Deep Learning setup made easy with EC2 Remote Runner and Habana Gaudi
Going from experimenting and preparation in a local environment to managed cloud infrastructure is often times too complex and prevents data scientists from iterating quickly and efficiently on their Deep Learning projects and work.
A common workflow I see is that a DS/MLE starts virtual machines in the cloud, ssh into the machine, and does all of the experiments there. This has at least two downsides.
- Requires a lot of work and experience to start those cloud-based instances (selecting the right environment, CUDA version…), which can lead to bad developer experiences and some unpreventable situations like forgetting to stop an instance.
- The compute resources might not be efficiently used. In Deep Learning you use most of the time GPU-backed instances, which can cost up to 40$/h. But since not all operations require a GPU, such as dataset preparation or tokenization (in NLP) a lot of money can be wasted.
Two overcome that downside we create a small package called “Remote Runner”.
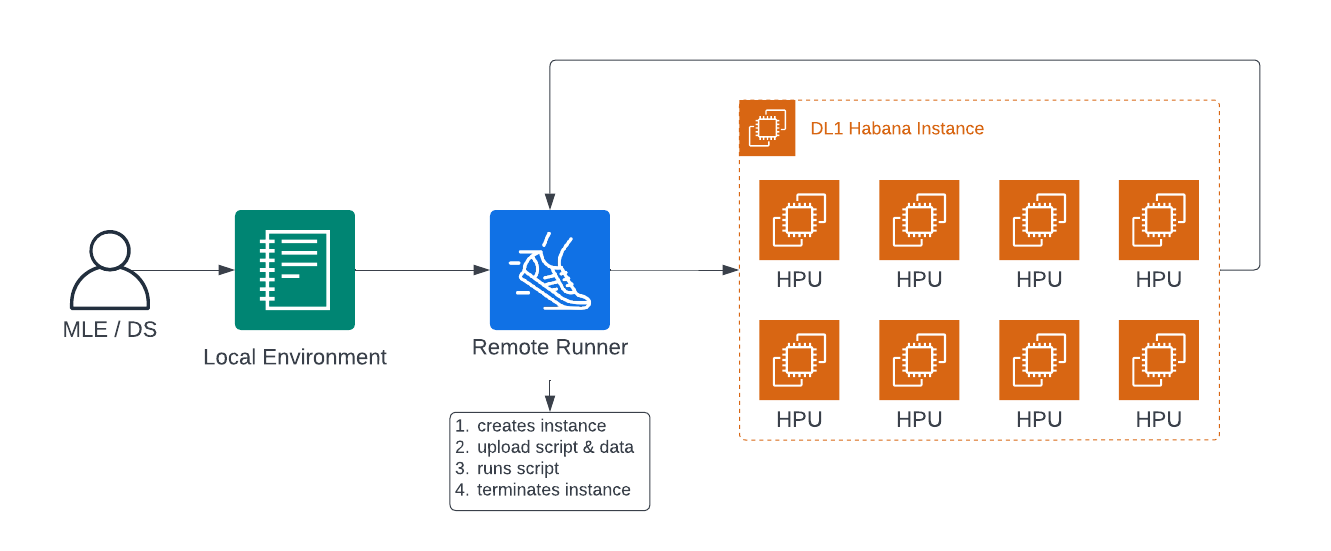
Remote Runner is an easy pythonic way to migrate your python training scripts from a local environment to a powerful cloud-backed instance to efficiently scale your training, save cost & time, and iterate quickly on experiments in a parallel containerized way.
How does Remote Runner work?
Remote Runner takes care of all of the heavy liftings for you:
- Creating all required cloud resources
- Migrating your script to the remote machine
- Executing your script
- Making sure the instance is terminated again.
Let's give it a try. 🚀
Our goal for the example is to fine-tune a Hugging Face Transformer model using the Habana Gaudi-based DL1 instance on AWS to take advantage of the cost performance benefits of Gaudi.
Managed Deep Learning with Habana Gaudi
In this example, you learn how to migrate your training jobs to a Habana Gaudi-based DL1 instance on AWS. Habana Gaudi is a new deep learning training processor for cost-effective, high-performance training promising up to 40% better price-performance than comparable GPUs, which is available on AWS.
We created the past already a blog post on how to Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS, which I recommend you take a look to understand how much “manual” work was needed to use the DL1 instances on AWS for your workflows.
In the following example we will cover the:
and then
1. Requirements & Setup
Before we can start make sure you have met the following requirements
- AWS Account with quota for DL1 instance type
- AWS IAM user configured in CLI with permission to create and manage EC2 instances. You can find all permissions needed here.
After all, requirements are fulfilled we can begin by installing Remote-Runner and the Hugging Face Hub library. We will use the Hugging Face Hub as the model versioning backend. This allows us to checkpointing, log and track our metrics during training, but simply provide one API token.
pip install rm-runner huggingface_hub2. Run a text-classification training job on Habana Gaudi DL1
We will use an example from the Remote Runner repository. The example will fine-tune a DistilBERT model on the IMDB dataset.
Note: Check out the Remote Runner repository it includes several different examples
As first we need to clone the repository and change the directory into examples
git clone https://github.com/philschmid/deep-learning-remote-runner.git && cd deep-learning-remote-runner/examplesThe habana_text_classification.py script uses the new GaudiTrainer from optimum-habana to leverage Habana Gaudi and provides an interface identical to the transformers Trainer.
As next, we can adjust the hyperparameters in the habana_example.py.
from rm_runner import EC2RemoteRunner
from huggingface_hub import HfFolder
# hyperparameters
hyperparameters = {
"model_id": "distilbert-base-uncased",
"dataset_id": "imdb",
"save_repository_id": "distilbert-imdb-remote-runner",
"hf_hub_token": HfFolder.get_token(), # need to be login in with `huggingface-cli login`
"num_train_epochs": 3,
"per_device_train_batch_size": 64,
"per_device_eval_batch_size": 32,
}
hyperparameters_string = " ".join(f"--{key} {value}" for key, value in hyperparameters.items())
You can for example change the model_id to your preferred checkpoint from Hugging Face. The next step is to create our EC2RemoteRunner instance. The EC2RemoteRunner defines our cloud environment including the instance_type, region, and which credentials we want to use. You can also define a custom container, which should be used to execute your training, e.g. if you want to include additional dependencies.
the default container for Habana is the huggingface/optimum-habana:latest one.
We are going to use the dl1.24xlarge instance in us-east-1. For profile enter you configured profile.
# create ec2 remote runner
runner = EC2RemoteRunner(
instance_type="dl1.24xlarge",
profile="hf-sm",
region="us-east-1"
)As next, we need to define the “launch” arguments which are the executecommand and source_dir (will be uploaded via SCP).
# launch my script with gaudi_spawn for distributed training
runner.launch(
command=f"python3 gaudi_spawn.py --use_mpi --world_size=8 habana_text_classification.py {hyperparameters_string}",
source_dir="scripts",
)Now we can launch our remote training by executing our python file.
python habana_example.pyYou should see a similar output to the one below.
2022-07-25 08:36:39,505 | INFO | Found credentials in shared credentials file: ~/.aws/credentials
2022-07-25 08:36:46,883 | INFO | Created key pair: rm-runner-agld
2022-07-25 08:36:47,778 | INFO | Created security group: rm-runner-agld
2022-07-25 08:36:49,244 | INFO | Launched instance: i-087d5654841eb09e8
2022-07-25 08:36:49,247 | INFO | Waiting for instance to be ready...
2022-07-25 08:37:05,307 | INFO | Instance is ready. Public DNS: ec2-3-84-58-86.compute-1.amazonaws.com
2022-07-25 08:37:05,334 | INFO | Setting up ssh connection...
2022-07-25 08:38:25,360 | INFO | Setting up ssh connection...
2022-07-25 08:38:49,480 | INFO | Setting up ssh connection...
2022-07-25 08:38:49,694 | INFO | Connected (version 2.0, client OpenSSH_8.2p1)
2022-07-25 08:38:50,711 | INFO | Authentication (publickey) successful!
2022-07-25 08:38:50,711 | INFO | Pulling container: huggingface/optimum-habana:latest...Remote Runner will log all steps it takes to launch your training as well as all of the outputs during the training to the terminal. At the end of the training, you'll see a summary of your training job with the duration each step took and an estimated cost.
2022-07-25 10:22:38,851 | INFO | Terminating instance: i-091459df0356ae68b
2022-07-25 10:24:41,764 | INFO | Deleting security group: rm-runner-mjcf
2022-07-25 10:24:43,093 | INFO | Deleting key: rm-runner-mjcf
2022-07-25 10:24:44,055 | INFO | Total time: 594s
2022-07-25 10:24:44,055 | INFO | Startup time: 174s
2022-07-25 10:24:44,056 | INFO | Execution time: 296s
2022-07-25 10:24:44,056 | INFO | Termination time: 124s
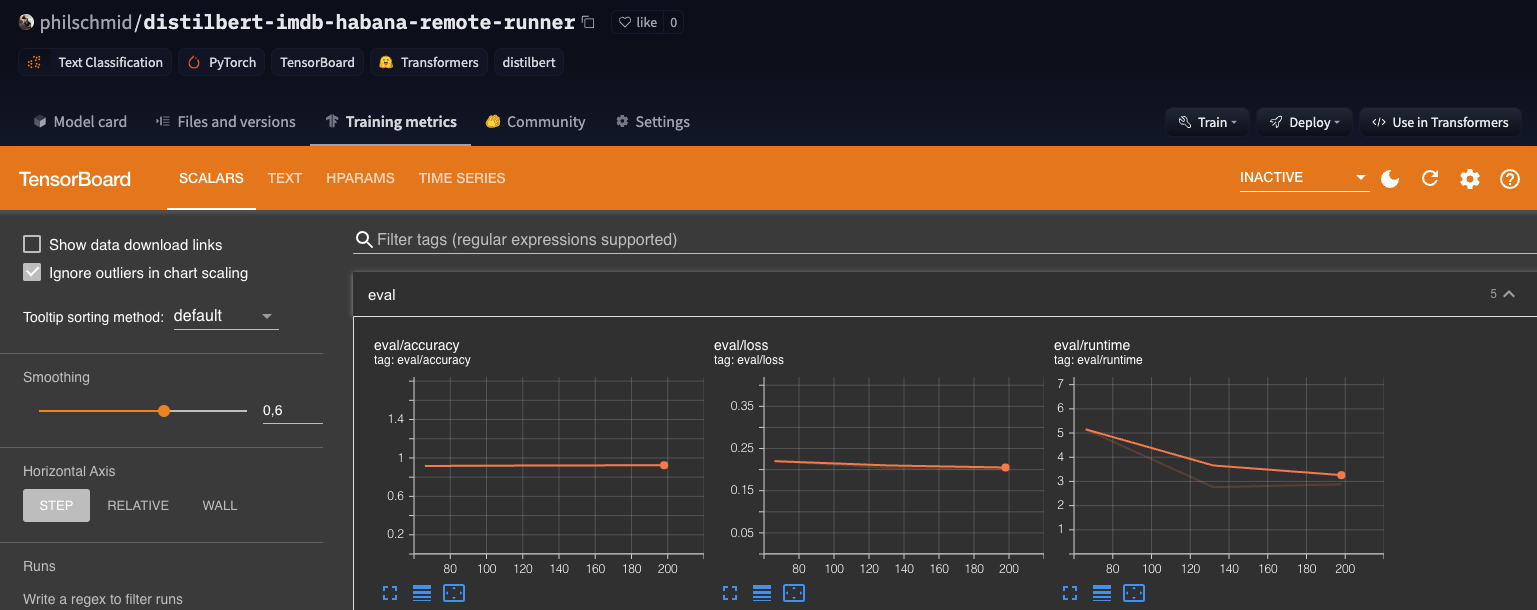
2022-07-25 10:24:44,056 | INFO | Estimated cost: $1.71We can see that our training finished successfully and took in a total of 594s and cost $1.71 due to the use of Habana Gaudi.
We can now check the results and the model on the Hugging Face Hub. For me it is philschmid/distilbert-imdb-habana-remote-runner
Conclusion
Remote Runner helps you to easily migrate your training to the cloud and to experiment fast on different instance types.
With the support for custom deep learning chips, it makes it easy to migrate from more expensive and slower instances to faster more optimized ones, e.g. Habana Gaudi DL1. If you are interested in why you should migrate GPU workload to Habana Gaudi checkout: Hugging Face Transformers and Habana Gaudi AWS DL1 Instances
If you run into an issue with Remote Runner or have feature requests don't hesitate to open an issue on Github.
Also, make sure to check out the optimum-habana repository.
Thanks for reading! If you have any questions, feel free to contact me, through Github, or on the forum. You can also connect with me on Twitter or LinkedIn.