Memory in Agents, Make LLMs remember.
Imagine hiring a brilliant co-worker. They can reason, write, and research with incredible skill. But there’s a catch: every day, they forget everything they ever did, learned or said. This is the reality of most Agents today. They are powerful but are inherently stateless. We are making significant progress in reasoning and tool use, but the ability for Agents to remember past interactions, preferences, and learned skills remains heavily under explored.
The Core Challenge: Context Engineering
The context window of LLMs is a (currently) limited space where it processes information. This window has a limited bandwith, but should include the right information and tools, in the right format, at the right time for an LLM to perform a task. This is now known under Context Engineering.
It is a delicate balance “of filling the context window with just the right information for the next step" - AK. Too little context, and the agent fails. Too much or irrelevant context, and costs rise while performance can decrease and the most powerful source for that "right information" is the agent's own memory/context.
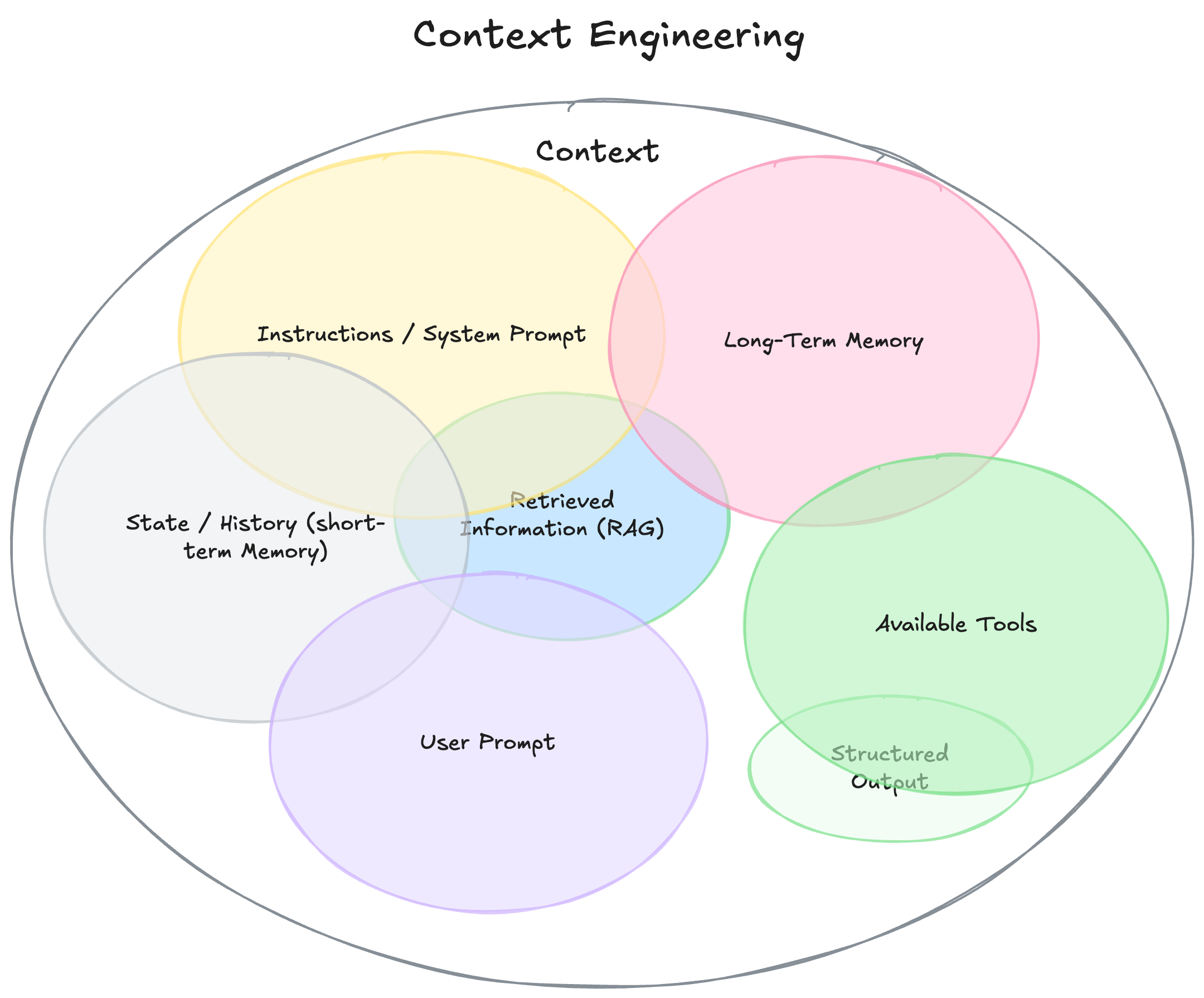
What is AI Agent Memory?
Since LLMs lack inherent memory, it must be intentionally engineered into the architecture. Like human cognition, agent memory operates on two different timelines, short-term memory and long-term memory.
Benefits of Agent Memory
Integrating memory unlocks capabilities that are impossible for stateless models:
- Deep Personalization: Agents can remember user preferences, history, and style, tailoring interactions to each individual.
- Continuity: Tasks can be paused and resumed across multiple sessions without losing context.
- Improved Efficiency: Agents avoid asking for the same information repeatedly and learn from past successes and failures.
- Complex Reasoning: By recalling relevant facts and experiences, agents can tackle multi-step problems that require historical context.
Short-Term Memory (Working Memory)
Short-term memory is the context window itself. It holds the system instructions, recent conversation history, current instructions, tool definitions and information relevant to the current interaction. It's “fast” and essential for the current task, but temporary and limited in size. It needs to be re-constructed for every call to the LLM.
Long-Term Memory (Persistent Storage)
Long-term memory requires external data stores, such as vector databases. It allows the agent to store and recall information across multiple sessions and extended periods. This is where true personalization and “learning” happens. The long-term memory is loaded into the short-term memory when relevant/helpful. Long-term memory can be specialized into three types:
- Semantic Memory ("What"): Retaining specific facts, concepts, and structured knowledge about users, e.g. user prefers Python over JavaScript.
- Episodic Memory ("When" and "Where"): Recall past events or specific experiences to accomplish tasks by looking at past interactions. Think of few-shot examples, but real data.
- Procedural Memory ("How"): internalized rules and instructions on how an agent performs tasks, e.g. “My summaries are too long" if multiple users provide feedback to be shorter.
Add Memory to Agents: Implicit vs. Explicit
There are two strategies for how and when an agent writes or updates its memory: explicitly during interaction or implicitly via a background process.
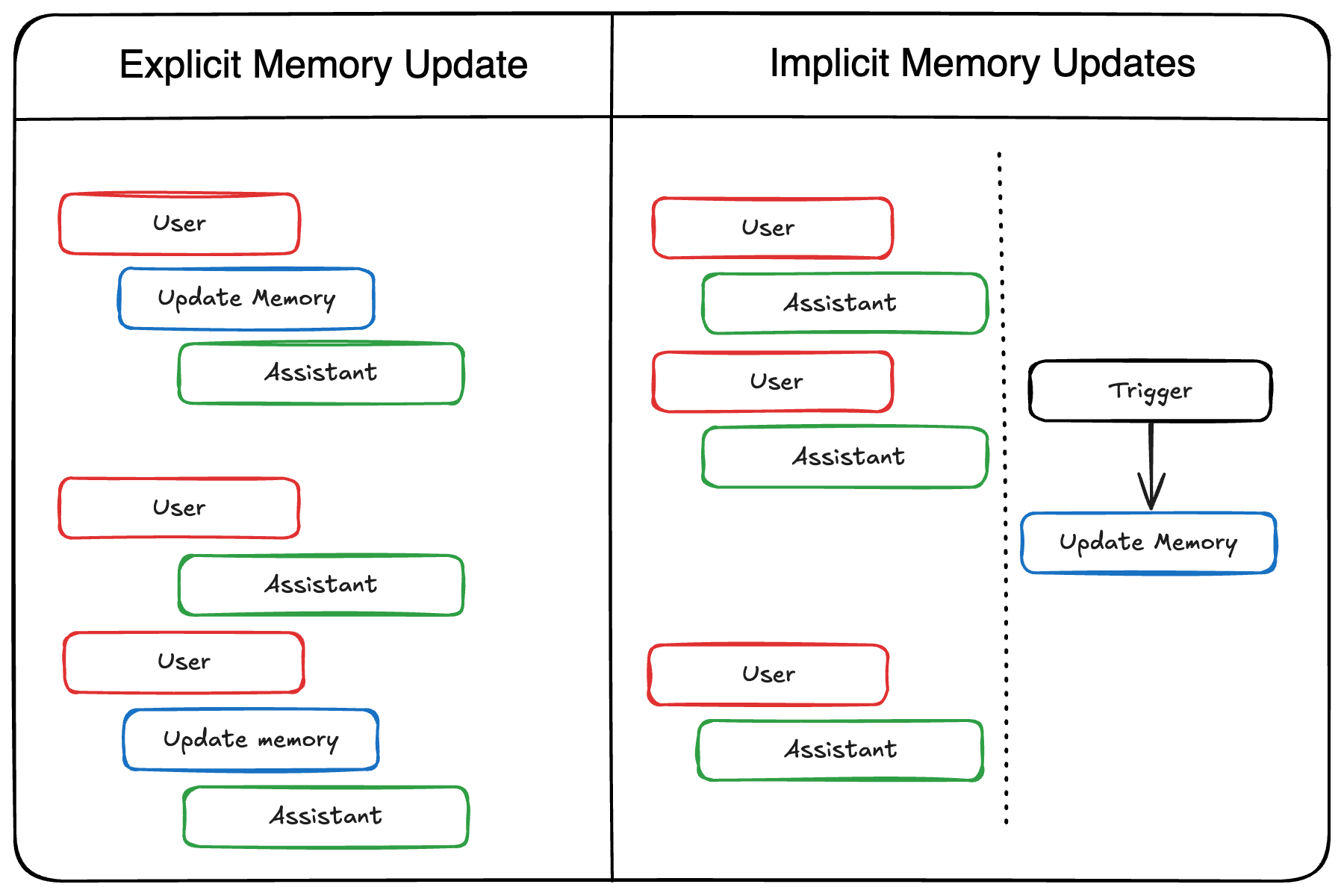
Explicit Memory Updates
The agent updates its memory as a direct part of the ongoing interaction flow, before or after responding to the user using tool use.
✅ Pros: Memory is updated in real-time and immediately available for subsequent turns; can be transparent to the user.
❌ Cons: Can add latency to responses; increases complexity by mixing memory logic with agent logic; agent juggles memory tasks with response generation.
Implicit Memory Updates
Memory updates occur as a separate, asynchronous background process. The agent responds to the user first, and a background task updates the memory later.
✅ Pros: No added latency to user-facing responses; keeps memory logic separate from core agent logic; allows the agent to focus on responding.
❌ Cons: Memory isn't updated instantly, potentially leading to outdated context for a short period; requires careful design of when and how often the background process runs.
The Memory Challenge
Implementing Memory successfully in Agents is challenging as there is no direct feedback or impact of it. Memory system will grow over time and you must find the right balance between performance, accuracy, and operational cost to solve these key problems:
- Relevance Problem: Retrieving irrelevant or outdated memories introduces noise and can degrade performance on the actual task. Achieving high precision is crucial.
- Memory Bloat: An agent that remembers everything eventually remembers nothing useful. Storing every detail leads to "bloat" making it more, expensive to search, and harder to navigate.
- Need to Forget: The value of information decays. Acting on outdated preferences or facts becomes unreliable. Designing eviction strategies to discard noise without accidentally deleting crucial, long-term context is difficult.
The challenge alone are already hard to solve but what makes it even harder is the delayed feedback loop of memory systems. The consequences of a flawed memory strategy only surface over time, making it tough to measure and iterate effectively.
Tools and The Future
There is a growing ecosystem of tools making it easier to implement Memory features. Frameworks like LangGraph, Mem0, Zep, ADK, Letta and others provide easy to use integrations for adding memory. I built a chatbot using mem0 and Google Gemini 2.5 Flash to remember user preferences.
Today's tools solve the core engineering challenges of storing and retrieving data. But for a successful future we will not just need bigger hard drive, but a smarter brain.
Acknowledgements
This overview was created with the help of deep and manual research, drawing inspiration and information from several excellent resources, including:
- Mem0: Building Production- Ready AI Agents with Scalable Long-Term Memory
- Improving User Experiences with Memory Export
- Langgraph Memory documentation
- Memory: The secret sauce of AI agents
- Build smarter AI agents: Manage short-term and long-term memory with Redis
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.