Integrating Long-Term Memory with Gemini 2.5
By default, large language models (LLMs) are stateless, which means they do not remember past conversations. This can make it difficult to create truly personal and helpful AI applications. This guide shows you how to add long-term memory to your Gemini 2.5 chatbot using the Gemini API and Mem0.
By adding a memory system, your chatbot can:
- Remember details about the user from past conversations.
- Give answers that are more relevant and personal.
- Stop asking the same questions over and over.
In this example, we will use mem0, an open-source tool for giving AI agents long-term memory and Gemini 2.5 Flash as the LLM. We will build a simple chatbot that saves what you talk about and uses that history to give you better, more personalized answers.
How does Mem0 work?
Mem0 is designed to equip AI agents with scalable long-term memory, effectively addressing the limitations of fixed context windows in LLMs. At its core, mem0 works by reactively extracting, consolidating, and retrieving salient information from ongoing conversations.
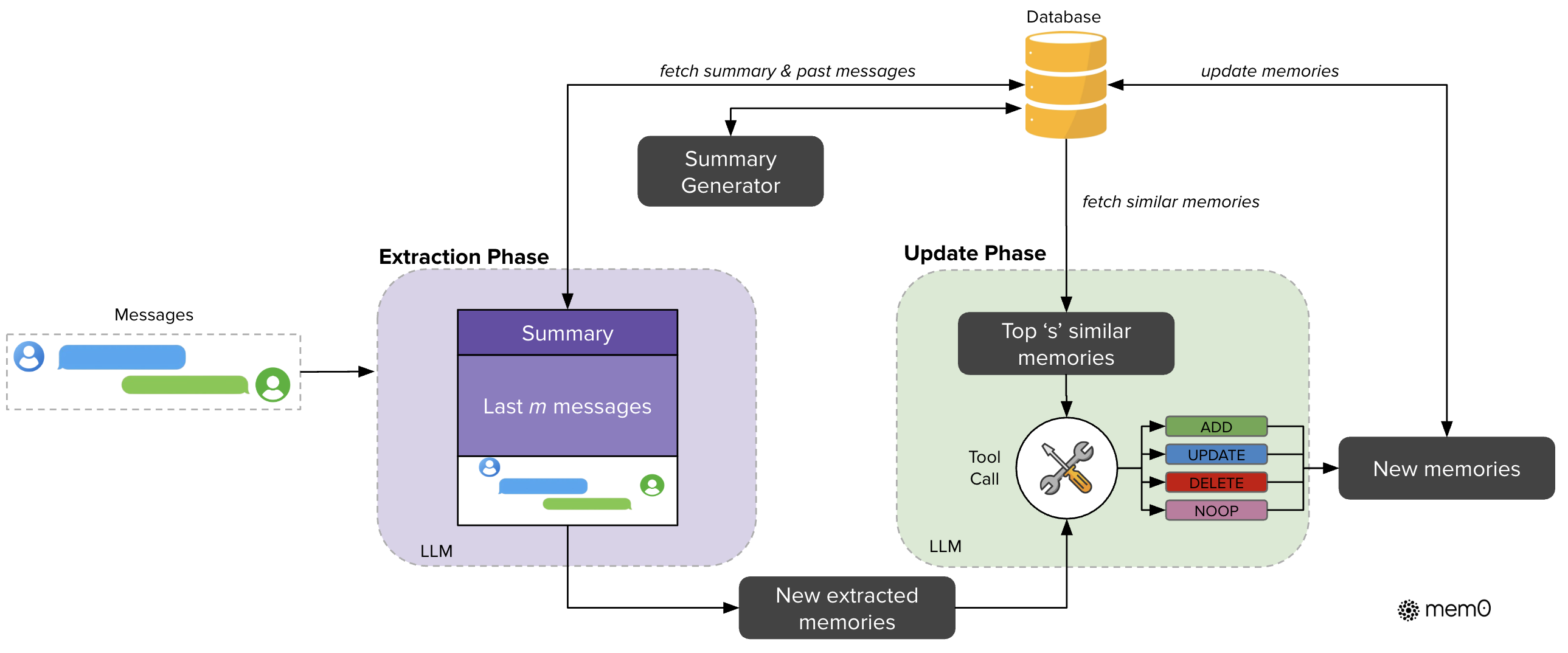
The process is split into four steps:
- Extract salient information from conversations using an LLM with dual context (a conversation summary combined with recent messages).
- Use LLM to process context and extract important new information and compares them against existing ones using semantic similarity.
- Update Memory (ADD, UPDATE, DELETE, or NOOP), for Mem0g variant (graph), extract entities and relationships.
- Use vector similarity search to fetch relevant memories for response generation.
It uses vector embeddings to store and retrieve semantic information, maintaining user-specific context across sessions, and implementing efficient retrieval mechanisms for relevant past interactions.
Setup
The first task is to install the google-genai Python SDK and mem0ai and obtain an API key.
!uv pip install google-genai mem0ai --upgradeMemory initialization
For building Memory we need to configure two main components:
- LLM: This model is responsible for processing the conversation, understanding the content, and extracting key information to be stored as memories.
- Embedding Model: This model takes the extracted text memories and converts them into numerical representations (vectors). This allows
mem0to efficiently search and retrieve relevant memories based on their meaning when you ask a question.
In this example, we will use Google's Gemini models for both tasks. We will use gemini-2.5-flash as our LLM and text-embedding-004 as our embedding model. We are going to use a local Qdrant instance as our vector store. Mem0 supports multiple vector stores incuding MongoDB, OpenSearch, Elasticsearch, Pgvector and more.
from google import genai
from mem0 import Memory
# create client
client = genai.Client()
config = {
"embedder": {
"provider": "gemini",
"config": {
"model": "models/text-embedding-004",
}
},
"llm": {
"provider": "gemini",
"config": {
"model": "gemini-2.5-flash",
"temperature": 0.0,
"max_tokens": 2000,
}
},
"vector_store": {
"config": {
"embedding_model_dims": 768,
}
}
}
memory = Memory.from_config(config)Store Memories about the user
To simulate and simplify the process of adding memory. We will use dummy conversations between me (Philipp Schmid) and Gemini based on what can be seen on my blog. Conversations need to be in the messages format to be added.
conv1 = [
{"role": "user", "content": "I'm planning a week-long vacation in early September. I want to go somewhere in Europe where I can do some serious mountain biking during the day and have a good selection of fiction and non-fiction books to read in the evenings. Any recommendations for destinations and book pairings?"},
{"role": "assistant", "content": "That sounds like a fantastic way to spend a week! Given your interest in mountain biking and reading, I'd recommend the Austrian Alps, specifically the area around Innsbruck. It's renowned for its challenging bike trails and stunning scenery. For your evenings, here are a few book pairings that might resonate with your interests:\n\n* Fiction: The Goldfinch by Donna Tartt. It's a long, immersive novel that would be perfect to get lost in after a long day of biking.\n* Non-fiction: Endurance: Shackleton's Incredible Voyage by Alfred Lansing. It's a gripping true story of survival and leadership that might appeal to your adventurous spirit.\n\nI can also look for some local bookstores in Innsbruck that might have a good selection of English and German books if you'd like."},
{"role": "user", "content": "Innsbruck is a great suggestion! I've heard the trails there are epic. I've already read Endurance, but The Goldfinch sounds intriguing. Can you tell me a bit more about the plot without giving too much away? Also, are there any good sci-fi or tech-related non-fiction books you'd recommend?"},
{"role": "assistant", "content": "Of course. The Goldfinch begins with a young boy who survives a terrorist bombing at an art museum. In the aftermath, he takes a famous painting, and the story follows his life as he navigates grief, love, and the criminal underworld, all while secretly holding onto the artwork. It's a beautifully written and complex story.\n\nFor a sci-fi recommendation, you might enjoy Project Hail Mary by Andy Weir. It's a thrilling story of a lone astronaut on a mission to save humanity, filled with clever problem-solving and scientific detail. As for tech non-fiction, given your professional background, you might find The Age of AI: And Our Human Future by Henry Kissinger, Eric Schmidt, and Daniel Huttenlocher to be a thought-provoking read. It explores the societal implications of AI from a policy and philosophical perspective."}
]
result = memory.add(conv1, user_id="philipp")
conv2 = [
{"role": "user", "content": "I want to write a new post for my blog, but I want it to be more personal this time. I was thinking of drawing parallels between my experiences with mountain climbing and the challenges of developing and deploying large language models. What do you think of that idea?"},
{"role": "assistant", "content": "That's a fantastic idea for a blog post! It's a unique angle that could really resonate with your audience. You could structure it around a few key themes:\n\n1. The Ascent as the Training Process: You could compare the long, arduous process of training a large model with the physical and mental challenges of a difficult climb. Both require immense preparation, endurance, and the ability to push through plateaus.\n2. Navigating Unseen Terrain as Dealing with Unexpected Model Behavior: Just as a climber might encounter unexpected obstacles on a route, developers often face surprising or undesirable model outputs. You could talk about the importance of having the right 'gear' (debugging tools, evaluation metrics) to navigate these challenges.\n3. Reaching the Summit as Successful Deployment: The satisfaction of reaching a summit after a hard climb can be compared to the successful deployment of a model that solves a real-world problem. You could emphasize that this is not the end, but rather a new vantage point to see the next set of challenges.\n\nHow does that structure feel to you? We could also brainstorm some catchy titles."},
{"role": "user", "content": "I love that structure! 'The Ascent as the Training Process' is a particularly strong analogy. For a title, I was thinking of something like 'Climbing the AI Mountain' or 'Lessons from the Summit: AI and the Art of the Climb.' What do you think?"},
{"role": "assistant", "content": "Both are great titles! 'Lessons from the Summit: AI and the Art of the Climb' is particularly evocative and captures the reflective and personal tone you're aiming for. It suggests that you'll be sharing hard-won insights. You could even open the blog post with a short, vivid anecdote from one of your climbs to immediately draw the reader in."}
]
result = memory.add(conv2, user_id="philipp")
conv3 = [
{"role": "user", "content": "I'm preparing a talk for an upcoming AI conference. The topic is 'The Future of Agentic AI in the Enterprise'. I want to cover the current landscape, key challenges, and a forward-looking perspective. Can you help me brainstorm a compelling narrative and structure for the talk?"},
{"role": "assistant", "content": "That sounds like a fascinating topic! Here's a possible structure for your talk to create a strong narrative arc:\n\n1. The 'Why' Now: Start with a powerful hook. Perhaps a real-world example of a complex business problem that agentic AI can solve today. This sets the stage and grabs the audience's attention.\n2. The Landscape of Agentic AI: Briefly cover the foundational concepts – what makes an AI 'agentic'? Mention key frameworks and models that are driving this space. Given your background, you could draw comparisons between different approaches.\n3. The 'How': Architecting for Success: This is where you can dive into the technical meat. Discuss design patterns for building robust and scalable agentic systems. You could touch upon topics like memory, tool use, and multi-agent collaboration.\n4. The Hurdles to Overcome: Address the challenges head-on. This will make your talk more balanced and credible. Think about issues like reliability, security, and the 'black box' problem.\n5. The Future, Today: Paint a picture of the near-future possibilities. What are the next big breakthroughs we can expect? You could end with a call to action for developers to start building and experimenting with agentic AI.\n\nHow does that sound as a starting point?"},
{"role": "user", "content": "This is a great starting point, thank you! I especially like the idea of starting with a strong 'Why Now'. For the 'Hurdles' section, I'm thinking of focusing on the challenges of evaluation and ensuring responsible AI development in agentic systems. Can you suggest some recent research papers or articles on evaluating agentic AI systems that I could reference?"},
{"role": "assistant", "content": "Excellent addition. Focusing on evaluation and responsible AI is crucial. Here are a few highly-cited papers on evaluating agentic AI that you could explore:\n\n* 'A Survey on Evaluation of Large Language Models': While not exclusively on agents, it provides a comprehensive overview of evaluation metrics that are highly relevant.\n* 'AgentBench: Evaluating LLMs as Agents': This paper introduces a benchmark specifically designed for evaluating LLMs as agents across a variety of tasks.\n* 'On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜': A foundational paper on the ethical considerations of large language models, which is very relevant to responsible AI in agentic systems.\n\nI can also help you find more specific papers if you have a particular aspect of evaluation in mind."},
{"role": "user", "content": "Perfect, this is exactly what I was looking for. I'll start with these and let you know if I need more."}
]
result = memory.add(conv3, user_id="philipp")We can manually search throught the memory to find relevant information. Let's try to find information about me.
related_memories = memory.search(query="What do you know about me?", user_id="philipp")
# Print the first 3 memories
for m in related_memories["results"][:3]:
print(m["memory"])
# Has a professional background
# Blog post will be personal
# Wants to write a new blog postGreat! Now let's do some test on how including memory into our conversation changes the output. Our memmory should now include that Philipp is going to give a talk about agentic AI in the enterprise and some context about my hobbies. P.S. I prefer weightlifting over mountain biking.
Let see what Gemini will do when we ask it to help brainstorm about the upcoming talk.
system_prompt = "You are a helpful AI Assistant."
prompt = "Can you help me brainstorm a title and a key visual for my upcoming conference talk on 'The Future of Agentic AI in the Enterprise'? I'd like it to subtly connect to my personal interests in a way that feels authentic."
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config={
"system_instruction": system_prompt
}
)
print(response.text)
# This is a fantastic request! .... Once you give me some input, we can refine the titles and visuals even further!As expected, Gemini has no idea about the upcoming talk and my interests. Now lets add the memory to the conversation.
# retrieve memories
helpful_memories = memory.search(query=prompt, user_id="philipp")
memories_str = "\n".join(f"- {entry['memory']}" for entry in helpful_memories["results"])
# extend system prompt
extended_system_prompt = f"You are a helpful AI Assistant. You have the following memories about the user:\n{helpful_memories}"
# generate response
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config={
"system_instruction": extended_system_prompt
}
)
print(response.text)
# This is a great idea ... Here are a few options ... Both options allow you to subtly connect to your interests in mountain climbingAwesome! Instead of needing to follow up with the user, Gemini generated two respones based on the memories, including the user's personal interests.
Long-term memory Chatbot with Gemini 2.5
Now, lets combine all of this into an interactive chatbot. We separate the chatbot into two notebook cells, that we chat with Gemini, stop and start the chatbot again, but it has all the memories from the previous chat.
from google import genai
from mem0 import Memory
client = genai.Client()
config = {
"embedder": {"provider": "gemini", "config": {"model": "models/text-embedding-004"}},
"llm": {"provider": "gemini", "config": {"model": "gemini-2.5-flash", "temperature": 0.0, "max_tokens": 2000}},
"vector_store": {"config": {"embedding_model_dims": 768}}
}
memory = Memory.from_config(config)
system_prompt = "You are a helpful AI. Answer the question based on query and memories."An example to test is you can start with saying something about you and where you are, e.g. "I am live in Nuremberg and today we have 30°C, how can i cool down?". Then stop (type 'exit'), restart (rerun the cell) the conversation and ask about "what the closest swimming pool is".
def chat_with_memories(history: list[dict], user_id: str = "default_user") -> str:
# Retrieve relevant memories
print(history[-1]["parts"][0]["text"])
relevant_memories = memory.search(query=history[-1]["parts"][0]["text"], user_id=user_id, limit=5)
memories_str = "\n".join(f"- {entry['memory']}" for entry in relevant_memories["results"])
# Generate Assistant response
memory_system_prompt = f"{system_prompt}\nUser Memories:\n{memories_str}"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=history,
config={"system_instruction": memory_system_prompt}
)
history.append({"role": "model", "parts": [{"text": response.text}]})
# Create new memories from the conversation we need to convert the history to a list of messages
messages = [{"role": "user" if i % 2 == 0 else "assistant", "content": part["parts"][0]["text"]} for i, part in enumerate(history)]
memory.add(messages, user_id=user_id)
return history
def main():
print("Chat with Gemini (type 'exit' to quit)")
history = []
while True:
user_input = input("You: ").strip()
if user_input.lower() == 'exit':
print("Goodbye!")
break
history.append({"role": "user", "parts": [{"text": user_input}]})
response = chat_with_memories(history)
print(f"Gemini: {response[-1]['parts'][0]['text']}")
main()Conclusion
We've seen how to overcome the stateless nature of LLMs by integrating long-term memory into a Gemini 2.5. By storing and retrieving information from past conversations, we can build AI assistants that are more personal, context-aware, and genuinely helpful. This allows them to remember user preferences, build on previous interactions, and provide a much richer and more natural conversational experience.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.