Deploy open LLMs with vLLM on Hugging Face Inference Endpoints
Hugging Face Inference Endpoints offers an easy and secure way to deploy Machine Learning models for use in production. Inference Endpoints empower developers and data scientists to create AI applications without managing infrastructure: simplifying the deployment process to a few clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security.
In this blog post, we will show you how to deploy open LLMS with vLLM on Hugging Face Inference Endpoints. VLLM is one of the most popular open-source projects for deploying large language models. It is built for high-throughput and memory-efficient deployments of LLMs. In this blog post we will show you how to deploy Llama 3 on Hugging Face Inference Endpoints using vLLM.
Create Inference Endpoints
Inference Endpoints allows you to customize the container image used for deployment. We created a vLLM container supporting loading models from /repository since Inference Endpoints mounts the model artifacts to /repository. We also allowed to configure the model max sequence length using the MAX_MODEL_LEN environment variable.
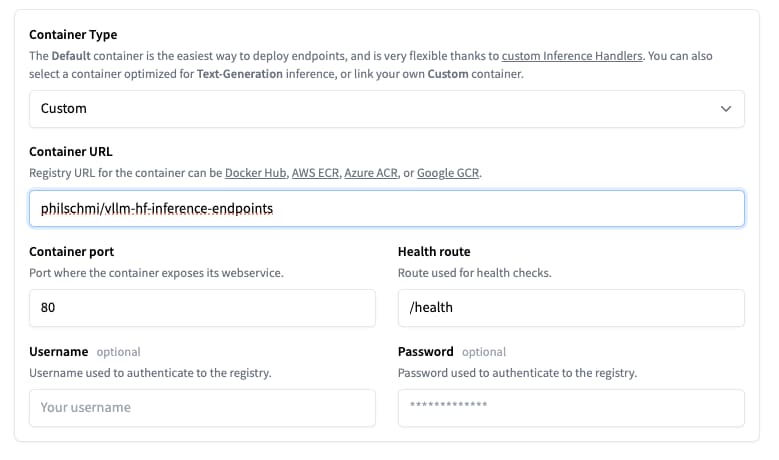
We can deploy the model in just a few clicks from the UI, or take advantage of the huggingface_hub Python library to programmatically create and manage Inference Endpoints. If you are using the UI, you have to select custom container type in the advanced configuration and add philschmi/vllm-hf-inference-endpoints as the container image. The UI is a great way to get started, but we currently do not support customizing the environment variables from the UI. We will show you how to do this using the huggingface_hub Python library.
We are going to use the huggingface_hub library to programmatically create and manage Inference Endpoints. First, we need to install the library:
pip install huggingface_hub[cli]Then we needd to make sure we are logged in and have access to Llama 3 model.
Note: Llama 3 is a gated model, please visit the Model Card and accept the license terms and acceptable use policy before submitting this form.
huggingface-cli login --token YOUR_API_TOKENNow we can create the Inference Endpoint using the create_inference_endpoint function. We will deploy meta-llama/Meta-Llama-3-8B-Instruct on a single A10G instance with a MAX_MODEL_LEN to 8192 to avoid out of memory errors.
from huggingface_hub import create_inference_endpoint
endpoint = create_inference_endpoint(
"vllm-meta-llama-3-8b-instruct",
repository="meta-llama/Meta-Llama-3-8B-Instruct",
framework="pytorch",
task="custom",
accelerator="gpu",
vendor="aws",
region="us-east-1",
type="protected",
instance_type="g5.2xlarge",
instance_size="medium",
custom_image={
"health_route": "/health",
"env": { "MAX_MODEL_LEN": "8192" },
"url": "philschmi/vllm-hf-inference-endpoints",
},
)
endpoint.wait()
print(endpoint.status)Running this code will create an Inference Endpoint with the specified configuration. The wait method will block until the Inference Endpoint is ready. You can check the status of the Inference Endpoint by printing the status attribute. You can also check the status of the Inference Endpoint in the Hugging Face Inference Endpoints UI.
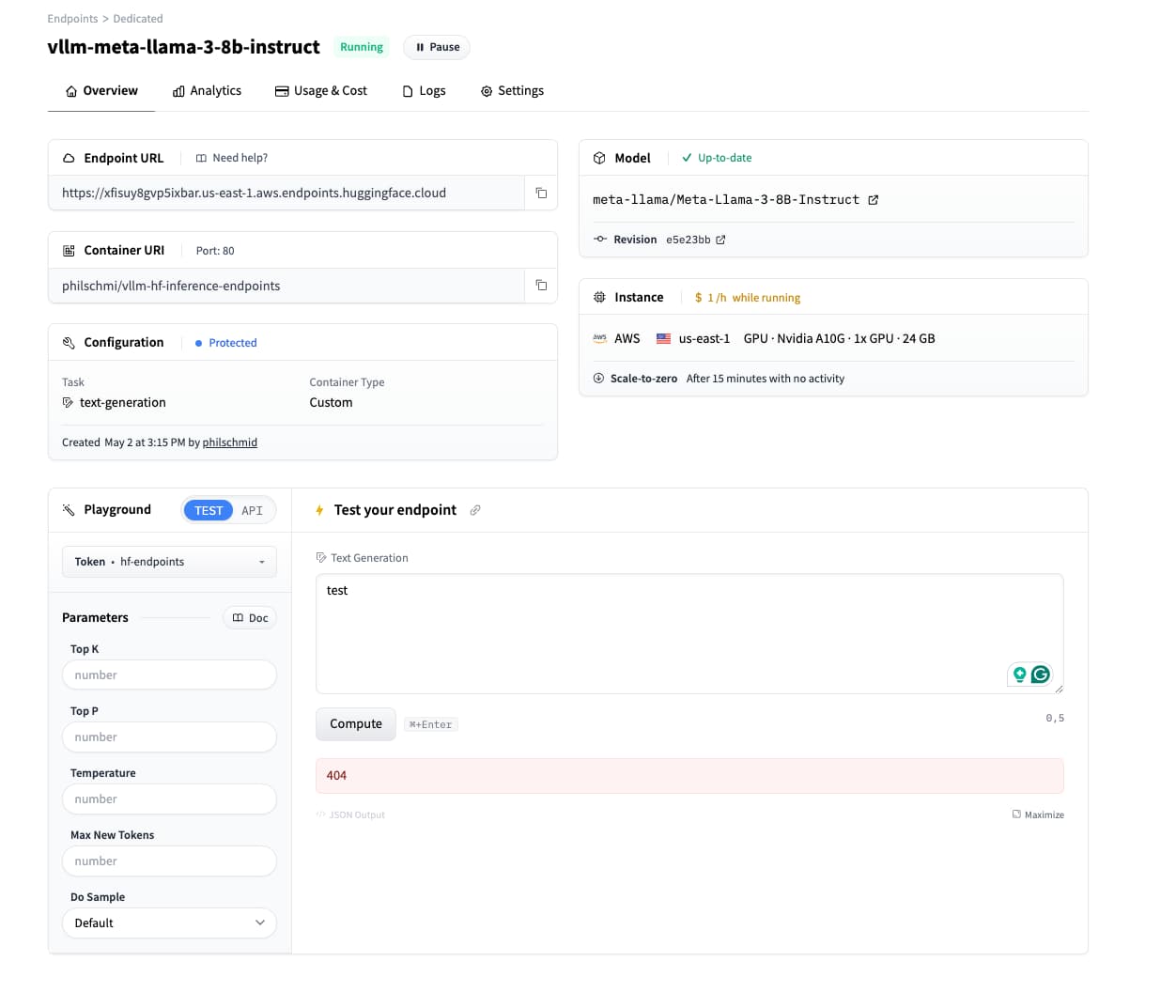
Note: The UI widgets are currently not working for custom container images (sending a request to "/" and not "v1/completion7/chat"). You will receive a 404 if you try it. We are working on fixing/adding this. In the meantime you need to curl or use the OpenAI SDK to interact with the model.
Test Endpoint using OpenAI SDK
We deployed vLLM using the OpenAI completion API. We can test the Inference Endpoint using the OpenAI SDK. First, we need to install the OpenAI SDK:
pip install openaiThen we can test the Inference Endpoint using the OpenAI SDK:
Note: We have to use /repository as the model since thats where Inference Endpoints mounts the model.
from huggingface_hub import HfFolder
from openai import OpenAI
ENDPOINT_URL = endpoint.url + "/v1/" # if endpoint object is not available check the UI
API_KEY = HfFolder.get_token()
# initialize the client but point it to TGI
client = OpenAI(base_url=ENDPOINT_URL, api_key=API_KEY)
chat_completion = client.chat.completions.create(
model="/repository", # needs to be /repository since there are the model artifacts stored
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Why is open-source software important?"},
],
stream=True,
max_tokens=500
)
# iterate and print stream
for message in chat_completion:
if message.choices[0].delta.content:
print(message.choices[0].delta.content, end="")Nice work! You have successfully deployed Llama 3 on Hugging Face Inference Endpoints using vLLM. You can now use the OpenAI SDK to interact with the model. You can also use the Hugging Face Inference Endpoints UI to monitor the model's performance and scale it up or down as needed.
You can delete the Inference Endpoint using the delete method:
endpoint.delete()Conclusion
In this blog post, we showed you how to deploy open LLMS with vLLM on Hugging Face Inference Endpoints using the custom container image. We used the huggingface_hub Python library to programmatically create and manage Inference Endpoints. We also showed you how to test the Inference Endpoint using the OpenAI SDK. We hope this blog post helps you deploy your LLMs on Hugging Face Inference Endpoints.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.