Custom Inference with Hugging Face Inference Endpoints
Welcome to this tutorial on how to create a custom inference handler for Hugging Face Inference Endpoints.
The tutorial will cover how to extend a default transformers pipeline with custom business logic, customize the request & response body, and add additional Python dependencies.
You will learn how to:
- Set up Development Environment
- Create a base
EndpointHandlerclass - Customize
EndpointHandler - Test
EndpointHandler - Push the custom handler to the hugging face repository
- Deploy the custom handler as an Inference Endpoint
Let's get started! 🚀
What is Hugging Face Inference Endpoints?
🤗 Inference Endpoints offers a secure production solution to easily deploy Machine Learning models on dedicated and autoscaling infrastructure managed by Hugging Face.
A Hugging Face Inference Endpoint is built from a Hugging Face Model Repository](https://huggingface.co/models). It supports all of the Transformers and Sentence-Transformers tasks and any arbitrary ML Framework through easy customization by adding a custom inference handler. This custom inference handler can be used to implement simple inference pipelines for ML Frameworks like Keras, Tensorflow, and scit-kit learn or can be used to add custom business logic to your existing transformers pipeline.
Tutorial: Create a custom inference handler
Creating a custom Inference handler for Hugging Face Inference endpoints is super easy you only need to add a handler.py in the model repository you want to deploy which implements an EndpointHandler class with an __init__ and a __call__ method.
We will use the philschmid/distilbert-base-uncased-emotion repository in the tutorial. The repository includes a DistilBERT model fine-tuned to detect emotions in the tutorial. We will create a custom handler which:
- customizes the request payload to add a date field
- add an external package to check if the date is a holiday
- add a custom post-processing step to check whether the input date is a holiday. If the date is a holiday we will fix the emotion to “happy” - since everyone is happy when there are holidays 🌴🎉😆
Before we can get started make sure you meet all of the following requirements:
- A Hugging Face model repository with your model weights
- An Organization/User with an active plan and WRITEaccess to the model repository.
You can access Inference Endpoints with a PRO user account or a Lab organization with a credit card on file. Check out our plans.
If you want to create a Custom Handler for an existing model from the community, you can use the repo_duplicator to create a repository fork, which you can then use to add your handler.py.
1. Set up Development Environment
The easiest way to develop our custom handler is to set up a local development environment, to implement, test, and iterate there, and then deploy it as an Inference Endpoint. The first step is to install all required development dependencies. needed to create the custom handler, not needed for inference
# install git-lfs to interact with the repository
sudo apt-get update
sudo apt-get install git-lfs
# install transformers
pip install transformers[sklearn,sentencepiece,audio,vision]After we have installed our libraries we will clone our repository to our development environment.
git lfs install
git clone https://huggingface.co/philschmid/distilbert-base-uncased-emotionTo be able to push our custom handler, we need to login into our HF account. This can be done by using the huggingface-cli.
# setup cli with token
huggingface-cli login
git config --global credential.helper store2. Create a base EndpointHandler class
After we have set up our environment, we can start creating your custom handler. The custom handler is a Python class (EndpointHandler) inside a handler.py file in our repository. The EndpointHandler needs to implement an __init__ and a __call__ method.
- The
__init__method will be called when starting the Endpoint and will receive 1 argument, a string with the path to your model weights. This allows you to load your model correctly. - The
__call__method will be called on every request and receive a dictionary with your request body as a python dictionary. It will always contain theinputskey.
The first step is to create our handler.py in the local clone of our repository.
cd distilbert-base-uncased-emotion && touch handler.pyNext, we add the EndpointHandler class with the __init__ and __call__ method.
from typing import Dict, List, Any
class EndpointHandler():
def __init__(self, path=""):
# Preload all the elements you are going to need at inference.
# pseudo
# self.model = load_model(path)
def __call__(self, data: Dict[str, Any]) -> List[Dict[str, Any]]:
"""
data args:
inputs (:obj: `str` | `PIL.Image` | `np.array`)
kwargs
Return:
A :obj:`list` | `dict`: will be serialized and returned
"""
# pseudo
# self.model(input)3. Customize EndpointHandler
The third step is to add the custom logic we want to use during initialization (__init__) or inference (__call__). You can already find multiple Custom Handler on the Hub if you need some inspiration.
First, we need to create a new requirements.txt, add our holiday detection package, and ensure we have it installed in our development environment.
# add packages to requirements.txt
echo "holidays" >> requirements.txt
# install in local environment
pip install -r requirements.txtNext, we must adjust our handler.py and EndpointHandler to match our condition.
from typing import Dict, List, Any
from transformers import pipeline
import holidays
class EndpointHandler():
def __init__(self, path=""):
self.pipeline = pipeline("text-classification",model=path)
self.holidays = holidays.US()
def __call__(self, data: Dict[str, Any]) -> List[Dict[str, Any]]:
"""
data args:
inputs (:obj: `str`)
date (:obj: `str`)
Return:
A :obj:`list` | `dict`: will be serialized and returned
"""
# get inputs
inputs = data.pop("inputs",data)
date = data.pop("date", None)
# check if date exists and if it is a holiday
if date is not None and date in self.holidays:
return [{"label": "happy", "score": 1}]
# run normal prediction
prediction = self.pipeline(inputs)
return prediction4. Test EndpointHandler
We can test our EndpointHandler by importing it in another file/notebook, creating an instance of it, and then testing it by sending a prepared payload.
from handler import EndpointHandler
# init handler
my_handler = EndpointHandler(path=".")
# prepare sample payload
non_holiday_payload = {"inputs": "I am quite excited how this will turn out", "date": "2022-08-08"}
holiday_payload = {"inputs": "Today is a though day", "date": "2022-07-04"}
# test the handler
non_holiday_pred=my_handler(non_holiday_payload)
holiday_payload=my_handler(holiday_payload)
# show results
print("non_holiday_pred", non_holiday_pred)
print("holiday_payload", holiday_payload)
# non_holiday_pred [{'label': 'joy', 'score': 0.9985942244529724}]
# holiday_payload [{'label': 'happy', 'score': 1}]It works!!!! 🎉
Note: If you are using a notebook, you might have to restart your kernel when you make changes to the handler.py since it is not automatically re-imported.
5. Push the custom handler to the hugging face repository
After successfully testing our handler locally, we can push it to your repository using basic git commands.
# add all our new files
git add requirements.txt handler.py
# commit our files
git commit -m "add custom handler"
# push the files to the hub
git pushNow, you should see your handler.py and requirements.txt in your repository in the “Files and version” tab.
6. Deploy the custom handler as an Inference Endpoint
The last step is to deploy our custom handler as an Inference Endpoint. We can deploy our custom Custom Handler the same way as a regular Inference Endpoint.
Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy.

The Inference Endpoint Service will check during the creation of your Endpoint if there is a handler.py available and valid and will use it for serving requests no matter which “Task” you select.
Note: If you modify the payload, e.g., adding a field, select “Custom” as the task in the advanced configuration. This will replace the inference widget with the custom Inference widget.

After deploying our endpoint, we can test it using the inference widget. Since we have a Custom task, we have to provide a raw JSON as input.
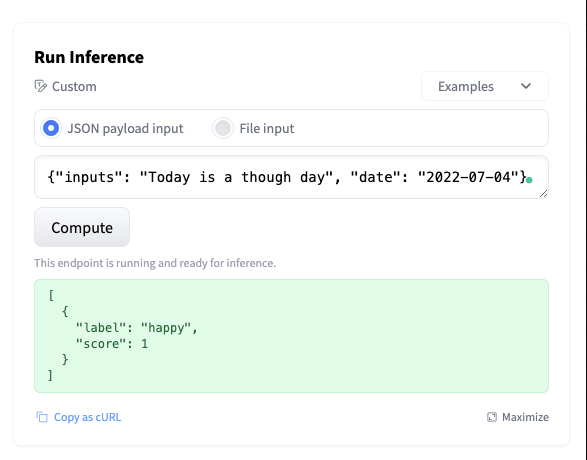
Conclusion
That's it we successfully created and deployed a custom inference handler to Hugging Face Inference Endpoints in 6 simple steps in less than 30 minutes.
To underline this again, we created a managed, secure, scalable inference endpoint that runs our custom handler, including our custom logic. We only needed to create our handler, define two methods, and then create our Endpoint through the UI.
This will allow Data scientists and Machine Learning Engineers to focus on R&D, improving the model rather than fiddling with MLOps topics.
Now, it's your turn! Sign up and create your custom handler within a few minutes!
Thanks for reading. If you have any questions, contact me via email or forum. You can also connect with me on Twitter or LinkedIn.