Why (Senior) Engineers Struggle to Build AI Agents
For the past few decades, Engineering meant one thing: removing ambiguity. It meant defining strict interfaces, enforcing type safety, and ensuring that Input A \+ Code B \= Output C.
Traditional software engineering is Deterministic. We play the role of Traffic Controllers; we own the roads, the lights, and the laws. We decide exactly where data goes and when. Agent Engineering is Probabilistic. We are Dispatchers. We give instructions to a driver (an LLM) who might take a shortcut, get lost, or decide to drive on the sidewalk because it "seemed faster."
It is a paradox that junior engineers often ship functional agents faster than seniors. Why? The more senior the engineer, the less they tend to trust the reasoning and instruction-following capabilities of the Agent. We fight the model and try to "code away" the probabilistic nature.
Here are 5 examples where traditional engineering habits clash with the new reality of Agent Engineering.
1. Text is the New State
In traditional engineering, we model the world with data structures. We define schemas, interfaces, and strict types. It feels safe because it is predictable. We instinctively try to force Agents into this box.
The Trap: Real-world intents, preferences, or configurations are rarely binary/structured. User inputs are continuous (natural language) rather than discrete (structured fields).
Text is the new State. We must abandon the comfort of booleans in favor of semantic meaning.
Imagine a Deep Research plan approval use case where the user says, "This plan looks good, but please focus on the US market." A deterministic system forces this into is_approved: true/false and we lobotomize the context.
Software Engineering:
{
"plan_id": "123",
"status": "APPROVED" // Nuance is lost here
}Agent Engineering:
{
"plan_id": "123",
"text": "This plan looks good, but please focus on the US market."
}By preserving the text, the downstream agent can read the feedback ("Approved, but focus on US market") and adjust its behavior dynamically.
Another example is user preferences. A deterministic system might store is_celsius: true. An agentic system stores "I prefer Celsius for weather, but use Fahrenheit for cooking". The agent can dynamically switch contexts based on the task.
2. Hand over Control
In microservices, a user's intent matches a route (POST /subscription/cancel). In Agents, we have a single natural language entrypoint with a Brain (LLM) that decides the control flow based on the available tools, input, and instructions.
The Trap: We try to hard-code the flow into the agent, but interactions don't follow straight lines. They loop, they backtrack, and they pivot. A user might want to cancel, and end up agreeing to renew.
- User: "I want to cancel my subscription." (Intent: Churn)
- Agent: "I can offer you a 50% discount to stay."
- User: "Actually, yeah, that works." (Intent: Retention)
Trust the agent to navigate the flow. If we try to hard-code every edge case, we aren't building an AI agent. We must trust the agent to understand the current intent based on the entire context.
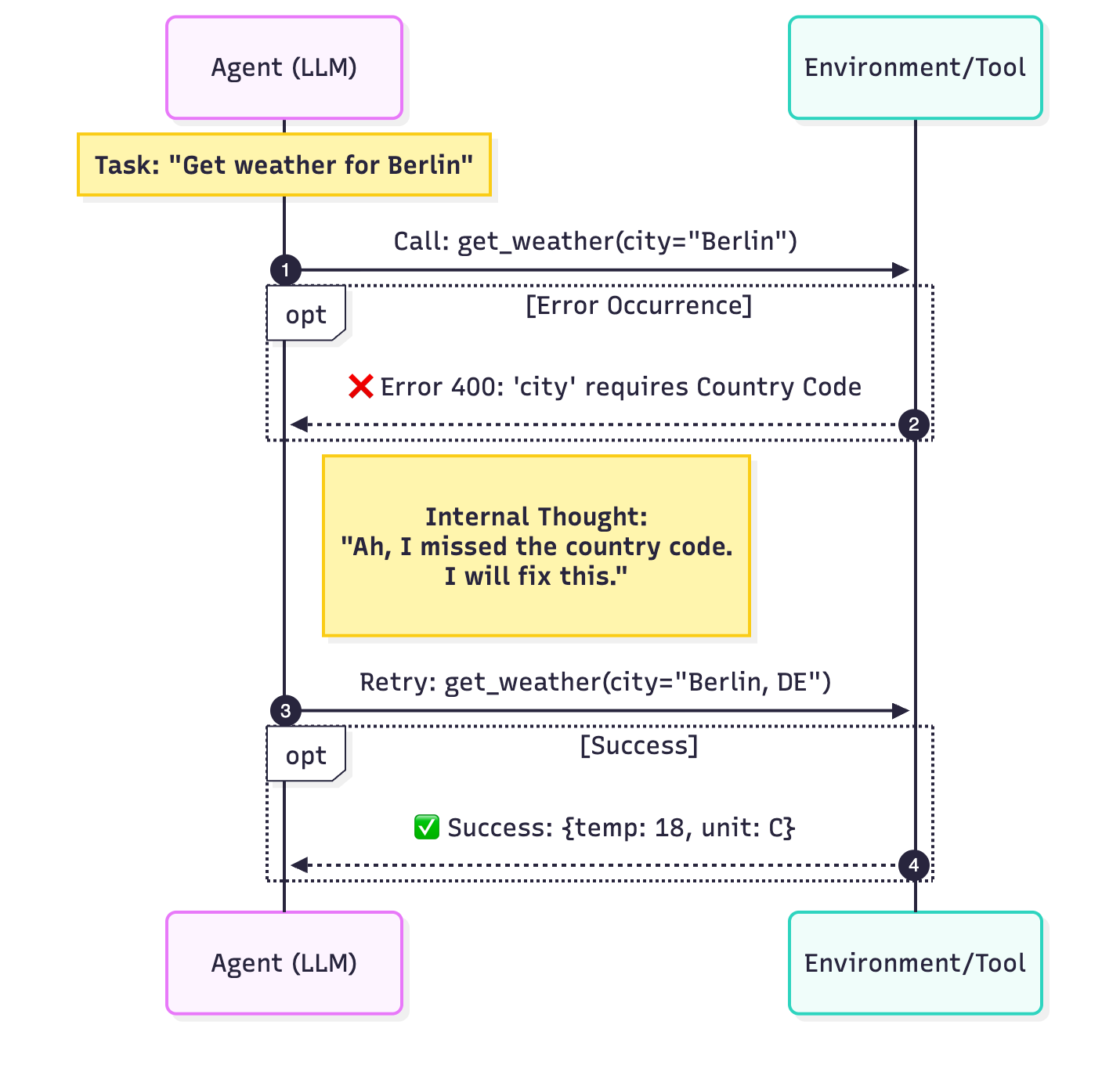
3. Errors are just inputs
In traditional software, if an API call fails or a variable is missing, we throw an exception. We want the program to crash immediately so we can fix the bug.
The Trap: An agent might take 5 minutes and cost $0.50. If step 4 of 5 fails because of a missing or wrong input, crashing the whole execution is unacceptable.
An error is just another input. Instead of crashing, we catch the error, feed it back to the agent, and try to recover.
4. From Unit Tests to Evals
Test Driven Development (TDD) helps us write more robust code, but we cannot unit test an Agent. Engineers can waste weeks looking for binary correctness in a probabilistic system. We must evaluate behavior.
The Trap: We cannot write binary assertions for creative or reasoning tasks. "Write a summary of this email" has infinite valid outputs. If we try to Mock the LLM, we aren't testing the agent, we are testing our string concatenation.
Evals over Tests. We cannot unit test reasoning. We must validate Reliability and Quality, and trace intermediate checks:
- Reliability (Pass^k): We don't ask "Did it work?" We ask "How often does it work?"
- Quality (LLM as a Judge): "Is the answer helpful? Is the tone correct? Is the summary accurate?"
- Tracing: Don't just check the final answer. Check the intermediate steps. Did the agent search the knowledge base before answering?
If our agent succeeds 45/50 times with a quality score of 4.5/5, it can be production-ready. We are managing risk, not eliminating variance.
5. Agents Evolve, APIs Don't
In the past, we designed APIs for human developers, relying on implicit context and "clean" interfaces. Humans infer context. Agents do not. Agents are Literalists. If an ID format is ambiguous, the agent will hallucinate one.
The Trap: We often build "Human-Grade" APIs—endpoints that rely on implicit context. For example, a variable named id is obviously the user_unique_identifier (UUID) to us, and can be used in get_user(id). An Agent might not have this context and might try to use the email or name in get_user(id).
Agents require verbose, "Idiot-Proof" semantic typing (e.g., "user_email_address" instead of "email") and highly descriptive docstrings that act as "context".
- Bad:
delete_item(id)(Is ID an integer? A UUID? What happens if it's not found?) - Good:
delete_item_by_uuid(uuid: str)with a docstring/description: "Deletes an item. If the item is not found, return a descriptive error string."
Furthermore, Agents allow for Just-in-Time adaptation. Normal APIs are promises to developers; we commit code that relies on those APIs, and then walk away. If we change an API from get_user_by_id(id) to get_user_by_email(email), we break that promise and everything breaks immediately. An agent, however, reads the new tool definition and can adjust to it.
Conclusion: Trust, but Verify
The transition from deterministic systems to probabilistic agents is uncomfortable. It requires us to trade certainty for semantic flexibility. We no longer know and own the exact execution path. We effectively hand over the control flow to a non-deterministic model and store our application state in natural language.
This feels wrong to a mind trained on strict interfaces. But trying to force an Agent into a deterministic box defeats the purpose of using one. You cannot code away the probability. You must manage it through evals and self-correction.
However, "trusting" an agent does not mean letting it run wild. We must find the middle ground. Agents will fail in many unexpected ways but the trajectory is clear. We must stop trying to code away the ambiguity and start engineering systems that are resilient enough to handle it.
This also means knowing when to use workflows over agents. I go into detail on how to architect these differences in my post on Agentic Patterns.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.