Managed Transcription with OpenAI Whisper and Hugging Face Inference Endpoints
In September, OpenAI announced and released Whisper, an automatic speech recognition (ASR) system trained on 680,000 hours of audio. Whisper achieved state-of-art performance and changed the status quo of speech recognition and transcription from one to the other day.
Whisper is a Seq2Seq Transformer model trained for speech recognition (transcription) and translation, allowing it to transcribe audio to text in the same language but also allowing it to transcribe/translate the audio from one language into the text of another language. OpenAI released 10 model checkpoints from a tiny (39M) to a large (1.5B) version of Whisper.
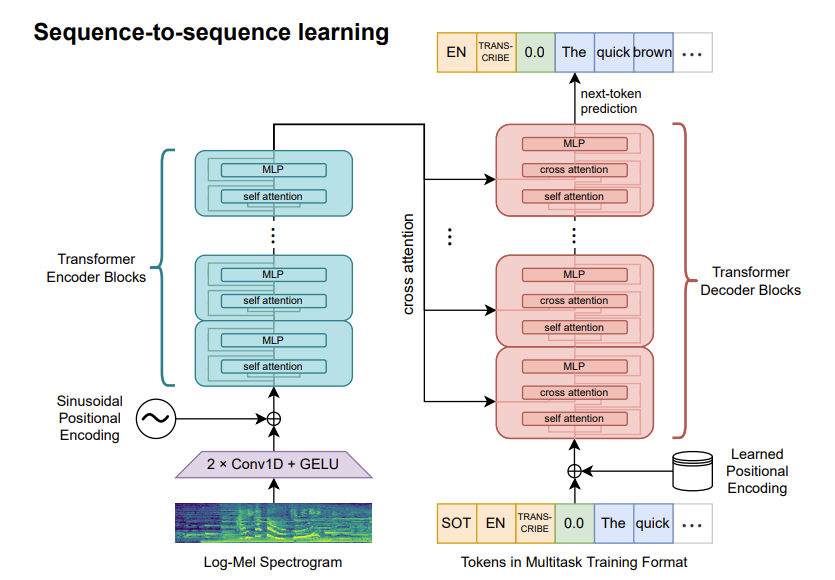
- Paper: https://cdn.openai.com/papers/whisper.pdf
- Official repo: https://github.com/openai/whisper/tree/main
Whisper large-v2 achieves state-of-art performance on the Fleurs dataset from Google on Speech Recognition (ASR), including a WER of 4.2 for English. You can find the detailed results in the paper.
Now, we know how awesome Whisper for speech recognition is, but how can I deploy it and use it to add transcription capabilities to my applications and workflows?
Moving machine learning models, especially transformers, from a notebook environment to a production environment is challenging. Do you need to consider security, scaling, monitoring, CI/CD …. which is a lot of effort when building it from scratch and by yourself.
That is why we have built Hugging Face inference endpoints, our managed inference service to easily deploy Transformers, Diffusers, or any model on dedicated, fully managed infrastructure. Keep your costs low with our secure, compliant, and flexible production solution.
Deploy Whisper as Inference Endpoint
In this blog post, we will show you how to deploy OpenAI Whisper with Hugging Face Inference Endpoints for scalable, secure, and efficient speech transcription API.
The tutorial will cover how to:
- Create an Inference Endpoint with
openai/whisper-large-v2 - Integrate the Whisper endpoint into applications using Python and Javascript
- Cost-performance comparison between Inference Endpoints and Amazon Transcribe and Google Cloud Speech-to-text
Before we can get started, make sure you meet all of the following requirements:
- An Organization/User with an active credit card. (Add billing here)
- You can access the UI at: https://ui.endpoints.huggingface.co
1. Create an Inference Endpoint with openai/whisper-large-v2
In this tutorial, you will learn how to deploy OpenAI Whisper from the Hugging Face Hub to Hugging Face Inference Endpoints.
You can access the UI of Inference Endpoints directly at: https://ui.endpoints.huggingface.co/ or through the Landingpage.
The first step is to deploy our model as an Inference Endpoint. Therefore we click “new endpoint” and add the Hugging face repository Id of the Whisper model we want to deploy. In our case, it is openai/whisper-large-v2.

Note: By default, Inference Endpoint will use “English” as the language for transcription, if you want to use Whisper for non-English speech recognition you would need to create a custom handler and adjust decoder prompt.
Now, we can make changes to the provider, region, or instance we want to use, as well as configure the security level of our endpoint. The easiest is to keep the suggested defaults from the application.
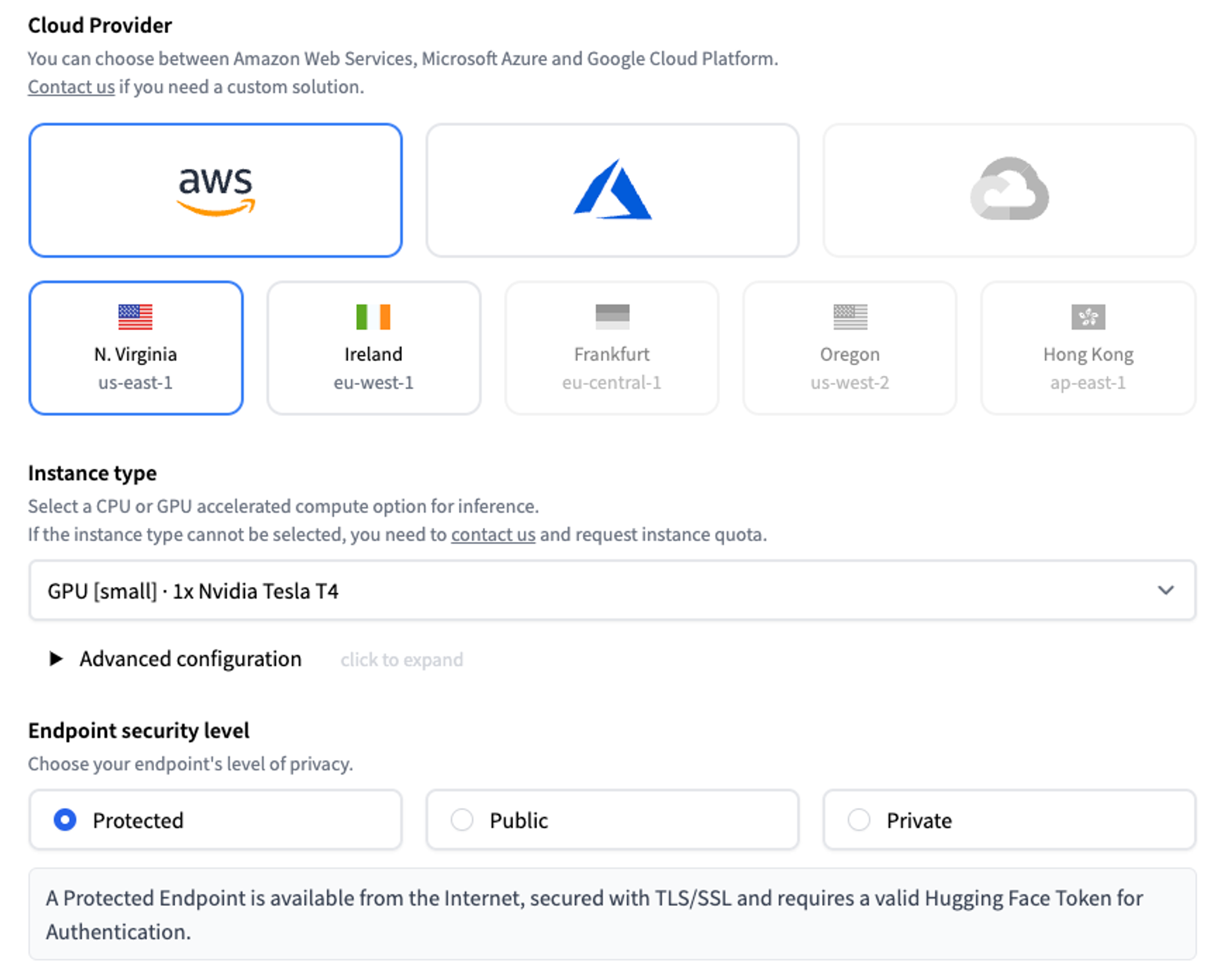
We can deploy our model by clicking on the “Create Endpoint” button. Once we click the “create” button, Inference Endpoints will create a dedicated container with the model and start our resources. After a few minutes, our endpoint is up and running.
We can test our Whisper model directly in the UI, by either recording our microphone or uploading a small audio file, e.g. sample.
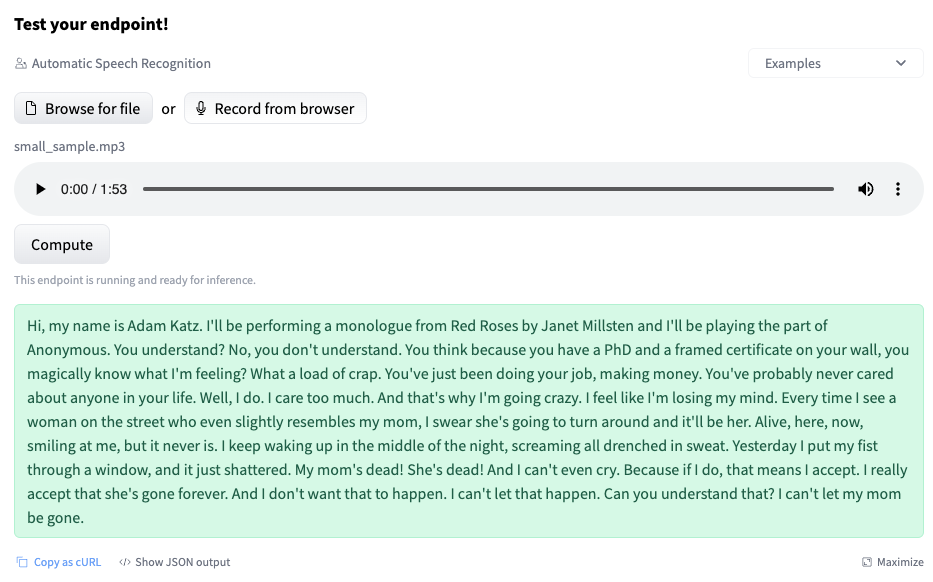
2. Integrate the Whisper endpoint into applications using Python and Javascript
Hugging Face Inference Endpoints can directly work with binary data, meaning we can send our audio file as binary and get the transcription in return.
You can download the sample audio from here: https://cdn-media.huggingface.co/speech_samples/sample2.flac.
Python Example
For Python, we are going to use requests to send our requests and read our audio file from disk. (make your you have it installed pip install request). Make sure to replace ENDPOINT_URL and HF_TOKEN with your values.
import json
from typing import List
import requests as r
import base64
import mimetypes
ENDPOINT_URL=""
HF_TOKEN=""
def predict(path_to_audio:str=None):
# read audio file
with open(path_to_audio, "rb") as i:
b = i.read()
# get mimetype
content_type= mimetypes.guess_type(path_to_audio)[0]
headers= {
"Authorization": f"Bearer {HF_TOKEN}",
"Content-Type": content_type
}
response = r.post(ENDPOINT_URL, headers=headers, data=b)
return response.json()
prediction = predict(path_to_audio="sample1.flac")
print(prediction)expected prediction
{"text": " going along slushy country roads and speaking to damp audiences in draughty school rooms day after day for a fortnight. He'll have to put in an appearance at some place of worship on Sunday morning, and he can come to us immediately afterwards."}Javascript
For Javascript, we create an HTML snippet, which you can run in the browser or using frontend frameworks like React, Svelte or Vue. The snippet is a minimal example of how we can add transcription features, in our application, by enabling the upload of audio files, which will then be transcribed. Make sure to replace ENDPOINT_URL and HF_TOKEN with your values.
<div><label for="audio-upload">Upload an audio file:</label></div>
<div><input id="audio-upload" type="file" /></div>
<div>Transcription:</div>
<code id="transcripiton"></code>
<script>
const ENDPOINT_URL = ''
const HF_TOKEN = ''
function changeHandler({ target }) {
// Make sure we have files to use
if (!target.files.length) return
// create request object to send file to inference endpoint
const options = {
method: 'POST',
headers: {
Authorization: `Bearer ${HF_TOKEN}`,
'Content-Type': target.files[0].type,
},
body: target.files[0],
}
// send post request to inference endpoint
fetch(ENDPOINT_URL, options)
.then((response) => response.json())
.then((response) => {
// add
console.log(response.text)
const theDiv = document.getElementById('transcripiton')
const content = document.createTextNode(response.text)
theDiv.appendChild(content)
})
.catch((err) => console.error(err))
}
document.getElementById('audio-upload').addEventListener('change', changeHandler)
</script>If you open this in the browser or with a server, you should see a plain HTML side with an input form, which you can use to upload an audio file.

3. Cost-performance comparison between Inference Endpoints and Amazon Transcribe and Google Cloud Speech-to-text
We managed to deploy and integrate OpenAI Whisper using Python or Javascript, but how do Inference Endpoints compare to AI Services of Public clouds like Amazon Transcribe or Google Cloud Speech-to-text?
For this, we took a look at the latency and cost of all three different options. For the cost, we compared two use cases, 1. real-time inference and 2. batch inference.
Latency
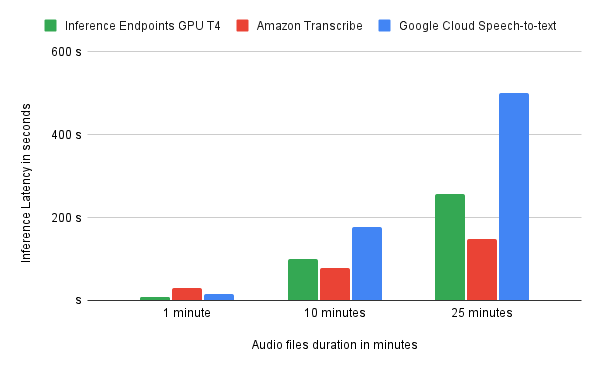
To compare the latency, we have created 4 different Audio files with lengths of 1 minute, 10 minutes, and 25 minutes and created/transcribed them using each service. In the chart below, you can find the results of it.
For Inference Endpoints, we went with the GPU-small instance, which runs an NVIDIA T4 and whisper-large-v2. You can see the latency is on-par, if not better than the managed cloud services, but the transcription is better. If you are interested in the raw transcriptions, let me know.
Real-time inference cost
Real-time inference describes the workload where you want the prediction of your model as fast as possible to be able to work with the results of it. When looking at real-time inference, we need to be careful since Amazon Transcribe and Google Cloud Speech-to-text are managed AI services where you pay only for what you use. With Inference Endpoints, you pay for the uptime of your endpoint based on the replicas.
For this scenario, we looked at how many hours of audio would be needed to achieve break-even with Inference Endpoints to reduce your cost on real-time workloads.
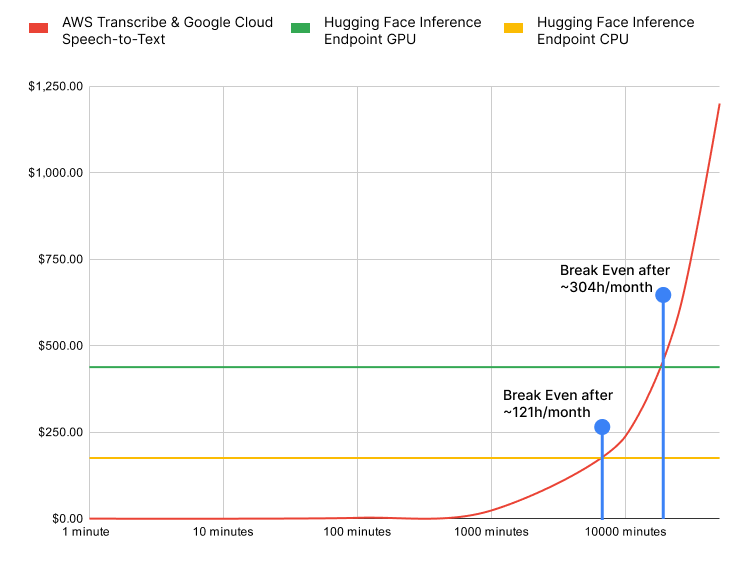
Amazon Transcribe and Google Cloud Speech-to-text cost the same and are represented as the red line in the chart. For Inference Endpoints, we looked at a CPU deployment and a GPU deployment. If you deploy Whisper large on a CPU, you will achieve break even after 121 hours of audio and for a GPU after 304 hours of audio data.
Batch inference cost
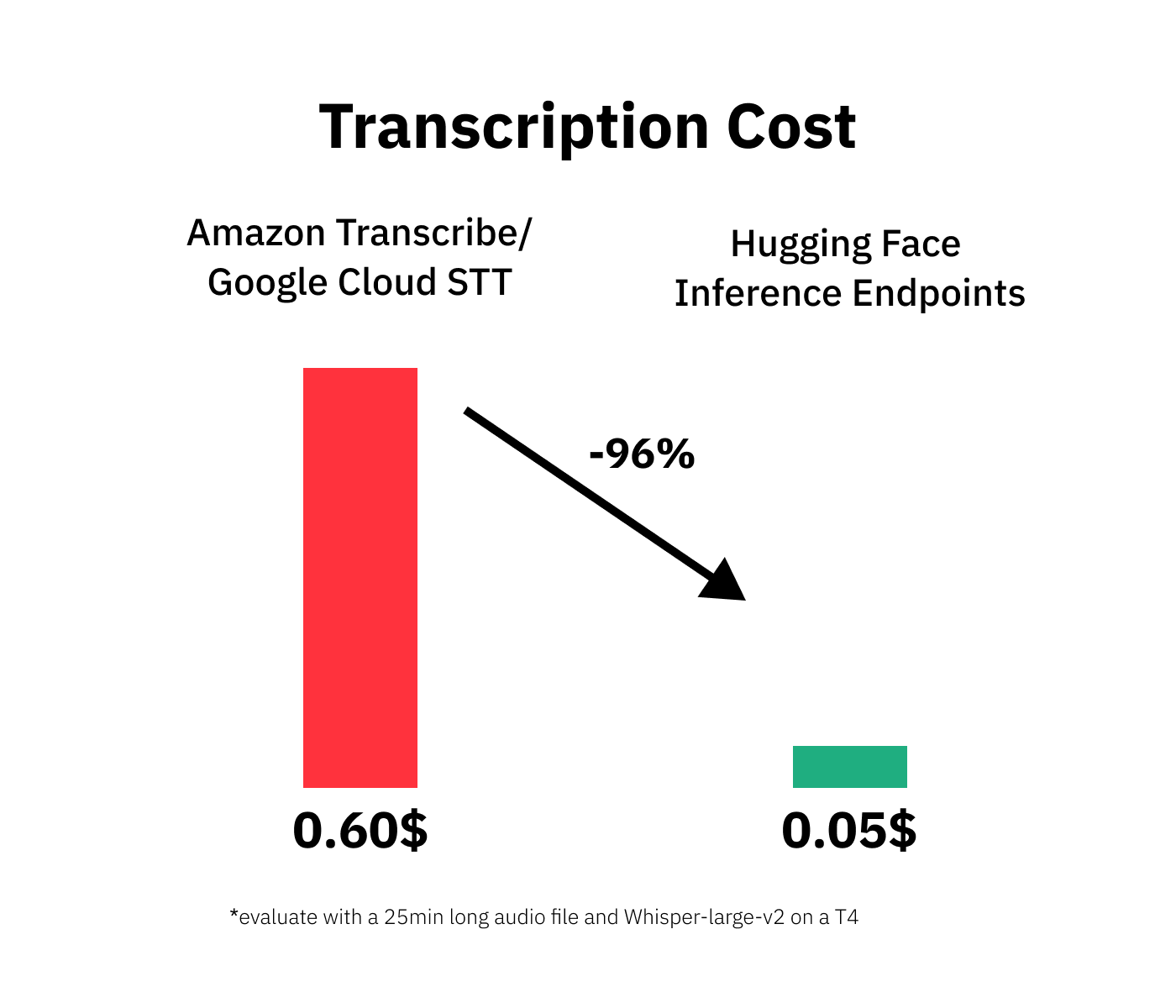
Batch inference describes the workload where you run inference over a “dataset”/collect of files on a specific schedule or after a certain amount of time. You can use Batch inference with Inference Endpoints by creating and deleting your endpoints when running your batch job.
For this scenario, we looked at how much it costs to transcribe 25 minutes of audio for each service. The results speak for themselves! With Hugging Face Inference Endpoints, you can save up to 96% when using batch processing. But you have to keep in mind that the start time/cold start for Inference Endpoints might be slower since you ll create resources.
Now, its your time be to integrate Whisper into your applications with Inference Endpoints.
Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.