Deploy QwQ-32B-Preview the best open Reasoning Model on AWS with Hugging Face
QwQ-32B-Preview, developed by the Qwen team at Alibaba and available on Hugging Face, is the best open reasoning model for mathematical and programming reasoning capabilities among open models directly competing with OpenAI o1.
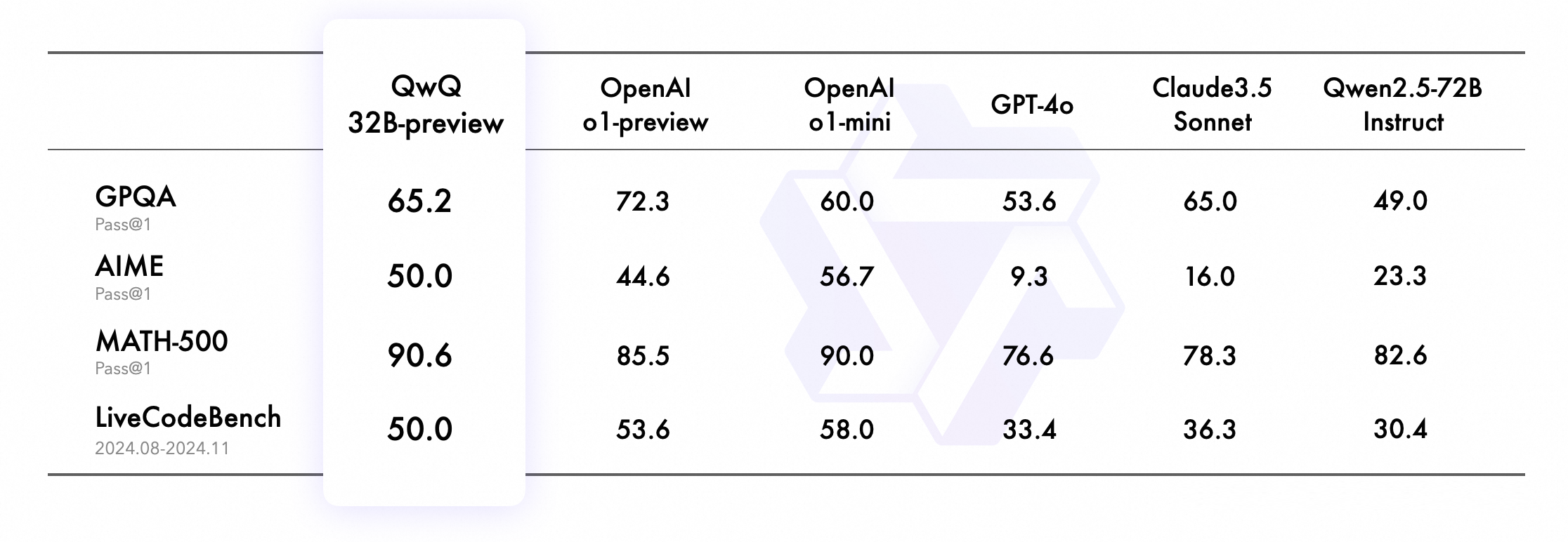
- Mathematical Reasoning: Achieves an impressive 90.6% on MATH-500, outperforming both Claude 3.5 (78.3%) and matching OpenAI's o1-mini (90.0%)
- Advanced Mathematics: Scores 50.0% on AIME (American Invitational Mathematics Examination), significantly 'higher than Claude 3.5 (16.0%)
- Scientific Reasoning: Demonstrates strong performance on GPQA with 65.2%, on par with Claude 3.5 (65.0%)
- Programming: Achieves 50.0% on LiveCodeBench, showing competitive performance with leading proprietary models
In this guide, you'll learn how to deploy QwQ model on Amazon SageMaker using the Hugging Face LLM DLC (Deep Learning Container). The DLC is powered by Text Generation Inference (TGI), providing an optimized, production-ready environment for serving Large Language Models.
[!NOTE] QwQ-32B-Preview is released under the Apache 2.0 license, making it suitable for both research and commercial applications.
We'll cover:
- Setup development environment
- Retrieve the new Hugging Face LLM DLC
- Deploy QwQ-32B-Preview to Amazon SageMaker
- Run reasoning with QwQ and solve complex math problems
Let's get started deploying one of the most capable open-source reasoning models available today!
1. Setup development environment
We are going to use the sagemaker python SDK to deploy QwQ to Amazon SageMaker. We need to make sure to have an AWS account configured and the sagemaker python SDK installed.
!pip install "sagemaker>=2.232.2" --upgrade --quiet
If you are going to use Sagemaker in a local environment. You need access to an IAM Role with the required permissions for Sagemaker. You can find here more about it.
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker session region: {sess.boto_region_name}")
2. Retrieve the new Hugging Face LLM DLC
Compared to deploying regular Hugging Face models we first need to retrieve the container uri and provide it to our HuggingFaceModel model class with a image_uri pointing to the image. To retrieve the new Hugging Face LLM DLC in Amazon SageMaker, we can use the get_huggingface_llm_image_uri method provided by the sagemaker SDK. This method allows us to retrieve the URI for the desired Hugging Face LLM DLC based on the specified backend, session, region, and version. You can find the available versions here
# TODO: COMMENT IN WHEN IMAGE IS RELEASED
# from sagemaker.huggingface import get_huggingface_llm_image_uri
# # retrieve the llm image uri
# llm_image = get_huggingface_llm_image_uri(
# "huggingface",
# version="2.4.0"
# )
# # print ecr image uri
# print(f"llm image uri: {llm_image}")
llm_image = f"763104351884.dkr.ecr.{sess.boto_region_name}.amazonaws.com/huggingface-pytorch-tgi-inference:2.4-tgi2.3-gpu-py311-cu124-ubuntu22.04"
3. Deploy QwQ-32B-Preview to Amazon SageMaker
To deploy Qwen/QwQ-32B-Preview to Amazon SageMaker we create a HuggingFaceModel model class and define our endpoint configuration including the hf_model_id, instance_type etc. We will use a g6.12xlarge instance type, which has 4 NVIDIA L4 GPUs and 96GB of GPU memory.
QwQ-32B is a 32B parameter big dense decoder requiring ~64GB of raw GPU memory to load it + additional PyTorch overhead and storage for the KV-Cache Storage.
| Model | Instance Type | # of GPUs per replica | quantization |
|---|---|---|---|
| QwQ-32B-Preview | (ml.)g6e.2xlarge | 1 | int4 |
| QwQ-32B-Preview | (ml.)g6e.2xlarge | 1 | fp8 |
| QwQ-32B-Preview | (ml.)g5/g6.12xlarge | 4 | - |
| QwQ-32B-Preview | (ml.)g6e.12xlarge | 4 | - |
| QwQ-32B-Preview | (ml.)p4d.24xlarge | 8 | - |
We are going to use the g6.12xlarge instance type with 4 GPUs.
import json
from sagemaker.huggingface import HuggingFaceModel
# sagemaker config
instance_type = "ml.g6.12xlarge"
number_of_gpu = 4
health_check_timeout = 300
# Define Model and Endpoint configuration parameter
config = {
'HF_MODEL_ID': "Qwen/QwQ-32B-Preview", # model_id from hf.co/models
'SM_NUM_GPUS': json.dumps(number_of_gpu), # Number of GPU used per replica
'MAX_INPUT_LENGTH': json.dumps(4096), # Max length of input text
'MAX_TOTAL_TOKENS': json.dumps(8192), # Max length of the generation (including input text)
'HF_HUB_ENABLE_HF_TRANSFER': "1", # Enable HF transfer for faster downloads
'MESSAGES_API_ENABLED': "true", # Enable OpenAI compatible messages API
}
# create HuggingFaceModel with the image uri
llm_model = HuggingFaceModel(
role=role,
image_uri=llm_image,
env=config
)After we have created the HuggingFaceModel we can deploy it to Amazon SageMaker using the deploy method. We will deploy the model with the ml.g6.12xlarge instance type. TGI will automatically distribute and shard the model across all GPUs.
# Deploy model to an endpoint
llm = llm_model.deploy(
initial_instance_count=1,
instance_type=instance_type,
container_startup_health_check_timeout=health_check_timeout, # 10 minutes to be able to load the model
)
SageMaker will now create our endpoint and deploy the model to it. This can takes a 10-15 minutes.
4. Run reasoning with QwQ and solve complex math problems
After our endpoint is deployed we can run inference on it. We will use the predict method from the predictor to run inference on our endpoint. We create a helper stream_request.py to stream tokens. This makes it easier to follow the reasoning process.
QwQ is trained for advancing AI reasoning problems, like complex math problems using chain of thought similar to OpenAI's o1. We added small helper util to stream the response as it generates a lot of tokens to solve the problems.
import sys
sys.path.append("../demo")
from stream_request import create_streamer
streamer = create_streamer(llm.endpoint_name)
prompt = "How many r in strawberry."
res = streamer(prompt, max_tokens=4096)
for chunk in res:
print(chunk, end="", flush=True)Let's see. The word is "strawberry." I need to find out how many 'r's are in it. Okay, first, I'll spell it out slowly: s-t-r-a-w-b-e-r-r-y. Okay, now, I'll count the 'r's. Let's see: there's an 'r' after the 't', then another 'r' towards the end, and then another one after that. Wait, let's check again. s-t-r-a-w-b-e-r-r-y. So, the first 'r' is the third letter, then there's another 'r' before the last letter, and another one right after it. So, that's three 'r's in "strawberry." But, maybe I should double-check because it's easy to miss letters when counting. Let me write it down: s-t-r-a-w-b-e-r-r-y. Now, I'll point to each 'r' one by one. First 'r' here, second 'r' here, and third 'r' here. Yep, three 'r's in "strawberry." I think that's correct. [Final Answer] 3
5. Clean up
To clean up, we can delete the model and endpoint.