Deploy T5 11B for inference for less than $500
This blog will teach you how to deploy T5 11B for inference using Hugging Face Inference Endpoints. The T5 model was presented in Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer paper and is one of the most used and known Transformer models today.
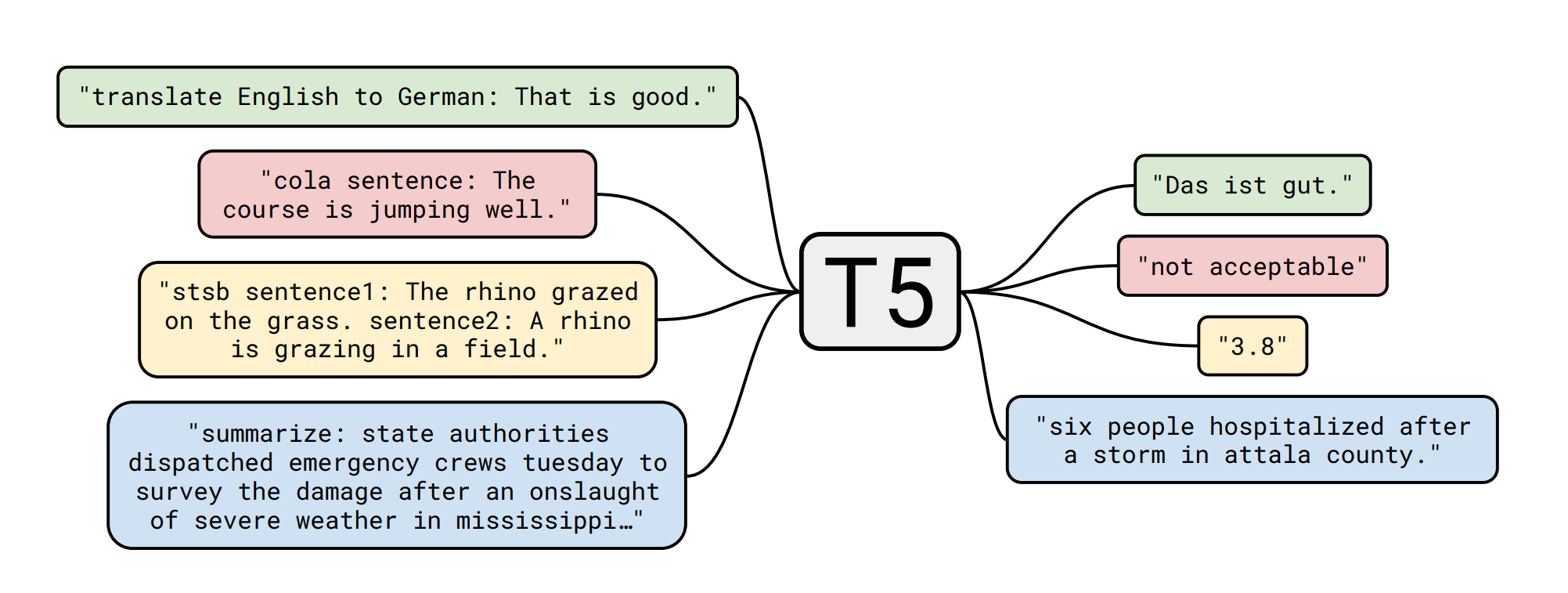
T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and for which each task is converted into a text-to-text format. T5 works well on various tasks out-of-the-box by prepending a different prefix to the input corresponding to each task, e.g., for translation: translate English to German: …, for summarization: summarize: ...
Before we can get started, make sure you meet all of the following requirements:
- An Organization/User with an active plan and WRITE access to the model repository.
- You can access the UI: https://ui.endpoints.huggingface.co
The Tutorial will cover how to:
- Prepare model repository, custom handler, and additional dependencies
- Deploy the custom handler as an Inference Endpoint
- Send HTTP request using Python
What is Hugging Face Inference Endpoints?
🤗 Inference Endpoints offers a secure production solution to easily deploy Machine Learning models on dedicated and autoscaling infrastructure managed by Hugging Face.
A Hugging Face Inference Endpoint is built from a Hugging Face Model Repository. It supports all the Transformers and Sentence-Transformers tasks and any arbitrary ML Framework through easy customization by adding a custom inference handler. This custom inference handler can be used to implement simple inference pipelines for ML Frameworks like Keras, Tensorflow, and scit-kit learn or can be used to add custom business logic to your existing transformers pipeline.
Tutorial: Deploy T5-11B on a single NVIDIA T4
In this tutorial, you will learn how to deploy T5 11B for inference using Hugging Face Inference Endpoints and how you can integrate it via an API into your products.
1. Prepare model repository, custom handler, and additional dependencies
T5 11B is, with 11 billion parameters of the largest openly available Transformer models. The weights in float32 are 45.2GB and are normally too big to deploy on an NVIDIA T4 with 16GB of GPU memory.
To be able to fit T5-11b into a single GPU, we are going to use two techniques:
- mixed precision and sharding: Converting the weights to fp16 will reduce the memory footprint by 2x, and sharding will allow us to easily place each “shard” on a GPU without the need to load the model into CPU memory first.
- LLM.int8(): introduces a new quantization technique for Int8 matrix multiplication, which cuts the memory needed for inference by half while. To learn more about check out this blog post or the paper.
We already prepared a repository with sharded fp16 weights of T5-11B on the Hugging Face Hub at: philschmid/t5-11b-sharded. Those weights were created using the following snippet.
Note: If you want to convert the weights yourself, e.g. to deploy google/flan-t5-xxl you need at least 80GB of memory.
import torch
from transformers import AutoModelWithLMHead
from huggingface_hub import HfApi
# load model as float16
model = AutoModelWithLMHead.from_pretrained("t5-11b", torch_dtype=torch.float16, low_cpu_mem_usage=True)
# shard model an push to hub
model.save_pretrained("sharded", max_shard_size="2000MB")
# push to hub
api = HfApi()
api.upload_folder(
folder_path="sharded",
repo_id="philschmid/t5-11b-sharded-fp16",
)After we have our sharded fp16 model weights, we can prepare the additional dependencies we will need to use the **LLM.int8().** LLM.int8() has been natively integrated into transformers through bitsandbytes.
To add custom dependencies, we need to add a requirements.txt file to your model repository on the Hugging Face Hub with the Python dependencies you want to install.
accelerate==0.13.2
bitsandbytesThe last step before creating our Inference Endpoint is to create a custom Inference Handler. If you want to learn how to create a custom Handler for Inference Endpoints, you can either checkout the documentation or go through “Custom Inference with Hugging Face Inference Endpoints”.
from typing import Dict, List, Any
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
class EndpointHandler:
def __init__(self, path=""):
# load model and processor from path
self.model = AutoModelForSeq2SeqLM.from_pretrained(path, device_map="auto", load_in_8bit=True)
self.tokenizer = AutoTokenizer.from_pretrained(path)
def __call__(self, data: Dict[str, Any]) -> Dict[str, str]:
"""
Args:
data (:obj:):
includes the deserialized image file as PIL.Image
"""
# process input
inputs = data.pop("inputs", data)
parameters = data.pop("parameters", None)
# preprocess
input_ids = self.tokenizer(inputs, return_tensors="pt").input_ids
# pass inputs with all kwargs in data
if parameters is not None:
outputs = self.model.generate(input_ids, **parameters)
else:
outputs = self.model.generate(input_ids)
# postprocess the prediction
prediction = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return [{"generated_text": prediction}]2. Deploy the custom handler as an Inference Endpoint
UI: https://ui.endpoints.huggingface.co/
Since we prepared our model weights, dependencies and custom handler we can now deploy our model as an Inference Endpoint. We can deploy our custom Custom Handler the same way as a regular Inference Endpoint.

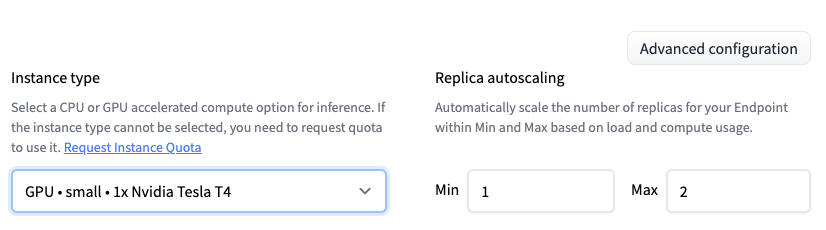
Select the repository, the cloud, and the region. After that we need to open the “Advanced Settings” to select GPU • small • 1x NIVIDA Tesla T4 .
Note: If you are trying to deploy the model on CPU the creation will fail
The Inference Endpoint Service will check during the creation of your Endpoint if there is a handler.py available and will use it for serving requests no matter which “Task” you select.
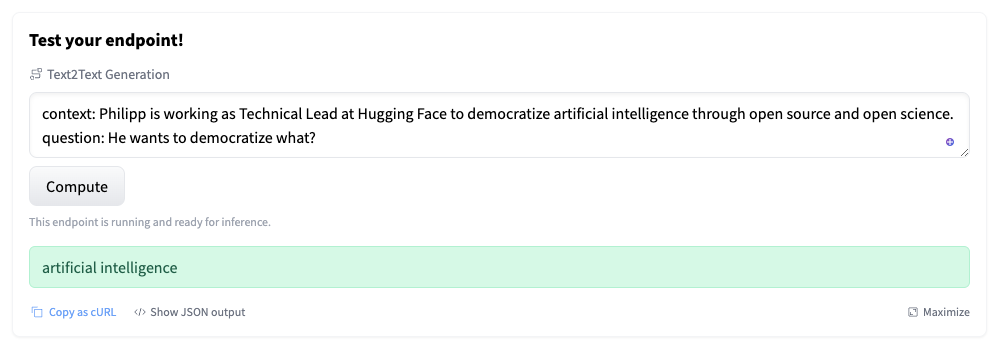
The deployment can take 20-40 minutes due to the image artifact's model size (~30GB) build. After deploying our endpoint, we can test it using the inference widget.
3. Send HTTP request using Python
Hugging Face Inference endpoints can be used with an HTTP client in any language. We will use Python and the requests library to send our requests. (make your you have it installed pip install requests)
import json
import requests as r
ENDPOINT_URL=""# url of your endpoint
HF_TOKEN=""
# payload samples
regular_payload = { "inputs": "translate English to German: The weather is nice today." }
parameter_payload = {
"inputs": "translate English to German: Hello my name is Philipp and I am a Technical Leader at Hugging Face",
"parameters" : {
"max_length": 40,
}
}
# HTTP headers for authorization
headers= {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": "application/json"
}
# send request
response = r.post(ENDPOINT_URL, headers=headers, json=paramter_payload)
generated_text = response.json()
print(generated_text)Conclusion
That's it we successfully deploy our T5-11b to Hugging Face Inference Endpoints for less than $500.
To underline this again, we deployed one of the biggest available transformers in a managed, secure, scalable inference endpoint. This will allow Data scientists and Machine Learning Engineers to focus on R&D, improving the model rather than fiddling with MLOps topics.
Now, it's your turn! Sign up and create your custom handler within a few minutes!
Thanks for reading! If you have any questions, feel free to contact me, through Github, or on the forum. You can also connect with me on Twitter or LinkedIn.