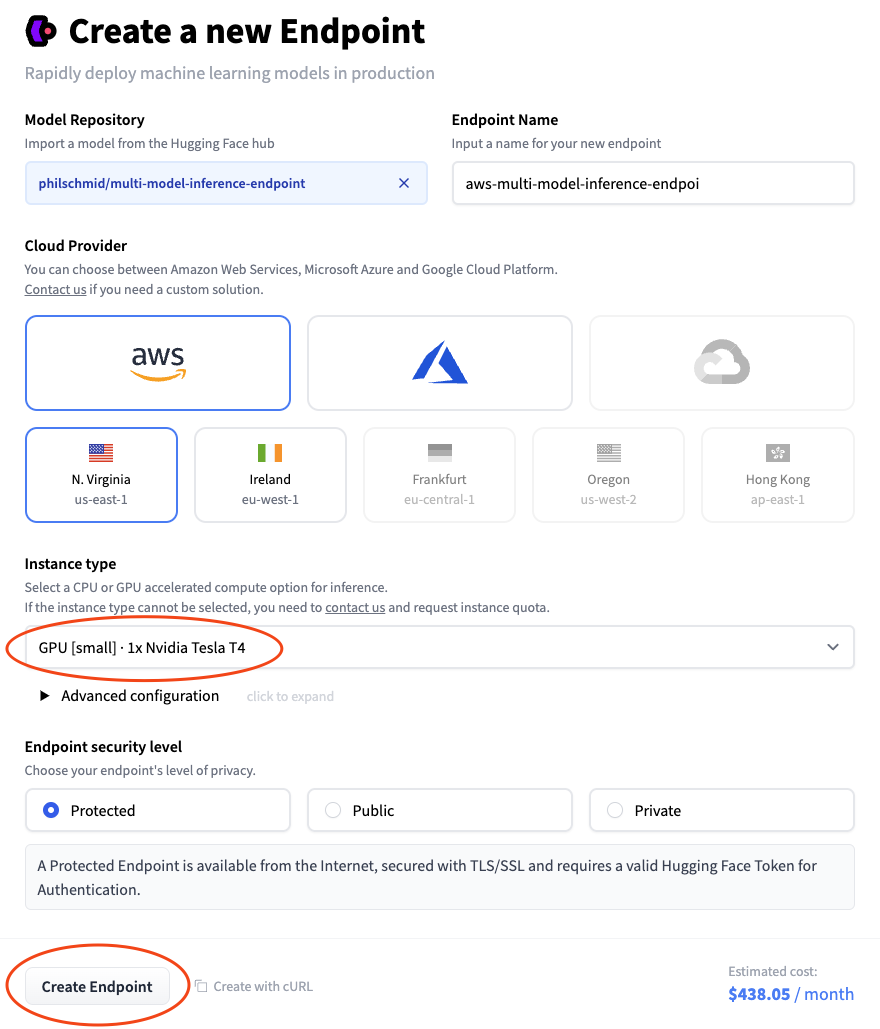
After a few minutes, our Inference Endpoint will be up and running. We can also check the logs to see the download of our five models.
3. Send requests to different models
After our Endpoint is “running” we can send requests to our different models. This can be done through the UI, with the inference widget, or programmatically using HTTP requests.
Don’t forget! We must add the model_id parameter, in addition to our regular inputs, which defines the model we want to use. You can find example payloads for all tasks in the documentation.
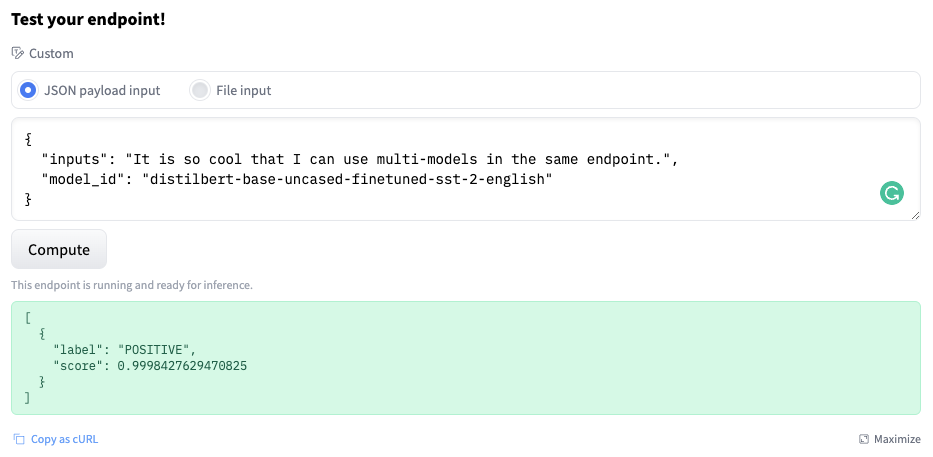
To send a request to our DistilBERT model, we use the following JSON payload.
{
"inputs": "It is so cool that I can use multi-models in the same endpoint.",
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
To send programmatic requests we can for example use Python and the requests library.
To send a request to our BART model to summarize some text, we can use the following Python snippet.
import json
import requests as r
ENDPOINT_URL = "" # url of your endpoint
HF_TOKEN = "" # token of the account you deployed
# define model and payload
model_id = "facebook/bart-large-cnn"
text = "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct."
request_body = {"inputs": text, "model_id": model_id}
# HTTP headers for authorization
headers= {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": "application/json"
}
# send request
response = r.post(ENDPOINT_URL, headers=headers, json=request_body)
prediction = response.json()
# [{'summary_text': 'The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world.'}]Conclusion
Now you know how to deploy a multi-model inference endpoint and how it can help you reduce your costs but still benefit from GPU inference.
As of today, multi-model endpoints are “single” threaded (1 worker), which means your endpoint processes all requests in sequence. By having multiple models in the same endpoint, you might have lower throughput depending on your traffic.
Further improvements and customization you could make are:
- Save the model weights into our multi-model-endpoint repository instead of loading them on startup time.
- Customize model inference by adding
EndpointHandlerfor each model and use them rather than thepipeline.
As you can see, multi-model inference endpoints can be adjusted and customized to our needs. But you should still watch your request pattern and the load of models to identify if single model endpoints for high-traffic models make sense.
Thanks for reading. If you have any questions, contact me via email or forum. You can also connect with me on Twitter or LinkedIn.