Introducing IGEL an instruction-tuned German large Language Model
IGEL is an LLM model family developed for German. The first version of IGEL is built on top BigScience BLOOM, adapted to German from Malte Ostendorff. IGEL is designed to provide accurate and reliable language understanding capabilities for a wide range of natural language understanding tasks, including sentiment analysis, language translation, and question answering.
You can try out the model at igel-playground.
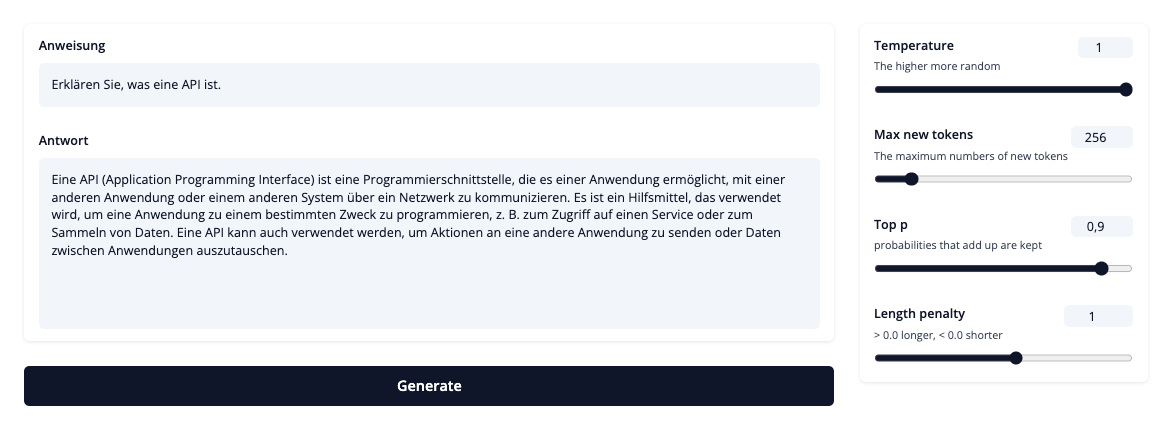
The IGEL family currently includes instruct-igel-001 and chat-igel-001 (coming soon).
Model Description
The 001 version of IGEL is designed as a naive proof of concept to determine whether it is possible to create a German instruction-tuned model using a set of available open-source models and German translated instruction dataset. The goal is to explore the potential of the LLMs for German language modeling tasks that require instruction-based responses.
To achieve this goal, we used a pre-trained adapted BLOOM model (6B) and fine-tuned it using the translated instruction-based dataset. The dataset was created by taking instructions in English and translating them into German using an automated translation tool. While this approach may introduce errors in the translated content, we wanted to test whether the model could still learn to generate instruction-based responses.
We are pleased to announce that we had success. 🥳 Instruct-igel-001 is LoRA-tuned BLOOM-CLP German (6.4B parameters) with merged weights to make it is to load and use with Hugging Face Transformers.
Samples
You can test out the model for free on Hugging Face: https://huggingface.co/spaces/philschmid/igel-playground
Or you can download the model and run it using transformers: philschmid/instruct-igel-001
Question Answering

Content Generation
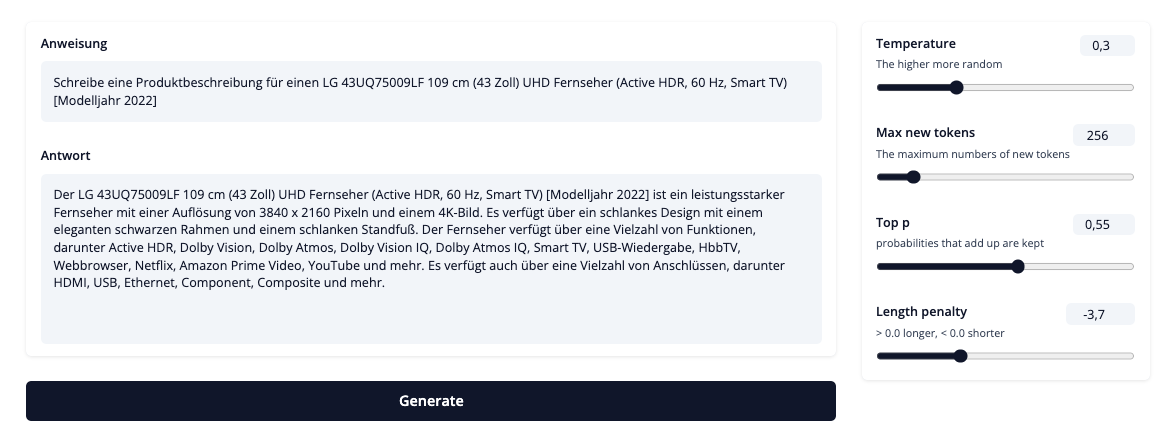
Product description
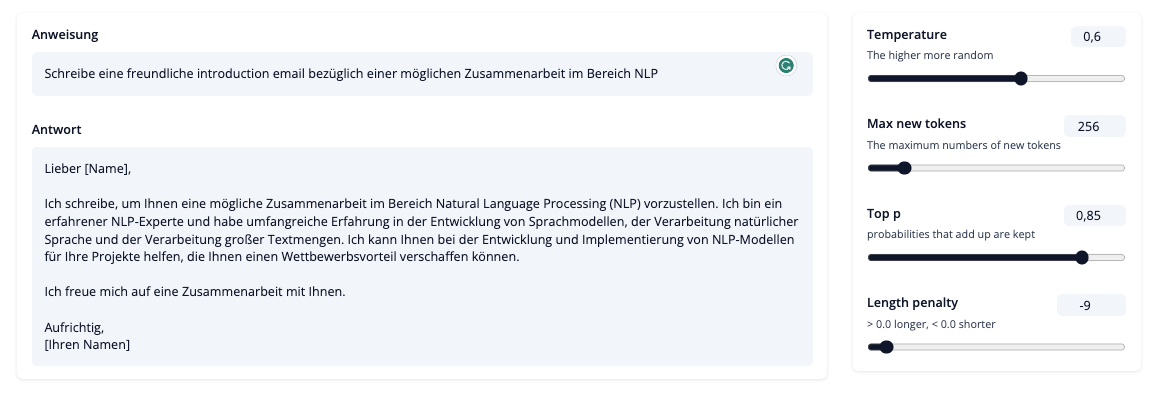
Marketing email
How to use the model
The model is available on Hugging face at philschmid/instruct-igel-001.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# load model
tokenizer = AutoTokenizer.from_pretrained("philschmid/instruct-igel-001")
model = AutoModelForCausalLM.from_pretrained("philschmid/instruct-igel-001")
# load pipeline
generator = pipeline("text-generation",model=model,tokenizer=tokenizer)
# run generation
generator("### Anweisung:\n{{input}}\n\n### Antwort:")Training data
instruct-igel-001 is trained on naive translated instruction datasets without much any data-cleaning, filtering, or post-processing.
Known limitations
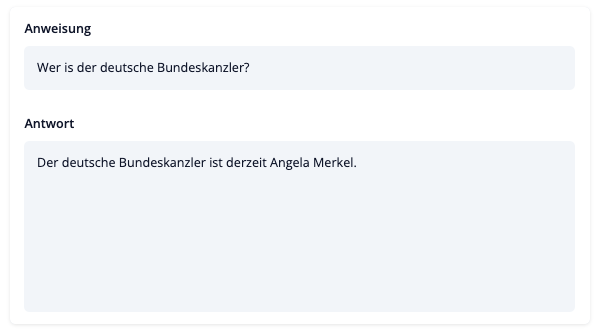
instruct-igel-001 also exhibits several common deficiencies of language models, including hallucination, toxicity, and stereotypes.
For example, in the following figure, instruct-igel-001 wrongly says that the chancellor of Germany is Angela Merkel.
Next Steps
The next steps are to finish the chat model to have a conversational interface, which goes beyond a simple request-response concept and improves the data quality.
If you are interested in collaborating or improving IGEL's capabilities or would like to learn how you can adapt and improve IGEL for your company’s needs, please contact me via email, Twitter, or LinkedIn.