Mini-R1: Reproduce Deepseek R1 „aha moment“ a RL tutorial
The release of Deepseek R1 shocked the industry. Why? Well, DeepSeek-R1 is an open model that rivals OpenAI's o1 in complex reasoning tasks, introduced using Group Relative Policy Optimization (GRPO) and RL-focused multi-stage training approach. They not only released the model, but also a research paper on how they did it.
In the paper they described an "aha moment" when using pure RL to train the model. During this phase, DeepSeek-R1-Zero (the first test of DeepSeek-R1) learns to allocate more thinking time to a problem by reevaluating its initial approach without any human feedback or data describing how to do it. They describe this as an "aha moment" as:
This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.
In this blog post we want to recreate the small "aha moment" of DeepSeek-R1 using Group Relative Policy Optimization (GRPO) and the Countdown Game. We will train an open model using reinforcement learning trying to teach it self-verification and search abilities all on its own to solve the Countdown Game. The Countdown game is a numbers puzzle where players use a set of randomly drawn numbers and basic arithmetic operations (+, -, ×, ÷) to reach or get as close as possible to a target number.
Target Number: 952
Available Numbers: 25, 50, 75, 100, 3, 6
(100 × (3 × 3)) + (50 + 6 / 3) = 952The blog post includes an interactive code which you can run in a Jupyter Notebook on how to train a model using GRPO and Q-Lora. This is a great way to learn how to use TRL and GRPO, but it is very slow and requires a lot of compute. Additionally, I added a script and instructions to run the training on Node with multiple GPUs or a SLURM cluster.
- Setup the development environment
- Generate training samples with reasoning prefix from the Countdown Game
- Train the model using GRPO (Educational part)
- Distributed Training example for GRPO using Deepspeed and vLLM
- Results and Training Observations
Note: This blog is inspired by Jiayi Pan who initially explored the idea and proofed it with a small model.
But Before we start, let's take a look at the Group Relative Policy Optimization (GRPO) and understand how it works.
Group Relative Policy Optimization (GRPO)
Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm to improve the reasoning capabilities of LLMs. It was introduced in the DeepSeekMath paper in the context of mathematical reasoning. GRPO modifies the traditional Proximal Policy Optimization (PPO) by eliminating the need for a value function model. Instead, it estimates baselines from group scores, reducing memory usage and computational overhead. GRPO, now also used by the Qwen team, can be used with rule/binary-based Rewards as well as General Reward Models to improve models on helpfulness.
- Sampling: Generate multiple outputs for each prompt using the current policy
- Reward Scoring: Each generation is scored using a reward function, could be (rule-based or outcome-based)
- Advantage Calculation: The average reward of the generated outputs is used as a baseline. The advantage of each solution within the group is then computed relative to this baseline. The reward is normalized within a group.
- Policy Optimization: The policy tries to maximize the GRPO objective, which includes the calculated advantages and a KL divergence term. This is different from how PPO implements the KL term within the reward.

1. Setup the development environment
Our first step is to install Hugging Face Libraries and Pytorch, vllm, and trl, transformers and datasets. If you haven't heard of trl yet, don't worry. It is a new library on top of transformers and datasets, which makes it easier to fine-tune, rlhf, align open LLMs.
# Install Pytorch & other libraries, make sure to match your GPU driver version
%pip install "torch==2.5.1" tensorboard "setuptools<71.0.0" --index-url https://download.pytorch.org/whl/cu121
# Install flash-attn
%pip install flash-attn
# Install Hugging Face libraries
%pip install --upgrade \
"transformers==4.48.1" \
"datasets==3.1.0" \
"accelerate==1.3.0" \
"hf-transfer==0.1.9" \
"deepspeed==0.15.4" \
"trl==0.14.0"
# install vLLM
%pip install "vllm==0.7.0"
## IMPORTANT: If you want to run the notebook and the interactive cells you also need to install the following libraries:
# But first read it the blog post and then decide as they might conflict with the libraries for distributed training.
# %pip install "peft==0.14.0" "bitsandbytes==0.45.0"
Note: you may need to restart the kernel to use updated packages.
We will use the Hugging Face Hub as a remote model versioning service. This means we will automatically push our model, logs and information to the Hub during training. You must register on the Hugging Face for this. After you have an account, we will use the login util from the huggingface_hub package to log into our account and store our token (access key) on the disk.
from huggingface_hub import login
login(token="", add_to_git_credential=True) # ADD YOUR TOKEN HERE2. Generate training samples with reasoning prefix from the Countdown Game
We are going to use the Jiayi-Pan/Countdown-Tasks-3to4 dataset, which contains samples with 3 to 4 numbers and solutions.
As Model we are going to use Qwen/Qwen2.5-3B-Instruct which is a 3B parameter instruction tuned model. This makes it easier to showcase the "aha moment" as it already follows the prompt format. But you can use the base version of Qwen or other models as well. Jiayi-Pan explored that the model needs to have a certain quality to be able to learn the reasoning process, starting with > 1.5B parameters.
from transformers import AutoTokenizer
from datasets import load_dataset
# Load dataset from Hugging Face Hub
dataset_id = "Jiayi-Pan/Countdown-Tasks-3to4"
dataset = load_dataset(dataset_id, split="train")
# select a random subset of 50k samples
dataset = dataset.shuffle(seed=42).select(range(50000))
# Load tokenizer from Hugging Face Hub to format the dataset to our "r1" prompt
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-3B-Instruct")
# gemerate r1 prompt with a prefix for the model to already start with the thinking process
def generate_r1_prompt(numbers, target):
r1_prefix = [{
"role": "system",
"content": "You are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer."
},
{
"role": "user",
"content": f"Using the numbers {numbers}, create an equation that equals {target}. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final equation and answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 = 1 </answer>."
},
{
"role": "assistant",
"content": "Let me solve this step by step.\n<think>"
}]
return {"prompt": tokenizer.apply_chat_template(r1_prefix, tokenize=False, continue_final_message=True), "target": target}
# convert our dataset to the r1 prompt
dataset = dataset.map(lambda x: generate_r1_prompt(x["nums"], x["target"]))
# split the dataset into train and test
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
test_dataset = train_test_split["test"]3. Train the model using GRPO (Educational part)
Note: Section 3 is shows the basic on how to use TRL and GRPO. If you want to run the interactive cells you need to install bitsandbytes and peft as they are required for the Trainer class. This section is mostly for educational purposes.
TRL supports Group Relative Policy Optimization (GRPO) through a dedicated GRPOTrainer for aligning LLMs from preference data, as described in DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. The GRPOTrainer is a subclass of the Trainer from the transformers library and supports all the same features, including logging, checkpointing, distributed training, and parameter efficient fine-tuning (PEFT).
The GRPOTrainer supports generic Outcome Reward Models (ORM) and custom reward functions, that can be used to implement Rule-Based Reward Models. In the Deepseek R1 paper they implemented Rule-Based Reward Models to verify the correctness of the generated solutions. In our exmaple we are going to do a similar approach, where we will create 2 reward functions that:
- Format Reward: Checks if the generated format is correct
<think> [thinking] </think><answer> [answer] </answer> - Accuracy Reward: Extracts the equation from the
<answer>tag and evaluates it against the target and if every number is used once.
Note: Correct <answer> in our example includes the equation, for example <answer> 55 + 36 - 7 - 19 </answer>
import re
def format_reward_func(completions, target, **kwargs):
"""
Format: <think>...</think><answer>...</answer>
Args:
completions (list[str]): Generated outputs
target (list[str]): Expected answers
Returns:
list[float]: Reward scores
"""
rewards = []
for completion, gt in zip(completions, target):
try:
# add synthetic <think> as its already part of the prompt and prefilled for the assistant to more easily match the regex
completion = "<think>" + completion
# Check if the format is correct
regex = r"^<think>([^<]*(?:<(?!/?think>)[^<]*)*)<\/think>\n<answer>([\s\S]*?)<\/answer>$"
match = re.search(regex, completion, re.DOTALL)
# if the format is not correct, reward is 0
if match is None or len(match.groups()) != 2:
rewards.append(0.0)
else:
rewards.append(1.0)
except Exception:
rewards.append(0.0)
return rewards
def equation_reward_func(completions, target, nums, **kwargs):
"""
Evaluates completions based on:
2. Mathematical correctness of the answer
Args:
completions (list[str]): Generated outputs
target (list[str]): Expected answers
nums (list[str]): Available numbers
Returns:
list[float]: Reward scores
"""
rewards = []
for completion, gt, numbers in zip(completions, target, nums):
try:
# add synthetic <think> as its already part of the prompt and prefilled for the assistant to more easily match the regex
completion = "<think>" + completion
# Check if the format is correct
match = re.search(r"<answer>(.*?)<\/answer>", completion)
if match is None:
rewards.append(0.0)
continue
# Extract the "answer" part from the completion
equation = match.group(1).strip()
# Extract all numbers from the equation
used_numbers = [int(n) for n in re.findall(r'\d+', equation)]
# Check if all numbers are used exactly once
if sorted(used_numbers) != sorted(numbers):
rewards.append(0.0)
continue
# Define a regex pattern that only allows numbers, operators, parentheses, and whitespace
allowed_pattern = r'^[\d+\-*/().\s]+$'
if not re.match(allowed_pattern, equation):
rewards.append(0.0)
continue
# Evaluate the equation with restricted globals and locals
result = eval(equation, {"__builtins__": None}, {})
# Check if the equation is correct and matches the ground truth
if abs(float(result) - float(gt)) < 1e-5:
rewards.append(1.0)
else:
rewards.append(0.0)
except Exception:
# If evaluation fails, reward is 0
rewards.append(0.0)
return rewardsLets try our reward function with a sample.
Note: None of the example starts with <think> as we added it synthetically to the prompt.
correct_sample_1 = """We need to find an equation using the numbers 19, 36, 55, and 7
exactly once, with basic arithmetic operations, that equals 65. One possible
combination is 55 + 36 - 19 + 7... </think>
<answer> 55 + 36 - 7 - 19 </answer>"""
correct_sample_2 = """ ... </think>
<answer> 55 + 36 - 7 - 19 </answer>"""
wrong_format = """User: Using the numbers [19, 36, 55, 7], create an equation that equals 65."""
wrong_format_2 = """To find the equation that equals 79 using the numbers 95, 78, 6, 88, I'll start by adding 88 and 95:
95 + 88 = 183
Now, let's subtract 104 from 183 to get 79:
183 - 104 = 79
<think> 183 - 104 = 79 </think><think> 183 - 104 = 79 </think><answer> 183 - 104 = 79 </answer>"""
wrong_result = """ ... </think>
<answer> 55 + 36 - 7 - 18 </answer>"""
test_rewards = format_reward_func(completions=[correct_sample_1, correct_sample_2, wrong_format, wrong_format_2, wrong_result], target=["65", "65", "65", "65", "65"], nums=[[19, 36, 55, 7]] * 5)
assert test_rewards == [1.0, 1.0, 0.0, 0.0, 1.0], "Reward function is not working"
test_rewards = equation_reward_func(completions=[correct_sample_1, correct_sample_2, wrong_format, wrong_format_2, wrong_result], target=["65", "65", "65", "65", "65"], nums=[[19, 36, 55, 7]] * 5)
assert test_rewards == [1.0, 1.0, 0.0, 0.0, 0.0], "Reward function is not working"This looks good, now lets define our remaining training parameters, create a trainer and start training.
from trl import GRPOConfig, GRPOTrainer, get_peft_config, ModelConfig
# our model we are going to use as policy
model_config = ModelConfig(
model_name_or_path="Qwen/Qwen2.5-3B-Instruct",
torch_dtype="bfloat16",
attn_implementation="flash_attention_2",
use_peft=True,
load_in_4bit=True,
)
# Hyperparameters
training_args = GRPOConfig(
output_dir="qwen-r1-aha-moment",
learning_rate=5e-7,
lr_scheduler_type="cosine",
logging_steps=10,
max_steps=100,
per_device_train_batch_size=1,
gradient_accumulation_steps=1,
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
bf16=True,
# GRPO specific parameters
max_prompt_length=256,
max_completion_length=1024, # max length of the generated output for our solution
num_generations=2,
beta=0.001,
)
trainer = GRPOTrainer(
model=model_config.model_name_or_path,
reward_funcs=[format_reward_func, equation_reward_func],
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
peft_config=get_peft_config(model_config),
)We can start our training by calling the train method on the trainer instance.
Note: Reinforcement Training is very slow and compute intensive. Running a single step on 1x L4 with Q-LoRA, Batch size of 1 and only 2 generations per samples takes >20 minutes.
# Train and push the model to the Hub
trainer.train()
# Save model
trainer.save_model(training_args.output_dir)4. Distributed Training example for GRPO using Deepspeed and vLLM
More than 20 minutes per step with only 2 generations per sample is not feasible. We need to scale up our training. Hugging Face TRL added support for distributed training with Deepspeed and using vLLM for faster generation. I preprared a run_r1_grpo.py script and a receipes/grpo-qwen-2.5-3b-deepseek-r1-countdown.yaml config file to run the training.
This configuration is tested and validated on a Node with 4x H100 80GBs, where a single step takes around 45-60s, as we can leverage vLLM for generation and DeepSpeed for distributed training. Therefore we need to make sure we correctly set the num_processes to the number of GPUs you have - 1 as the last one will be used with vLLM for Generation. If you are using more GPUS you need to change the vllm_device in the config file to last index GPU, e.g. if you have 8 GPUs you need to set vllm_device=7 and your num_processes to 7.
command to run the training:
accelerate launch --num_processes 3 --config_file configs/accelerate_configs/deepspeed_zero3.yaml scripts/run_r1_grpo.py --config receipes/grpo-qwen-2.5-3b-deepseek-r1-countdown.yamlWith the optimized distributed training a single step with 8 generations per sample on 4x H100 80GBs takes around 45-60s. The full training for 450 steps takes around 6 hours.
5. Results and Training Observations
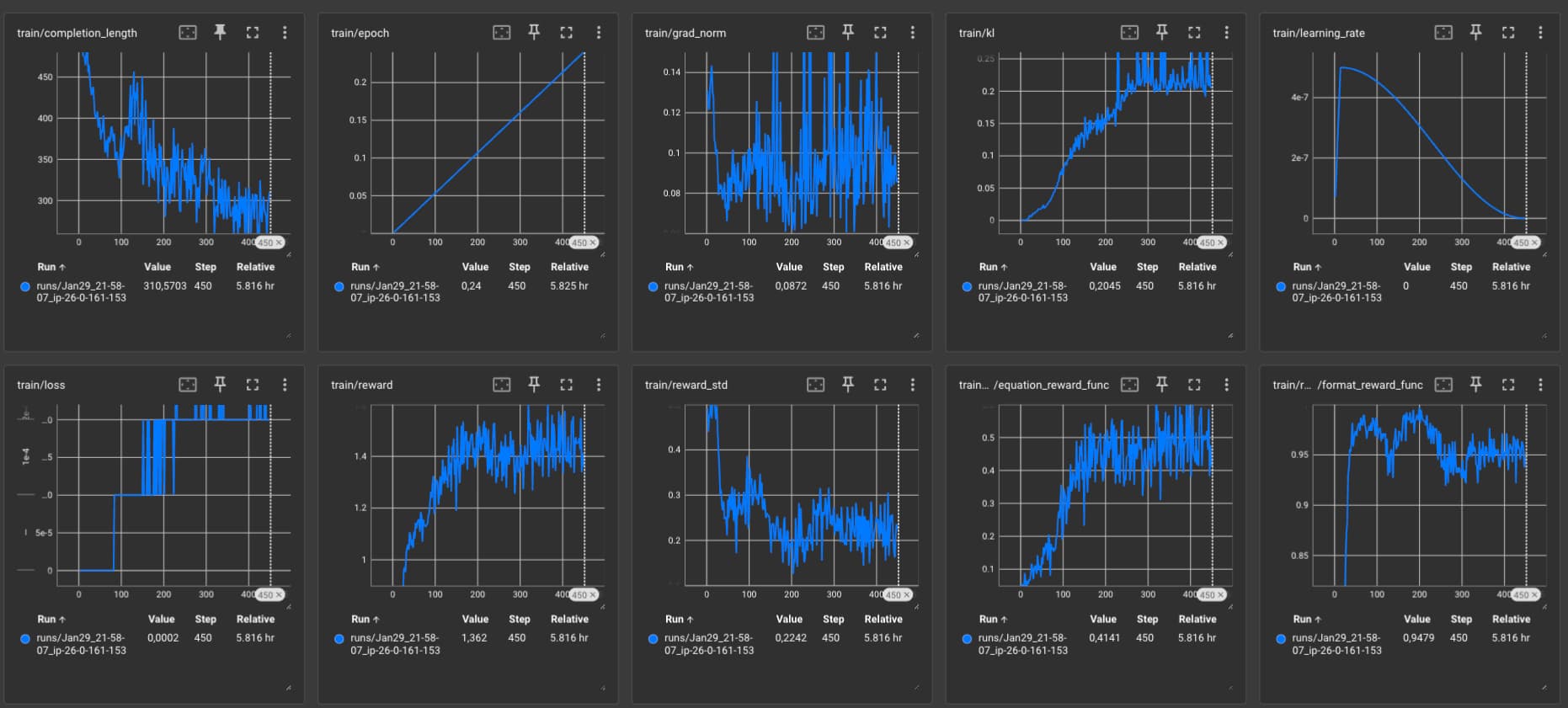
The script saves random completions to the completion_samples folder, which you can use to inspect the model's progress. It includes completion_samples.txt and success_completion_samples.txt. The completion_samples.txt includes all completions, while the success_completion_samples.txt which correctly solves the equation. Below you can find the interesating training obeserations on how the performance changes over time, as well as the Tensornoard logs and successfull reasoning samples.
The model with checkpoints for every 25th step can be found at philschmid/qwen-2.5-3b-r1-countdown.
Hyperparameters
I started the experiment using the hyperparameters from the DeepSeekMath paper with a learning rate of 1e-6 and a beta (KL coefficient) of 0.04, which led to unstable training runs after around 150 steps. I ran some small ablations and decreased both the learning rate to 5e-7 and the beta to 0.001, based on a test from OpenRLHF. I coulnd't test how increasing the num_generations from 8 to 64 would affect the training. 64 is the generation value, which was used in the DeepSeekMath paper. All other parameters can be found in the grpo-qwen-2.5-3b-deepseek-r1-countdown.yaml config file.
Training Observations:
- At ~50 steps the model has learned the correct format
<think>...</think>\n<answer>...</answer>. - At 100 steps the success rate for solving the equation is around 25%. The model starts to "reason" with words see examples below.
- At 200 steps the performance seems to converge much slower and we are at ~40% success rate. The model starts to learn a new "format" where it solves the equation similar to how you would do it programmatically, by trying different combinations and reviewing the results, see "Successfull Reasoning Samples between step 200 and 450".
- At 450 steps we have 50% success rate for solving the equation. The performance still improves slowly and the model kept its new format form from step 200.
I have 3 potential assumptions why the model shifts from "word reasoning" to "programmatic execution":
- Qwen 2.5 3B is not strong enough or to small, Deepseek mentions that you need a very strong base model.
- The reward functions are not good enough defined and it reward hacks the model to solve the equation. We could try to force it to use words, e.g. having a number to word frequency condition. (We don't know much about the reward functions from Deepseek)
- Only training on the Countdown Game tasks might force the model naturally to learn the most effective way to solve the equation as no other formats are required.
- We didn't train the model long enough, in the R1 paper they showed visuals of training for over 8000 steps.
Tensorboard Results
Successfull Reasoning Samples up to step 200
<think> First, I need to think about the numbers we have: 14, 70, and 80. To get 85, I think 80 might be a good starting point because it's right in between 85. If I subtract or add 80, it won't lead to 85 easily. Next, 70 seems to be a good intermediate number, especially to use in conjunction with 14.
Now, I can think about different combinations using addition, subtraction and multiplication/division. If I take 80 - 70 = 10, which is not needed. So, I need to find a way to use 14. If I subtract 14 from 80, I get 66, which still isn't 85. If I subtract 70 from 80, I get 10 again, this isn't constructive yet.
Multiplication could create numbers larger than the target 85. Let's consider division: If I divide 70 by 14, I get 5. Then if I add this result to 80, I get 85. This combination seems promising: 80 - (70 / 14) = 80 - 5 = 75, this still isn't quite right. Let me correct my approach: Let's use division and then addition. If I take 80 / (70 / 14) → 80 / 5 = 16, and then 80 - 16 = 64, still incorrect. Let me simplify: 80 / (70 / 14) → 80 / 5 = 16, and then 80 - 16 gives 64 again, let me correct: 80 - (70 / 14) → 80 - 5 = 75, but I need 85. Thus I will use the combinations in a slightly different order to insert numbers: I get 80 + (70 / 14) = 80 + 5 = 85</think>
<answer> 80 + (70 / 14) </answer><think> First, I need to consider how I can use the numbers 1, 21, and 90 to reach 68. I can try different combinations of operations. Let's try to use subtraction and addition. If I subtract 90 from 21, I get -69, which is too far from 68. Now, if I add 1 to 90, I get 91, which is also not right. Another way is to see what happens if I subtract 21 from 90, which gives me 69. This is closer but still not 68. Let me use multiplication instead of subtraction. 90 * 1 = 90. Now, if I try to reduce this slightly by subtracting 21, I am not getting close to 68.
Now, let's try another multiplication. I'll think of 1 * (larger value) + (smaller value). Let's try 1 * 90 + 21. This evaluates to 90 + 21 = 111, which is too much. Instead, I will try: 90 / 1 + 21 - 7. But this gives a division by 7, which seems complex. Let's re-evaluate: I'll use 1 to divide 21: 21 / 1 = 21. Now, subtract 21 from 90, and add 1, we have 90 - 21 = 69, using one...
Hey, wait on re-evaluating I will subtract 21 from 90, and include 1 to complete the solution: 90 - (21 + 1) which would be 68.</think>
<answer> 90 - (21 + 1) </answer><think> First, I need to consider the numbers we have: 59, 80, and 66. I need to use these numbers to get 45. Let's try to use subtraction first since it can quickly reduce large numbers.
Let's see if we can get close by subtracting or adding these numbers. If I subtract 66 from 80, I get 14. Then I need to make this 14 equal 45 when combined with 59. That gives me 14 + 59 = 73, which is too high.
Now let's try adding numbers. If I add 59 and 66, I get 125. Then I would need to subtract 80 from 125 to get 45, but 80 is too large to fit well with this.
Let me try a different approach. What if I subtract 66 from 80 first and then add 59? That would be 14 + 59 = 73, which is still not 45.
Hmm, I need to think of another combination. What if I start with 59 and then add 80 and subtract 66? That would be (59 + 80) - 66, let me calculate it. That equals 139 - 66, which is 73.
That's still not 45, so let me try rearranging it slightly: maybe 80 - 66 + 59 would be closer to 45. Calculating again: 80 - 66 is 14, then adding 59 gives 73.
This way doesn't work either. Let's flip this: maybe (59 + 66) - 80. Let me check: that's 125 - 80, which equals 45.</think>
<answer>(59 + 66) - 80</answer><think> First, I need to find a combination of the numbers 61, 4, 94, and 21 that can be manipulated using basic arithmetic operations to equal 50. One way to approach this is to look for numbers that can be used to reach a target number close to 50 and then adjust with the remaining numbers.
Let's try combining 94 and 21 first:
94 + 21 = 115
Now, we need to get from 115 to 50. We can try subtracting 65:
115 - 65 = 50
Now we need to find a way to get 65 using the remaining numbers 61 and 4. We can try:
61 - 4 = 57
Now we need to get from 57 to 65. Adding 8 would give us that:
57 + 8 = 65
So, we need to find a way to get 8 using 61 and 4. We can try:
61 - 94 = -36
This is negative, so let's try dividing:
61 / 94 = 0.648987...
This is not helping, so let's try multiplication and division in a different way:
(61 - 4) * (94 / 21) = 57 * 4.476... = 254.4
This is not working either. Let's try a different approach:
(94 - 61) = 33
Now we have:
33 + 21 = 54
We need to adjust from 54 to 50, so we can:
54 - 4 = 50
So, the equation becomes:
(94 - 61) + (21 - 4) = 50
</think>
<answer>(94 - 61) + (21 - 4)</answer><think> First, I'll consider the possibility of directly subtracting two numbers to get close to 31. If I subtract 57 from 63, I get 7. Now, if I subtract this 7 from 25, I get 25 - 7 = 18. Far from 31, so this doesn't work.
Next, let's try adding and subtracting. Dividing 63 by 25 will give a decimal, so that's unlikely to work. Now, let's see if adding and subtracting in another order could work. For example, let's try 63 - 25, and then we see this gets us 38. Now, we need a way to get to 31 from here. Subtracting 7 from 38 would work, but we can't figure out how to create that 7 from the given numbers.
Hmm, let me try to incorporate all numbers by adding and subtracting. If I try 63 + 25, I get 88. This is quite far from 31, but if 88 - 57, I get 31 exactly!
This seems to be the equation: 63 + 25 - 57 equals 31.
</think>
<answer> 63 + 25 - 57 </answer>Successfull Reasoning Samples between step 200 and 450
<think> We need to use the numbers 39, 16, and 55 with basic arithmetic operations to get 78. Let's try different combinations:
- 55 + 39 - 16 = 84 - 16 = 68 (too low)
- 55 + 16 - 39 = 71 - 39 = 32 (too low)
- 55 - 16 + 39 = 39 + 39 = 78 (this works)
So, the equation is 55 - 16 + 39 = 78. </think>
<answer> 55 - 16 + 39 </answer><think> We need to use the numbers 21, 5, and 40 with basic arithmetic operations to get 24. Let's try different combinations:
- 21 - 5 - 40 = -15
- 21 - 5 + 40 = 56
- 21 + 5 - 40 = -14
- 21 * 5 / 40 = 2.1 (not an integer, let's try another)
- 40 * 5 / 21 = 9.52 (not 24)
- 40 / 5 - 21 = 9 - 21 = -12
- 5 * 40 / 21 = 100 / 21 ~= 4.76 (not 24)
- 5 + 40 - 21 = 24 ! This works.
</think>
<answer> 5 + 40 - 21 </answer><think> We need to use the numbers 75, 99, 62, and 34 with basic arithmetic operations to get 72. Let's try different combinations:
- 99 - 75 + 62 - 34 = 92 - 34 = 58 (too high)
- 99 - 75 - 62 + 34 = 24 - 62 + 34 = -38 + 34 = -4 (too low)
- 99 + 75 - 62 - 34 = 174 - 96 = 78 (too high)
- 99 + 75 - 62 + 34 = 174 + 34 - 62 = 208 - 62 = 146 (too high)
- 99 - 75 + 62 + 34 = 24 + 96 = 120 (too high)
- 75 + 99 - 62 - 34 = 174 - 96 = 78 (too high)
- 75 + 99 - 62 + 34 = 174 + 34 - 62 = 208 - 62 = 146 (too high)
- 75 + 62 - 99 + 34 = 137 - 99 + 34 = 38 + 34 = 72
So, 75 + 62 - 99 + 34 equals 72.
</think>
<answer> 75 + 62 - 99 + 34 </answer>Conclusion
The release of DeepSeek R1 and its research paper might be breakpoint for the open-science and open-source development. Just a week after DeepSeek release, we've been able to reproduce a simple version of R1 learned "reasoning" using GRPO and the Countdown Game. While our implementation focuses on a specific task rather than general reasoning and convergence into a very specific "reasoning" format, it shows that the method is working.
In our mini R1 experiment we used GRPO, with two rule-based reward but already required significant compute: 4 H100 GPUs running for 6 hours to complete just 450 training steps on a 3B parameter model. This gives us an idea of the compute needs that you will need to scale Reinforcement Learning. Deepseek ran a 671B model for over 8000 steps and they probably did many ablations.
Looking in to 2025, it's clear that we are on the cusp of even more significant progress. RL will become more accessible and user-friendly, more researchers and developers will explore its potential, but also require amount of more compute as before and compared to supervised fine-tuning.
I am excited for 2025. If you are have any question or ideas feel free to reach out to me.