Generative AI for Document Understanding with Hugging Face and Amazon SageMaker
In this tutorial, you will learn how to fine-tune and deploy Donut-base for document-understand/document-parsing using Hugging Face Transformers and Amazon SageMaker. Donut is a new document-understanding model achieving state-of-art performance with an MIT-license, which allows it to be used for commercial purposes compared to other models like LayoutLMv2/LayoutLMv3.
You will learn how to:
- Setup Development Environment
- Load SROIE dataset
- Preprocess and upload dataset for Donut
- Fine-tune Donut model on Amazon SageMaker
- Deploy Donut model on Amazon SageMaker
Quick intro: Document Understanding Transformer (Donut) by ClovaAI
Document Understanding Transformer (Donut) is a new Transformer model for OCR-free document understanding. It doesn't require an OCR engine to process scanned documents but is achieving state-of-the-art performances on various visual document understanding tasks, such as visual document classification or information extraction (a.k.a. document parsing). Donut is a multimodal sequence-to-sequence model with a vision encoder (Swin Transformer) and text decoder (BART). The encoder receives the images and computes it into an embedding, which is then passed to the decoder, which generates a sequence of tokens.
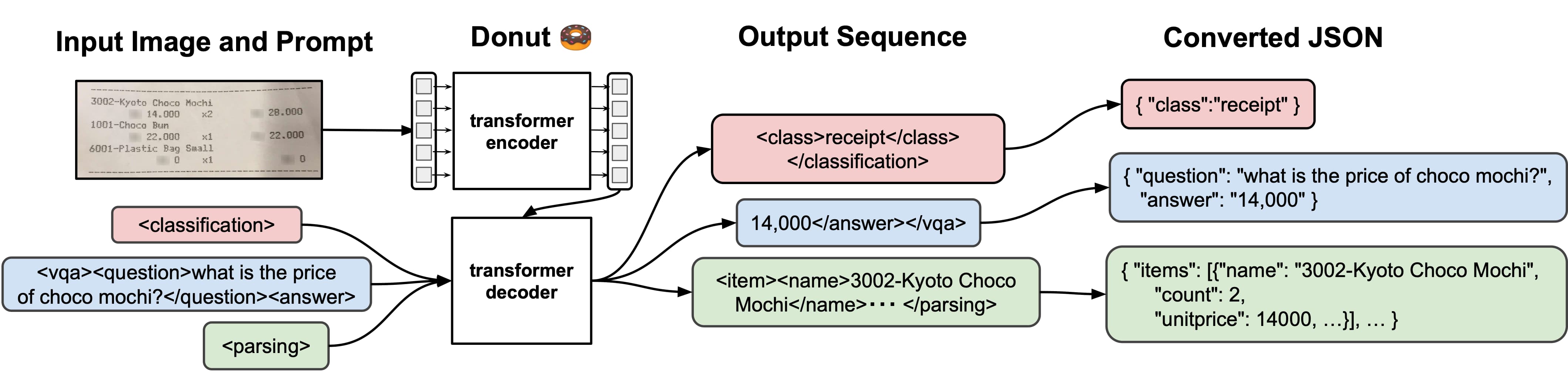
- Paper: https://arxiv.org/abs/2111.15664
- Official repo: https://github.com/clovaai/donut
Now we know how Donut works, so let's get started. 🚀
1. Setup Development Environment
The first step is to install the required libraries and setup the environment. We will use the Amazon SageMaker Python SDK to interact with SageMaker. We will also use Hugging Face Transformers & Datasets to preprocess the data.
!pip install "transformers[sentencepiece]==4.26.0" "datasets[s3]==2.9.0" sagemaker --upgrade --quietIf you are going to use Sagemaker in a local environment. You need access to an IAM Role with the required permissions for Sagemaker. You can find here more about it.
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
2. Load SROIE dataset
We will use the SROIE dataset a collection of 1000 scanned receipts including their OCR, more specifically we will use the dataset from task 2 "Scanned Receipt OCR". The available dataset on Hugging Face (darentang/sroie) is not compatible with Donut. Thats why we will use the original dataset together with the imagefolder feature of datasets to load our dataset. Learn more about loading image data here.
Note: The test data for task2 is sadly not available. Meaning that we end up only with 626 images.
First, we will clone the repository, extract the dataset into a separate folder and remove the unnecessary files.
%%bash
# clone repository
git clone https://github.com/zzzDavid/ICDAR-2019-SROIE.git
# copy data
cp -r ICDAR-2019-SROIE/data ./
# clean up
rm -rf ICDAR-2019-SROIE
rm -rf data/boxNow we have two folders inside the data/ directory. One contains the images of the receipts and the other contains the OCR text. The next step is to create a metadata.json file that contains the information about the images including the OCR-text. This is necessary for the imagefolder feature of datasets.
The metadata.json should look at the end similar to the example below.
{"file_name": "0001.png", "text": "This is a golden retriever playing with a ball"}
{"file_name": "0002.png", "text": "A german shepherd"}In our example will "text" column contain the OCR text of the image, which will later be used for creating the Donut specific format.
import json
from pathlib import Path
import shutil
# define paths
base_path = Path("data")
metadata_path = base_path.joinpath("key")
image_path = base_path.joinpath("img")
# define metadata list
metadata_list = []
# parse metadata
for file_name in metadata_path.glob("*.json"):
with open(file_name, "r") as json_file:
# load json file
data = json.load(json_file)
# create "text" column with json string
text = json.dumps(data)
# add to metadata list if image exists
if image_path.joinpath(f"{file_name.stem}.jpg").is_file():
metadata_list.append({"text":text,"file_name":f"{file_name.stem}.jpg"})
# delete json file
# write jsonline file
with open(image_path.joinpath('metadata.jsonl'), 'w') as outfile:
for entry in metadata_list:
json.dump(entry, outfile)
outfile.write('\n')
# remove old meta data
shutil.rmtree(metadata_path)Good Job! Now we can load the dataset using the imagefolder feature of datasets.
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_dir=image_path, split="train")
print(f"Dataset has {len(dataset)} images")
print(f"Dataset features are: {dataset.features.keys()}")Now, lets take a closer look at our dataset
import random
random_sample = random.randint(0, len(dataset))
print(f"Random sample is {random_sample}")
print(f"OCR text is {dataset[random_sample]['text']}")
dataset[random_sample]['image'].resize((250,400))
3. Preprocess and upload dataset for Donut
As we learned in the introduction, Donut is a sequence-to-sequence model with a vision encoder and text decoder. When fine-tuning the model we want it to generate the "text" based on the image we pass it. Similar to NLP tasks, we have to tokenize and preprocess the text.
Before we can tokenize the text, we need to transform the JSON string into a Donut compatible document.
current JSON string
{
"company": "ADVANCO COMPANY",
"date": "17/01/2018",
"address": "NO 1&3, JALAN WANGSA DELIMA 12, WANGSA LINK, WANGSA MAJU, 53300 KUALA LUMPUR",
"total": "7.00"
}Donut document
<s></s><s_company>ADVANCO COMPANY</s_company><s_date>17/01/2018</s_date><s_address>NO 1&3, JALAN WANGSA DELIMA 12, WANGSA LINK, WANGSA MAJU, 53300 KUALA LUMPUR</s_address><s_total>7.00</s_total></s>To easily create those documents the ClovaAI team has created a json2token method, which we extract and then apply.
new_special_tokens = [] # new tokens which will be added to the tokenizer
task_start_token = "<s>" # start of task token
eos_token = "</s>" # eos token of tokenizer
def json2token(obj, update_special_tokens_for_json_key: bool = True, sort_json_key: bool = True):
"""
Convert an ordered JSON object into a token sequence
"""
if type(obj) == dict:
if len(obj) == 1 and "text_sequence" in obj:
return obj["text_sequence"]
else:
output = ""
if sort_json_key:
keys = sorted(obj.keys(), reverse=True)
else:
keys = obj.keys()
for k in keys:
if update_special_tokens_for_json_key:
new_special_tokens.append(fr"<s_{k}>") if fr"<s_{k}>" not in new_special_tokens else None
new_special_tokens.append(fr"</s_{k}>") if fr"</s_{k}>" not in new_special_tokens else None
output += (
fr"<s_{k}>"
+ json2token(obj[k], update_special_tokens_for_json_key, sort_json_key)
+ fr"</s_{k}>"
)
return output
elif type(obj) == list:
return r"<sep/>".join(
[json2token(item, update_special_tokens_for_json_key, sort_json_key) for item in obj]
)
else:
# excluded special tokens for now
obj = str(obj)
if f"<{obj}/>" in new_special_tokens:
obj = f"<{obj}/>" # for categorical special tokens
return obj
def preprocess_documents_for_donut(sample):
# create Donut-style input
text = json.loads(sample["text"])
d_doc = task_start_token + json2token(text) + eos_token
# convert all images to RGB
image = sample["image"].convert('RGB')
return {"image": image, "text": d_doc}
proc_dataset = dataset.map(preprocess_documents_for_donut)
print(f"Sample: {proc_dataset[45]['text']}")
print(f"New special tokens: {new_special_tokens + [task_start_token] + [eos_token]}")
The next step is to tokenize our text and encode the images into tensors. Therefore we need to load DonutProcessor, add our new special tokens and adjust the size of the images when processing from [1920, 2560] to [720, 960] to need less memory and have faster training.
from transformers import DonutProcessor
# Load processor
model_id = "naver-clova-ix/donut-base"
processor = DonutProcessor.from_pretrained(model_id)
# add new special tokens to tokenizer
processor.tokenizer.add_special_tokens({"additional_special_tokens": new_special_tokens + [task_start_token] + [eos_token]})
# we update some settings which differ from pretraining; namely the size of the images + no rotation required
# resizing the image to smaller sizes from [1920, 2560] to [960,1280]
processor.feature_extractor.size = [720,960] # should be (width, height)
processor.feature_extractor.do_align_long_axis = FalseNow, we can prepare our dataset, which we will use for the training later.
def transform_and_tokenize(sample, processor=processor, split="train", max_length=512, ignore_id=-100):
# create tensor from image
try:
pixel_values = processor(
sample["image"], random_padding=split == "train", return_tensors="pt"
).pixel_values.squeeze()
except Exception as e:
print(sample)
print(f"Error: {e}")
return {}
# tokenize document
input_ids = processor.tokenizer(
sample["text"],
add_special_tokens=False,
max_length=max_length,
padding="max_length",
truncation=True,
return_tensors="pt",
)["input_ids"].squeeze(0)
labels = input_ids.clone()
labels[labels == processor.tokenizer.pad_token_id] = ignore_id # model doesn't need to predict pad token
return {"pixel_values": pixel_values, "labels": labels, "target_sequence": sample["text"]}
# need at least 32-64GB of RAM to run this
processed_dataset = proc_dataset.map(transform_and_tokenize,remove_columns=["image","text"])Before we can upload our dataset to S3 for training we want to split the dataset into train and test sets.
processed_dataset = processed_dataset.train_test_split(test_size=0.1)
print(processed_dataset)After that is done we use the new FileSystem integration to upload our dataset to S3. We are using the sess.default_bucket(), adjust this if you want to store the dataset in a different S3 bucket. We will use the S3 path later in our training script.
# save train_dataset to s3
training_input_path = f's3://{sess.default_bucket()}/processed/donut-sagemaker/train'
processed_dataset["train"].save_to_disk(training_input_path)
# save train_dataset to s3
test_input_path = f's3://{sess.default_bucket()}/processed/donut-sagemaker/test'
processed_dataset["test"].save_to_disk(test_input_path)
print("uploaded data to:")
print(f"training dataset to: {training_input_path}")
print(f"test dataset to: {test_input_path}")4. Fine-tune Donut model on Amazon SageMaker
After we have processed our dataset, we can start training our model using a Amazon SageMaker training job using the HuggingFace Estimator. The Estimator handles end-to-end Amazon SageMaker training and deployment tasks. The Estimator manages the infrastructure use.
SagMaker takes care of starting and managing all the required ec2 instances for us, provides the correct huggingface container, uploads the provided scripts and downloads the data from our S3 bucket into the container at /opt/ml/input/data. Then, it starts the training job by running.
Important steps we need to think of is that we extended the DonutProcessor earlier and added special tokens, which we need to pass through to our training script. We also need to pass the image_size and max_length to our training script.
As pretrained model we will use naver-clova-ix/donut-base. The donut-base includes only the pre-trained weights and was introduced in the paper OCR-free Document Understanding Transformer by Geewok et al. and first released in this repository.
In addition to loading our model, we are resizing the embedding layer to match newly added tokens and adjusting the image_size of our encoder to match our dataset. We are also adding tokens for inference later.
import time
import json
from sagemaker.huggingface import HuggingFace
# define Training Job Name
job_name = f'huggingface-donut-{time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())}'
# stingify special tokens
special_tokens = ",".join(processor.tokenizer.special_tokens_map_extended["additional_special_tokens"])
# hyperparameters, which are passed into the training job
hyperparameters = {
'model_id': model_id, # pre-trained model
'special_tokens': json.dumps(special_tokens), # special tokens which will be added to the tokenizer
'dataset_path': '/opt/ml/input/data/training', # path where sagemaker will save training dataset
'epochs': 3, # number of training epochs
'per_device_train_batch_size': 8, # batch size for training
'gradient_checkpointing': True, # batch size for training
'lr': 4e-5, # learning rate used during training
}
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point = 'train.py', # train script
source_dir = 'scripts', # directory which includes all the files needed for training
instance_type = 'ml.g5.2xlarge', # instances type used for the training job
instance_count = 1, # the number of instances used for training
base_job_name = job_name, # the name of the training job
role = role, # Iam role used in training job to access AWS ressources, e.g. S3
volume_size = 100, # the size of the EBS volume in GB
transformers_version = '4.26', # the transformers version used in the training job
pytorch_version = '1.13', # the pytorch_version version used in the training job
py_version = 'py39', # the python version used in the training job
hyperparameters = hyperparameters
)Lets start the training job and wait until it is finished. This will take around 30 minutes.
# define a data input dictonary with our uploaded s3 uris
data = {'training': training_input_path}
# starting the train job with our uploaded datasets as input
huggingface_estimator.fit(data, wait=True)5. Deploy Donut model on Amazon SageMaker
During the training we copied a infernece.py into out model.tar.gz which allows us now to easily deploy our model to SageMaker for inference.
The inference.py implements a custom model_fn and predict_fn for our Donut model. The model_fn loads the model and processor and the predict_fn tokenizes the input and returns the prediction.
from sagemaker.huggingface import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=huggingface_estimator.model_data,
role=role,
transformers_version="4.26",
pytorch_version="1.13",
py_version="py39",
model_server_workers=1
)Before we can deploy model with the HuggingFaceModel class we need to create a new serializer, which supports our image data. The Serializer are used in Predictor and in the predict method to serializer our data to a specific mime-type. The default serialzier for the HuggingFacePredcitor is a JSON serializer, but since we are not going to send text data to the endpoint we will use the DataSerializer.
from sagemaker.serializers import DataSerializer
# create a serializer for the data
image_serializer = DataSerializer(content_type='image/x-image') # using x-image to support multiple image formats
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type= "ml.g5.2xlarge",
serializer=image_serializer, # serializer for our image files.
)SageMaker starts the deployment process by creating a SageMaker Endpoint Configuration and a SageMaker Endpoint. The Endpoint Configuration defines the model and the instance type.
Lets test by using a example from the test split.
from PIL import Image
import io
from random import randrange
from transformers.image_transforms import to_pil_image
import numpy as np
test_sample = processed_dataset["test"][randrange(0,len(processed_dataset["test"]))]
image = to_pil_image(np.array(test_sample["pixel_values"]))
def image_to_byte_array(image: Image) -> bytes:
format = image.format if image.format else 'JPEG'
# BytesIO is a file-like buffer stored in memory
img_byte_arr = io.BytesIO()
# image.save expects a file-like as a argument
image.save(img_byte_arr, format=format)
# Turn the BytesIO object back into a bytes object
return img_byte_arr.getvalue()
res = predictor.predict(data=image_to_byte_array(image))
target = processor.token2json(test_sample["target_sequence"])
print(f"Reference:\n {target}")
print(f"Prediction:\n {res}")
image.resize((350,600))
# Reference:
# {'total': '41.87', 'date': '24/10/2017', 'company': 'GARDENIA BAKERIES (KL) SDN BHD', 'address': 'LOT 3, JALAN PELABUR 23/1, 40300 SHAH ALAM, SELANGOR.'}
# Prediction:
# {'total': '41.87', 'date': '24/10/2017', 'company': 'GARDENIA BAKERIES (KL) SDN BHD', 'address': 'LOT 3, JALAN PELABUR 23/1, 40300 SHAH ALAM, SELANGOR.'}
Awesome!! Our fine-tuned model parsed the document correctly and extracted the right values. The next step is to evalute our model on the test set. Since the model itself is a seq2seq is not that straightforward to evaluate.
To keep things simple we will use rogue short for Recall-Oriented Understudy for Gisting Evaluation. This metric does not behave like the standard accuracy: it will compare a generated text against a set of reference text. The rogue score is mostly used for summarization or machine translation tasks.
The higher the score the closer the generated text is to the reference text.
!pip install rouge-score py7zrimport evaluate
from tqdm import tqdm
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false" # disable parallelism in tokenizers library
# Metric
rogue = evaluate.load("rouge")
predictions, references = [], []
# iterate over dataset
for sample in tqdm(processed_dataset["test"],total=len(processed_dataset["test"])):
image = to_pil_image(np.array(sample["pixel_values"]))
prediction = predictor.predict(data=image_to_byte_array(image))
reference = processor.token2json(sample["target_sequence"])
predictions.append(json.dumps(prediction))
references.append(json.dumps(reference))
# compute scores
results = rogue.compute(predictions=predictions,references=references)
print(results)
# {'rouge1': 0.8173891303548311, 'rouge2': 0.7266157117328251, 'rougeL': 0.8167726537736875, 'rougeLsum': 0.8144718562842747}Our model achieves an rogue 1 score of 81.7% on the test set. The rogue1 refers to the overlap of unigrams (each word) between the prediction and reference.
Note: The evaluation we did was very simple.
In an inference test the model predicted for the address the value NO. 31G&33G, JALAN SETIA INDAH X ,U13/X 40170 SETIA ALAM and the ground truth was 'NO. 31G&33G, JALAN SETIA INDAH X,U13/X 40170 SETIA ALAM', where the only difference is the whitespace in between X and ,U13/X.
Clean up
To avoid unnecessary costs, we should delete the endpoint and the model.
predictor.delete_model()
predictor.delete_endpoint()Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.