Deploy Embedding Models on AWS inferentia2 with Amazon SageMaker
In this end-to-end tutorial, you will learn how to deploy and speed up Embeddings Model inference using AWS Inferentia2 and optimum-neuron on Amazon SageMaker. Optimum Neuron is the interface between the Hugging Face Transformers & Diffusers library and AWS Accelerators including AWS Trainium and AWS Inferentia2.
You will learn how to:
- Convert Embeddings Model to AWS Neuron (Inferentia2) with
optimum-neuron - Create a custom
inference.pyscript forembeddings - Upload the neuron model and inference script to Amazon S3
- Deploy a Real-time Inference Endpoint on Amazon SageMaker
- Run and evaluate Inference performance of Embeddings Model on Inferentia2
Let's get started! 🚀
If you are going to use Sagemaker in a local environment (not SageMaker Studio or Notebook Instances). You need access to an IAM Role with the required permissions for Sagemaker. You can find here more about it.
1. Convert Embeddings Model to AWS Neuron (Inferentia2) with optimum-neuron
We are going to use the optimum-neuron. 🤗 Optimum Neuron is the interface between the 🤗 Transformers library and AWS Accelerators including AWS Trainium and AWS Inferentia. It provides a set of tools enabling easy model loading, training and inference on single- and multi-Accelerator settings for different downstream tasks.
As a first step, we need to install the optimum-neuron and other required packages.
Tip: If you are using Amazon SageMaker Notebook Instances or Studio you can go with the conda_python3 conda kernel.
# Install the required packages
%pip install "optimum-neuron[neuronx]==0.0.14" --upgrade
%pip install "sagemaker>=2.197.0" --upgrade
# restart your kernelAfter we have installed the optimum-neuron we can convert load and convert our model.
We are going to use the BAAI/bge-base-en-v1.5 model. BGE Base is a fine-tuned BERT model to map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search. It works perfectly for vector databases for LLMs. The base model is the perfect trade-off between size and performance, it is currently ranked top 5 on the MTEB Leaderboard.
At the time of writing, the AWS Inferentia2 does not support dynamic shapes for inference, which means that the input size needs to be static for compiling and inference.
In simpler terms, this means we need to define the input shapes for our prompt (sequence length), batch size, height and width of the image.
We precompiled the model with the following parameters and pushed it to the Hugging Face Hub:
sequence_length: 384batch_size: 1neuron: 2.15.0
Note: If you want to compile your own model, comment in the code below and change the model id. We used an inf2.8xlarge ec2 instance with the Hugging Face Neuron Deep Learning AMI to compile the model.
from huggingface_hub import snapshot_download
# compiled model id
compiled_model_id = "aws-neuron/bge-base-en-v1-5-seqlen-384-bs-1"
# save compiled model to local directory
save_directory = "embedding_model"
# Downloads our compiled model from the HuggingFace Hub
# using the revision as neuron version reference
# and makes sure we exlcude the symlink files and "hidden" files, like .DS_Store, .gitignore, etc.
snapshot_download(compiled_model_id, revision="2.15.0", local_dir=save_directory, local_dir_use_symlinks=False, allow_patterns=["[!.]*.*"])
###############################################
# COMMENT IN BELOW TO COMPILE DIFFERENT MODEL #
###############################################
# from optimum.neuron import NeuronModelForFeatureExtraction
# from transformers import AutoTokenizer
# # model id you want to compile
# vanilla_model_id = "BAAI/bge-base-en-v1.5"
# # configs for compiling model
# input_shapes = {
# "sequence_length": 384, # max length of the document (max 512)
# "batch_size": 1 # batch size for the model
# }
# emb = NeuronModelForFeatureExtraction.from_pretrained(vanilla_model_id, export=True, **input_shapes)
# tokenizer = AutoTokenizer.from_pretrained(vanilla_model_id)
# # Save locally or upload to the HuggingFace Hub
# save_directory = "embedding_model"
# emb.save_pretrained(save_directory)
# tokenizer.save_pretrained(save_directory)2. Create a custom inference.py script for embeddings
The Hugging Face Inference Toolkit supports zero-code deployments on top of the pipeline feature from 🤗 Transformers. This allows users to deploy Hugging Face transformers without an inference script [Example].
Currently is this feature not supported with AWS Inferentia2, which means we need to provide an inference.py for running inference. But optimum-neuron has integrated support for the 🤗 Transformers pipeline feature. That way we can use the optimum-neuron to create a pipeline for our model.
If you want to know more about the inference.py script check out this example. It explains amongst other things what the model_fn and predict_fn are.
!mkdir {save_directory}/codeWe are using the NEURON_RT_NUM_CORES=1 to make sure that each HTTP worker uses 1 Neuron core to maximize throughput.
%%writefile {save_directory}/code/inference.py
import os
# To use one neuron core per worker
os.environ["NEURON_RT_NUM_CORES"] = "1"
from optimum.neuron import NeuronModelForFeatureExtraction
from transformers import AutoTokenizer
import torch
import torch_neuronx
def model_fn(model_dir):
# load local converted model and tokenizer
model = NeuronModelForFeatureExtraction.from_pretrained(model_dir)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
return model, tokenizer
def predict_fn(data, pipeline):
model, tokenizer = pipeline
# extract body
inputs = data.pop("inputs", data)
# Tokenize sentences
encoded_input = tokenizer(inputs,return_tensors="pt",truncation=True,max_length=model.config.neuron["static_sequence_length"])
# Compute embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
return {"embeddings":sentence_embeddings[0].tolist()}3. Upload the neuron model and inference script to Amazon S3
Before we can deploy our neuron model to Amazon SageMaker we need to create a model.tar.gz archive with all our model artifacts saved into, e.g. model.neuron and upload this to Amazon S3.
To do this we need to set up our permissions. Currently inf2 instances are only available in the us-east-2 region [REF]. Therefore we need to force the region to us-east-2.
import os
os.environ["AWS_DEFAULT_REGION"] = "us-east-2" # need to set to ohio regionNow lets create our SageMaker session and upload our model to Amazon S3.
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
assert sess.boto_region_name == "us-east-2", "region must be us-east-2"Next, we create our model.tar.gz. The inference.py script will be placed into a code/ folder.
# create a model.tar.gz archive with all the model artifacts and the inference.py script.
%cd {save_directory}
!tar zcvf model.tar.gz *
%cd ..Now we can upload our model.tar.gz to our session S3 bucket with sagemaker.
from sagemaker.s3 import S3Uploader
# create s3 uri
s3_model_path = f"s3://{sess.default_bucket()}/neuronx/embeddings"
# upload model.tar.gz
s3_model_uri = S3Uploader.upload(local_path=f"{save_directory}/model.tar.gz",desired_s3_uri=s3_model_path)
print(f"model artifcats uploaded to {s3_model_uri}")4. Deploy a Real-time Inference Endpoint on Amazon SageMaker
After we have uploaded our model.tar.gz to Amazon S3 can we create a custom HuggingfaceModel. This class will be used to create and deploy our real-time inference endpoint on Amazon SageMaker.
The inf2.xlarge instance type is the smallest instance type with AWS Inferentia2 support. It comes with 1 Inferentia2 chip with 2 Neuron Cores. This means we can use 2 Model server workers to maximize throughput and run 2 inferences in parallel.
from sagemaker.huggingface.model import HuggingFaceModel
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_model_uri, # path to your model.tar.gz on s3
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.34.1", # transformers version used
pytorch_version="1.13.1", # pytorch version used
py_version='py310', # python version used
model_server_workers=2, # number of workers for the model server
)
# deploy the endpoint endpoint
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type="ml.inf2.xlarge", # AWS Inferentia Instance
volume_size = 100
)
# ignore the "Your model is not compiled. Please compile your model before using Inferentia." warning, we already compiled our model.5. Run and evaluate Inference performance of Embeddings Model on Inferentia2
The .deploy() returns an HuggingFacePredictor object which can be used to request inference.
data = {
"inputs": "the mesmerizing performances of the leads keep the film grounded and keep the audience riveted .",
}
res = predictor.predict(data=data)
# print some results
print(f"lenght of embeddings: {len(res['embeddings'])}")
print(f"first 10 elements of embeddings: {res['embeddings'][:10]}")Awesome we can now generate embeddings with our model, Lets test the performance of our model.
A load test will we send 10,000 requests to our endpoint use threading with 10 concurrent threads. We will measure the average latency and throughput of our endpoint. We are going to sent an input of 300 tokens to have a total of 3 Million tokens, but remember the model is compiled with a sequence_length of 384. This means that the model will pad the input to 384 tokens, this increases the latency a bit.
We decided to use 300 tokens as input length to find the balance between shorter inputs which are padded and longer inputs, which are truncated. If you know your chunk size, we recommend to compile the model with that length to get maximum performance.
Note: When running the load test, the requests are sent from europe and the endpoint is deployed in us-east-2. This adds a network overhead to it.
import threading
import time
number_of_threads = 10
number_of_requests = int(10000 // number_of_threads)
print(f"number of threads: {number_of_threads}")
print(f"number of requests per thread: {number_of_requests}")
def send_rquests():
for _ in range(number_of_requests):
# input counted at https://huggingface.co/spaces/Xenova/the-tokenizer-playground for 100 tokens
predictor.predict(data={"inputs": "Hugging Face is a company and a popular platform in the field of natural language processing (NLP) and machine learning. They are known for their contributions to the development of state-of-the-art models for various NLP tasks and for providing a platform that facilitates the sharing and usage of pre-trained models. One of the key offerings from Hugging Face is the Transformers library, which is an open-source library for working with a variety of pre-trained transformer models, including those for text generation, translation, summarization, question answering, and more. The library is widely used in the research and development of NLP applications and is supported by a large and active community. Hugging Face also provides a model hub where users can discover, share, and download pre-trained models. Additionally, they offer tools and frameworks to make it easier for developers to integrate and use these models in their own projects. The company has played a significant role in advancing the field of NLP and making cutting-edge models more accessible to the broader community."})
# Create multiple threads
threads = [threading.Thread(target=send_rquests) for _ in range(number_of_threads) ]
# start all threads
start = time.time()
[t.start() for t in threads]
# wait for all threads to finish
[t.join() for t in threads]
print(f"total time: {round(time.time() - start)} seconds")Sending 10,000 requests or generating 3 million tokens took around 101 seconds. This means we can run around ~99 inferences per second. But keep in mind that includes the network latency from europe to us-east-2. When we inspect the latency of the endpoint through cloudwatch we can see that the average request latency is around 13ms. This means we can serve around 153 inferences per second (having 2 HTTP workers).
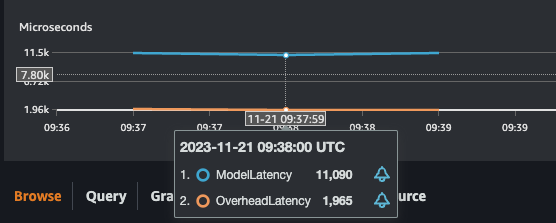
print(f"https://console.aws.amazon.com/cloudwatch/home?region={sess.boto_region_name}#metricsV2:graph=~(metrics~(~(~'AWS*2fSageMaker~'ModelLatency~'EndpointName~'{predictor.endpoint_name}~'VariantName~'AllTraffic))~view~'timeSeries~stacked~false~region~'{sess.boto_region_name}~start~'-PT5M~end~'P0D~stat~'Average~period~30);query=~'*7bAWS*2fSageMaker*2cEndpointName*2cVariantName*7d*20{predictor.endpoint_name}")The average latency for our Embeddings model is 11.1-11.5ms with a Framework overhead of 2ms leading to an request latency of ~13ms
Delete model and endpoint
To clean up, we can delete the model and endpoint.
predictor.delete_model()
predictor.delete_endpoint()Conclusion
In this post, we deployed a top open source Embeddings Model (BGE) on a single inf2.xlarge instance costing $0.99/hour on Amazon SageMaker using Optimum Neuron. We are able to run 2 replicas of the model on a single instance with a avg. model latency of 11.1-11.5ms for inputs of 300 tokens with a max sequence length of 384 and a throughput without network overhead of 180 inferences per second.
This means we can create (300 tokens * 153 requests) 45,900 tokens per second, 2,754,000 tokens per minute and 165,240,000 tokens per hour. This leads to a cost of ~$0.006 1M/tokens if utilized well. For comparison OpenAI or Amazon Bedrock charges $0.10 per 1M tokens.
For startups and companies looking into GPU alternative for generating emebddings Inferentia2 is a great option for not only efficient and fast but also cost-effective inference.
Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.