LLM Evaluation doesn't need to be complicated
Generative AI and large language models (LLMs) like GPT-4, Llama, and Claude have pathed a new era of AI-driven applications and use cases. However, evaluating LLMs can often feel daunting or confusing with many complex libraries and methodologies, It can easily get overwhelming.
LLM Evaluation doesn't need to be complicated. You don't need complex pipelines, databases or infrastructure components to get started building an effective evaluation pipeline.
A great example of this comes from Discord, which built a chatbot for 20M users. Discord focused on implementing evaluations that were easy to run and quick to implement. One clever technique they used was to check if a message was all lowercase to determine if the chatbot was being used casually or in another way.
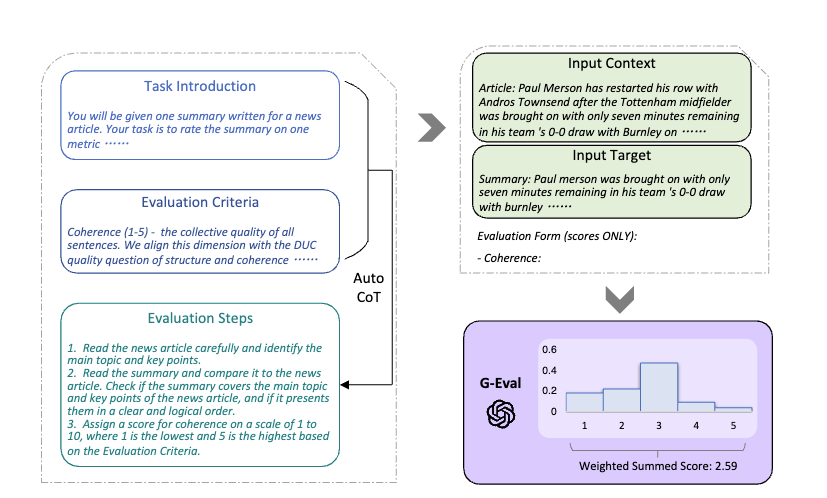
In this blog post, we will learn how to set up a simplified evaluation workflow for your LLM applications. Inspired by G-EVAL and Self-Rewarding Language Models, we will use an additive score, chain-of-thought (CoT), and form-filling prompt templates with few-shot examples to guide the evaluation. This method aligns well with human judgments and makes the evaluation process understandable, effective, and easy to manage.
As LLM Judge we will use meta-llama/Meta-Llama-3-70B-Instruct hosted through Hugging Face Inference API with the OpenAI client. You can also use other LLMs.
How to create a good evaluation prompt for LLM as a Judge
When using LLM as a Judge for evaluation, the prompt you use to assess the quality of your model is the most important part. The following recommendations are based on practical experience and insights from recent research, particularly the G-EVAL paper and the Self-Rewarding Language Models paper.
1. Define a Clear Evaluation Metric (Optional: Additive Score)
Start by establishing a clear metric for your evaluation and break it down into specific criteria using, for example, an additive score. This approach enhances consistency and can align better with human judgment using few-shot examples. For example:
- Add 1 point if the answer directly addresses the main topic of the question without straying into unrelated areas.
- Award a point if answer is appropriate for educational use and introduces key concepts for learning coding.
- …
Using a small integer scale (0-5) simplifies the scoring process and reduces variability in the LLM's judgments.
2. Define Chain-of-Thought (CoT) Evaluation Steps
Define predefined reasoning steps for the LLM to apply a step-by-step evaluation process. This leads to a more thoughtful and accurate evaluation. For example:
- Read the question carefully to understand what is being asked.
- Read the answer thoroughly.
- Assess the length of the answer. Is it unnecessarily long or appropriately brief?
- …
3. Include Few-Shot Examples (Optional)
Adding examples of questions, responses, reasoning steps, and their evaluations can help guide the LLM more closely to human preferences and improve its robustness.
4. Define Output Schema
Request the evaluation results in a structured format (e.g., JSON) with fields for each criterion and the total score. This allows you to parse the results and calculate the metrics automatically. It can be improved by providing a few shot examples.
Here is an example of how this would look if you put it all together.
EVALUATION_PROMPT_TEMPLATE = """
You are an expert judge evaluating the Retrieval Augmented Generation applications. Your task is to evaluate a given answer based on a context and question using the criteria provided below.
Evaluation Criteria (Additive Score, 0-5):
{additive_criteria}
Evaluation Steps:
{evaluation_steps}
Output format:
{json_schema}
Examples:
{examples}
Now, please evaluate the following:
Question:
{question}
Context:
{context}
Answer:
{answer}
"""Use an LLM as a Judge to evaluate an RAG application
Retrieval Augmented Generation (RAG) is one of the most popular use cases for LLMs, but it is also one of the most difficult to evaluate. There are common metrics for RAG, but they might not always fit the use case or are to “generic”. We define a new RAG additive metric (3-Point Scale)
This 3-point additive metric evaluates RAG system responses based on their adherence to the given context, completeness in addressing all key elements, and relevance combined with conciseness.
Note: This is a completely made-up metric for demonstration purposes only. It is important you define the metrics and criteria based on your use case and importance.
To evaluate our model, we need to define the additive_criteria, evaluation_steps, json_schema.
ADDITIVE_CRITERIA = """1. Context: Award 1 point if the answer uses only information provided in the context, without introducing external or fabricated details.
2. Completeness: Add 1 point if the answer addresses all key elements of the question based on the available context, without omissions.
3. Conciseness: Add a final point if the answer uses the fewest words possible to address the question and avoids redundancy."""
EVALUATION_STEPS="""1. Read provided context, question and answer carefully.
2. Go through each evaluation criterion one by one and assess whether the answer meets the criteria.
3. Compose your reasoning for each critera, explaining why you did or did not award a point. You can only award full points.
4. Calculate the total score by summing the points awarded.
5. Format your evaluation response according to the specified Output format, ensuring proper JSON syntax with a "reasoning" field for your step-by-step explanation and a "total_score" field for the calculated total. Review your formatted response. It needs to be valid JSON."""
JSON_SCHEMA="""{
"reasoning": "Your step-by-step explanation for the Evaluation Criteria, why you awarded a point or not."
"total_score": sum of criteria scores,
}"""
def format_examples(examples):
return "\n".join([
f'Question: {ex["question"]}\nContext: {ex["context"]}\nAnswer: {ex["answer"]}\nEvaluation:{ex["eval"]}'
for ex in examples
])To help improve the model's performance, we define three few-shot examples: a 0-score example, a 1-score example, and a 3-score example. You can find them in the dataset repository. For the evaluation data, we will use a synthetic dataset from the **2023_10 NVIDIA SEC Filings.** This dataset includes a question, answer, and context. We are going to evaluate 50 random samples to see how well the answer performs based on our defined metric.
We are going to use the async client AsyncOpenAI client to score multiple examples in parallel.
import asyncio
from openai import AsyncOpenAI
import huggingface_hub
from tqdm.asyncio import tqdm_asyncio
# max concurrency
sem = asyncio.Semaphore(5)
# Initialize the client using the Hugging Face Inference API
client = AsyncOpenAI(
base_url="https://api-inference.huggingface.co/v1/",
api_key=huggingface_hub.get_token(),
)
# Combined async helper method to handle concurrent scoring and
async def limited_get_score(dataset):
async def gen(sample):
async with sem:
res = await get_eval_score(sample)
progress_bar.update(1)
return res
progress_bar = tqdm_asyncio(total=len(dataset), desc="Scoring", unit="sample")
tasks = [gen(text) for text in dataset]
responses = await tqdm_asyncio.gather(*tasks)
progress_bar.close()
return responses
Then, we define our get_eval_score method.
import json
async def get_eval_score(sample):
prompt = EVALUATION_PROMPT_TEMPLATE.format(
additive_criteria=ADDITIVE_CRITERIA,
evaluation_steps=EVALUATION_STEPS,
json_schema=JSON_SCHEMA,
examples=format_examples(few_shot_examples),
question=sample["question"],
context=sample["context"],
answer=sample["answer"]
)
# Comment in if you want to see the prompt
# print(prompt)
response = await client.chat.completions.create(
model="meta-llama/Meta-Llama-3-70B-Instruct",
messages=[{"role": "user", "content": prompt}],
temperature=0,
max_tokens=512,
)
results = response.choices[0].message.content
# Add the evaluation results to the sample
return {**sample, **json.loads(results)}
The last missing piece is the data. We use the datasets library to load our samples.
from datasets import load_dataset
eval_ds = load_dataset("zeitgeist-ai/financial-rag-nvidia-sec", split="train").shuffle(seed=42).select(range(50))
print(f"Limited evaluation of {len(eval_ds)} samples")
few_shot_examples = load_dataset("zeitgeist-ai/financial-rag-nvidia-sec","few-shot-examples" ,split="train")
print(f"Limited evaluation of {len(few_shot_examples)} few-shot examples")Let's test an example.
import json
sample = [sample for sample in eval_ds.select(range(1))]
print(f"Question: {sample[0]['question']}\nContext: {sample[0]['context']}\nAnswer: {sample[0]['answer']}")
print("---" * 10)
# change in if you are not in a jupyter notebook
# responses = asyncio.run(limited_get_score(sample))
responses = await limited_get_score(sample)
print(f"Reasoing: {responses[0]['reasoning']}\nTotal Score: {responses[0]['total_score']}")Awesome, it works and looks good now. Let's evaluate all 50 examples and then calculate our average score.
results = await limited_get_score(eval_ds)
# Scoring: 80%|████████ | 40/50 [00:22<00:04, 2.36sample/s]
# calculate the average score
total_score = sum([r["total_score"] for r in results]) / len(results)
print(f"Average Score: {total_score}")
# extract and sample with score 0
score_0 = [r for r in results if r["total_score"] == 0]
print(f"Samples with score 0: {len(score_0)}")Great. We achieved and average score of 2.78! To better understand why only 2.78 lets look at an example which scored poorly and if that's correct.
# extract and sample with score 0
score_0 = [r for r in results if r["total_score"] == 0]
print(f"Samples with score 0: {len(score_0)}")
# Samples with score 0: 2In my test, I got 2 samples with a score of 0. Lets look at the first.
print(f"Question: {score_0[0]['question']}\nContext: {score_0[0]['context']}\nAnswer: {score_0[0]['answer']}")
print("---" * 10)
print(f"Reasoing: {score_0[0]['reasoning']}\nTotal Score: {score_0[0]['total_score']}")
# Question: What was the total dollar value of outstanding commercial real estate loans at the end of 2023?
# Context: The total outstanding commercial real estate loans amounted to $72,878 million at the end of December 2022.
# Answer: $72.878 billion
# ------------------------------
# Reasoning: 1. Context: The answer does not use the correct information from the provided context. The context mentions the total outstanding commercial real estate loans at the end of December 2022, but the answer provides a value without specifying the correct year. Therefore, no points are awarded for context.
# 2. Completeness: The answer provides a dollar value, but it does not address the key element of the question, which is the total dollar value at the end of 2023. The context only provides information about 2022, and the answer does not clarify or provide the correct information for 2023. Thus, no points are awarded for completeness.
# 3. Conciseness: The answer is concise, but it does not address the correct question. If the answer had provided a value with a clear statement that the information is not available for 2023, it would have been more accurate. However, in this case, the answer is concise but incorrect.
# Total Score: 0Wow. Our LLM judge correctly identified that the question asked for 2023, but the context only provided information about 2022. Additionally, we see that the completeness and conciseness criteria really rely heavily on context. Depending on your needs, there could be room for improvements in our prompt.
Limitations
LLM, as a Judge, can have a bias toward preferring LLM-generated texts over human-written texts. This can be mitigated with good few-shot examples generated by human experts.
Your prompt and predefined steps and criteria are crucial for your results and may not align perfectly with every use case. The G-EVAL and Self-Rewarding Language Models papers highlight more examples of how prompts can be fine-tuned for better alignment.
Using LLMs as judges comes with limitations. One key issue is the potential for bias and inconsistency in their evaluations. The predefined steps and criteria we use may not align perfectly with every use case, requiring adjustments. The G-EVAL and Self-Rewarding Language Models papers highlight more examples of how prompts can be fine-tuned for better alignment.
Moreover, the additive score, while simple and effective, might not work in all scenarios. Sometimes, a simple boolean check (correct/incorrect) might be enough.
Lastly, don’t forget your judge's context window. If your prompt exceeds the window, it might make evaluation difficult.
Conclusion
Remember, this is a starting point. As you use this template in your system, you may need to refine and adjust it based on your specific needs. Using human-labeled few-shot examples allows you to align your LLM Judge with a human expert at almost 0 cost.
The key is to start simple, iterate, and refine your approach. And always look at your data. Evaluation is not something you do only once.
I can also recommend reading Hamels Your AI Product Needs Evals blog.
Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.