Agents: Inner Loop vs Outer Loop
When people talk about AI agents "closing the loop," they usually mean the agent verifies its own work before responding, which can be confusing as "If the tool call loop is hardcoded, how does the model decide to verify its work?"
Short answer: The loop is hardcoded. What the model does inside the loop is not.
Every agent framework runs roughly the same cycle: model generates → if tool call, execute it → feed result back → model generates again → repeat until the model returns text (no more tool calls). That loop is scaffolding. It's the same for every agent.
The difference is what the model chooses to do within that loop. A model that "closes the loop" doesn't need a special loop, it uses the existing one to call verification tools before deciding it's done.
The inner loop: agent verifies its own work
The inner loop is what happens during a single task, before the agent responds to user with a text. The agent writes code, runs the tests, reads the error, fixes the edge case, re-runs and only then generates a text response for the user. It's the tight feedback cycle between the model and its tools.
Example: You ask "fix the failing test in auth.ts."
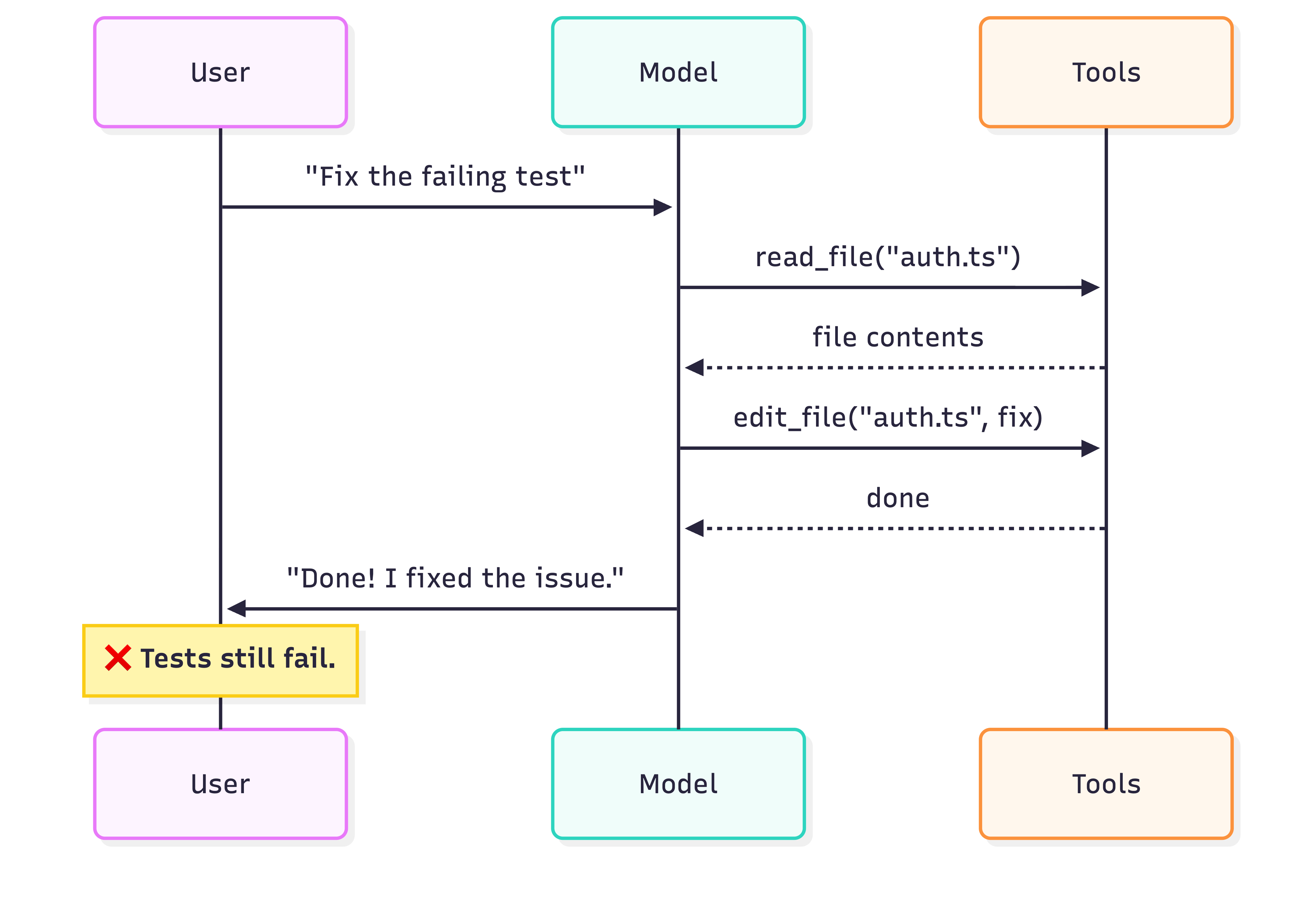
A weak agent edits the file and says "Done!" A strong agent edits → creates tests → runs the tests → sees a failure → fixes the edge case → runs again → sees green → then responds. Same infrastructure, different behavior.
Bad agent — edits and stops:
Good agent — verifies before responding:
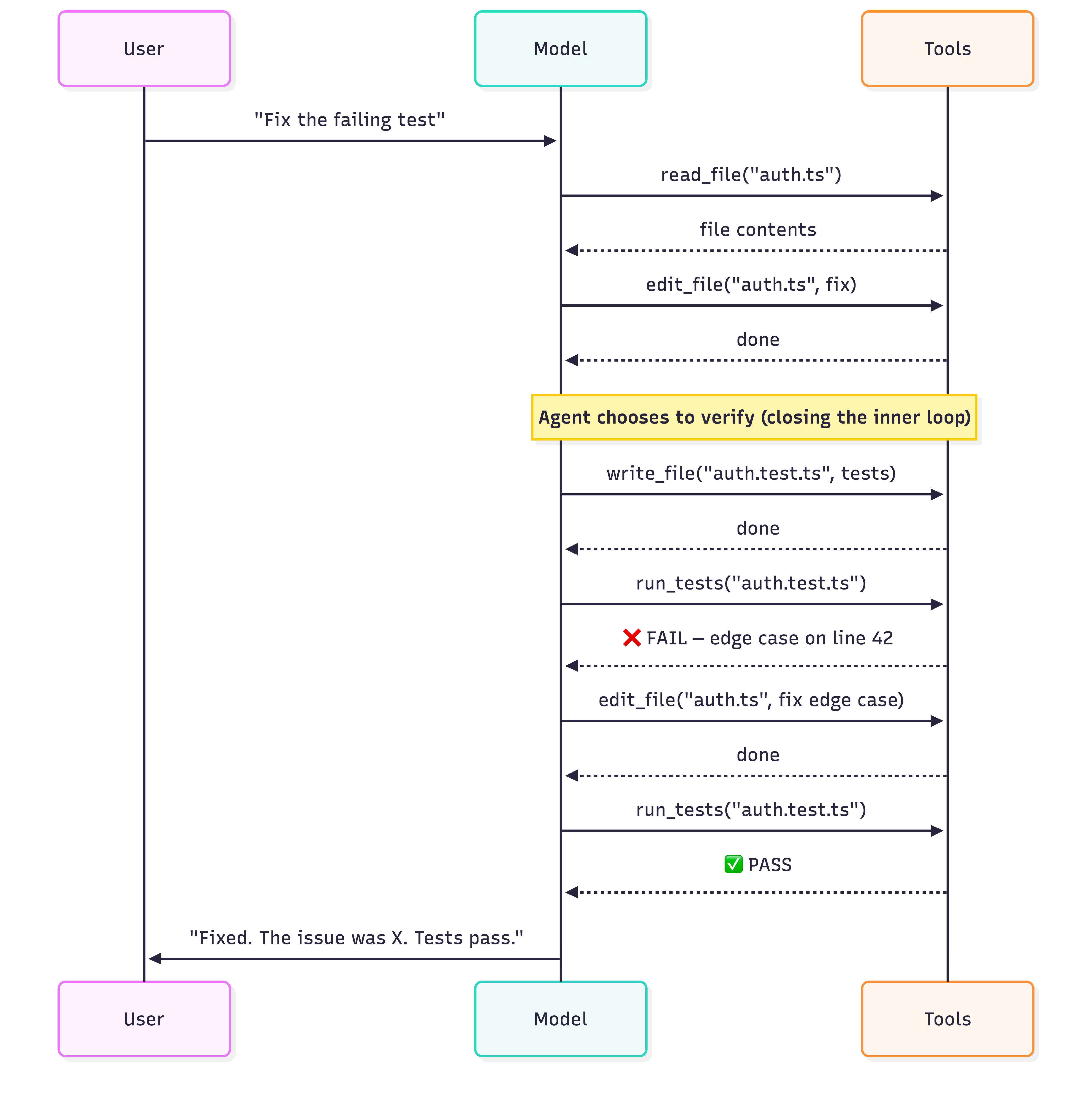
Both agents use the exact same hardcoded tool loop. The difference is the good agent chose to create/call verfications before responding. Nothing forced it to.
Where does that choice come from? Today, mostly from the system prompt ("always run tests after code changes"). Increasingly, from post-training — e.g. test pass/fail as a reward signal, so the model internalizes the verify step.
The outer loop: learning across turns
The outer loop is what happens across multiple turns/sessions between the user and the agent over time. The user gives the agent a task, it works on it (inner loop), returns a result, and then the user comes back with the next task. The question is: did the agent learn anything from the last turn?
Without persistent memory, every turn is a clean slate. The agent that failed on pagination yesterday will fail on it again today.
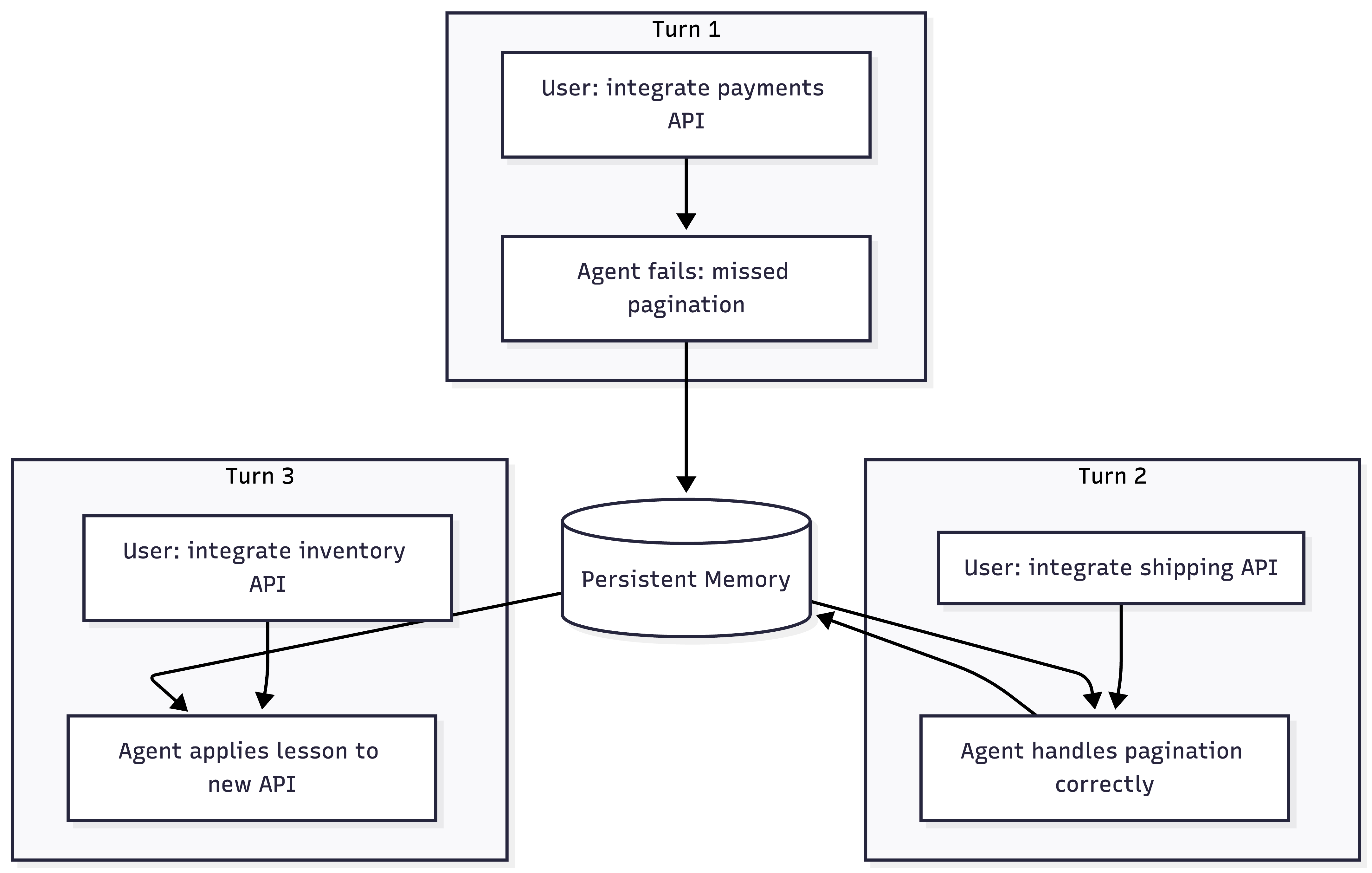
Almost no agent does this natively today. The outer loop requires persistent state, skills, rules files, or notes that survive between turns and sessions. Some early examples:
- AGENTS.md: Manual persistent instructions the user writes for future turns
- Session handoff documents: Structured summaries an agent writes for follow-up work
- SKILL.md: Agent analyzes failures and auto-generates Skills so the next task doesn't repeat mistakes
The inner loop is about reliability within a task. The outer loop is about getting smarter over time.
TL;DR
- The loop is hardcoded. Every agent has the same generate → tool call → feed back cycle.
- What the agent does inside the loop is learned. A good agent calls verification tools before responding. A weak one just stops.
- Inner loop = verify within a task (write tests, run them, read files back, check against original ask).
- Outer loop = carry lessons across turns (persistent memory, skills, rules files).
- Closing the loop ≠ new infrastructure. It's the agent making better decisions within existing infrastructure.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.