Accelerate GPT-J inference with DeepSpeed-Inference on GPUs
In this session, you will learn how to optimize GPT-2/GPT-J for Inerence using Hugging Face Transformers and DeepSpeed-Inference. The session will show you how to apply state-of-the-art optimization techniques using DeepSpeed-Inference. This session will focus on single GPU inference for GPT-2, GPT-NEO and GPT-J like models By the end of this session, you will know how to optimize your Hugging Face Transformers models (GPT-2, GPT-J) using DeepSpeed-Inference. We are going to optimize GPT-j 6B for text-generation.
You will learn how to:
- Setup Development Environment
- Load vanilla GPT-J model and set baseline
- Optimize GPT-J for GPU using DeepSpeeds
InferenceEngine - Evaluate the performance and speed
Let's get started! 🚀
This tutorial was created and run on a g4dn.2xlarge AWS EC2 Instance including an NVIDIA T4.
Quick Intro: What is DeepSpeed-Inference
DeepSpeed-Inference is an extension of the DeepSpeed framework focused on inference workloads. DeepSpeed Inference combines model parallelism technology such as tensor, pipeline-parallelism, with custom optimized cuda kernels. DeepSpeed provides a seamless inference mode for compatible transformer based models trained using DeepSpeed, Megatron, and HuggingFace. For a list of compatible models please see here. As mentioned DeepSpeed-Inference integrates model-parallelism techniques allowing you to run multi-GPU inference for LLM, like BLOOM with 176 billion parameters. If you want to learn more about DeepSpeed inference:
- Paper: DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
- Blog: Accelerating large-scale model inference and training via system optimizations and compression
1. Setup Development Environment
Our first step is to install Deepspeed, along with PyTorch, Transfromers and some other libraries. Running the following cell will install all the required packages.
Note: You need a machine with a GPU and a compatible CUDA installed. You can check this by running nvidia-smi in your terminal. If your setup is correct, you should get statistics about your GPU.
!pip install torch==1.11.0 torchvision==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113 --upgrade -q
# !pip install deepspeed==0.7.2 --upgrade -q
!pip install git+https://github.com/microsoft/DeepSpeed.git@ds-inference/support-large-token-length --upgrade
!pip install transformers[sentencepiece]==4.21.2 accelerate --upgrade -q
Before we start. Let's make sure all packages are installed correctly.
import re
import torch
# check deepspeed installation
report = !python3 -m deepspeed.env_report
r = re.compile('.*ninja.*OKAY.*')
assert any(r.match(line) for line in report) == True, "DeepSpeed Inference not correct installed"
# check cuda and torch version
torch_version, cuda_version = torch.__version__.split("+")
torch_version = ".".join(torch_version.split(".")[:2])
cuda_version = f"{cuda_version[2:4]}.{cuda_version[4:]}"
r = re.compile(f'.*torch.*{torch_version}.*')
assert any(r.match(line) for line in report) == True, "Wrong Torch version"
r = re.compile(f'.*cuda.*{cuda_version}.*')
assert any(r.match(line) for line in report) == True, "Wrong Cuda version"
2. Load vanilla GPT-J model and set baseline
After we set up our environment, we create a baseline for our model. We use the EleutherAI/gpt-j-6B, a GPT-J 6B was trained on the Pile, a large-scale curated dataset created by EleutherAI. This model was trained for 402 billion tokens over 383,500 steps on TPU v3-256 pod. It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly.
To create our baseline, we load the model with transformers and run inference.
Note: We created a separate repository containing sharded fp16 weights to make it easier to load the models on smaller CPUs by using the device_map feature to automatically place sharded checkpoints on GPU. Learn more here
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# Model Repository on huggingface.co
model_id = "philschmid/gpt-j-6B-fp16-sharded"
# Load Model and Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# we use device_map auto to automatically place all shards on the GPU to save CPU memory
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
print(f"model is loaded on device {model.device.type}")
# model is loaded on device cuda
Lets run some inference.
payload = "Hello my name is Philipp. I am getting in touch with you because i didn't get a response from you. What do I need to do to get my new card which I have requested 2 weeks ago? Please help me and answer this email in the next 7 days. Best regards and have a nice weekend but it"
input_ids = tokenizer(payload,return_tensors="pt").input_ids.to(model.device)
print(f"input payload: \n \n{payload}")
logits = model.generate(input_ids, do_sample=True, num_beams=1, min_length=128, max_new_tokens=128)
print(f"prediction: \n \n {tokenizer.decode(logits[0].tolist()[len(input_ids[0]):])}")
# input payload:
# Hello my name is Philipp. I am getting in touch with you because i didn't get a response from you. What do I need to do to get my new card which I have requested 2 weeks ago? Please help me and answer this email in the next 7 days. Best regards and have a nice weekend but it
# prediction:
# 's Friday evening for the British and you can feel that coming in on top of a Friday, please try to spend a quiet time tonight. Thankyou, PhilippCreate a latency baseline we use the measure_latency function, which implements a simple python loop to run inference and calculate the avg, mean & p95 latency for our model.
from time import perf_counter
import numpy as np
import transformers
# hide generation warnings
transformers.logging.set_verbosity_error()
def measure_latency(model, tokenizer, payload, generation_args={},device=model.device):
input_ids = tokenizer(payload, return_tensors="pt").input_ids.to(device)
latencies = []
# warm up
for _ in range(2):
_ = model.generate(input_ids, **generation_args)
# Timed run
for _ in range(10):
start_time = perf_counter()
_ = model.generate(input_ids, **generation_args)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
time_p95_ms = 1000 * np.percentile(latencies,95)
return f"P95 latency (ms) - {time_p95_ms}; Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f};", time_p95_msWe are going to use greedy search as decoding strategy and will generate 128 new tokens with 128 tokens as input.
payload="Hello my name is Philipp. I am getting in touch with you because i didn't get a response from you. What do I need to do to get my new card which I have requested 2 weeks ago? Please help me and answer this email in the next 7 days. Best regards and have a nice weekend but it"*2
print(f'Payload sequence length is: {len(tokenizer(payload)["input_ids"])}')
# generation arguments
generation_args = dict(
do_sample=False,
num_beams=1,
min_length=128,
max_new_tokens=128
)
vanilla_results = measure_latency(model,tokenizer,payload,generation_args)
print(f"Vanilla model: {vanilla_results[0]}")
# Payload sequence length is: 128
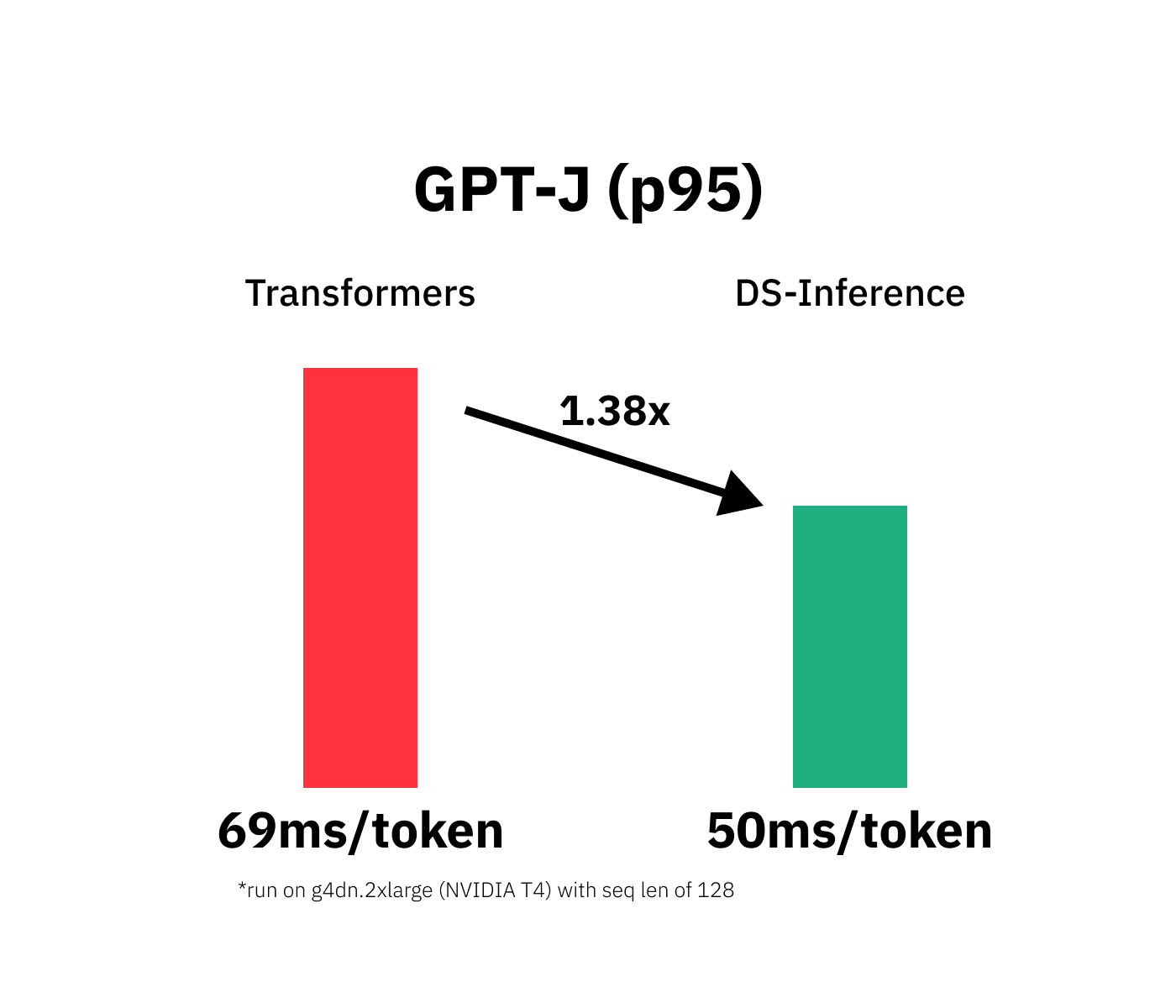
# Vanilla model: P95 latency (ms) - 8985.898722249989; Average latency (ms) - 8955.07 +\- 24.34;Our model achieves latency of 8.9s for 128 tokens or 69ms/token.
3. Optimize GPT-J for GPU using DeepSpeeds InferenceEngine
The next and most important step is to optimize our model for GPU inference. This will be done using the DeepSpeed InferenceEngine. The InferenceEngine is initialized using the init_inference method. The init_inference method expects as parameters atleast:
model: The model to optimize.mp_size: The number of GPUs to use.dtype: The data type to use.replace_with_kernel_inject: Whether inject custom kernels.
You can find more information about the init_inference method in the DeepSpeed documentation or thier inference blog.
Note: You might need to restart your kernel if you are running into a CUDA OOM error.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import deepspeed
# Model Repository on huggingface.co
model_id = "philschmid/gpt-j-6B-fp16-sharded"
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16)
# init deepspeed inference engine
ds_model = deepspeed.init_inference(
model=model, # Transformers models
mp_size=1, # Number of GPU
dtype=torch.float16, # dtype of the weights (fp16)
replace_method="auto", # Lets DS autmatically identify the layer to replace
replace_with_kernel_inject=True, # replace the model with the kernel injector
)
print(f"model is loaded on device {ds_model.module.device}")
We can now inspect our model graph to see that the vanilla GPTJLayer has been replaced with an HFGPTJLayer, which includes the DeepSpeedTransformerInference module, a custom nn.Module that is optimized for inference by the DeepSpeed Team.
InferenceEngine(
(module): GPTJForCausalLM(
(transformer): GPTJModel(
(wte): Embedding(50400, 4096)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0): DeepSpeedTransformerInference(
(attention): DeepSpeedSelfAttention()
(mlp): DeepSpeedMLP()
)from deepspeed.ops.transformer.inference import DeepSpeedTransformerInference
assert isinstance(ds_model.module.transformer.h[0], DeepSpeedTransformerInference) == True, "Model not sucessfully initalized"# Test model
example = "My name is Philipp and I"
input_ids = tokenizer(example,return_tensors="pt").input_ids.to(model.device)
logits = ds_model.generate(input_ids, do_sample=True, max_length=100)
tokenizer.decode(logits[0].tolist())
# 'My name is Philipp and I live in Freiburg in Germany and I have a project called Cenapen. After three months in development already it is finally finished – and it is a Linux based device / operating system on an ARM Cortex A9 processor on a Raspberry Pi.\n\nAt the moment it offers the possibility to store data locally, it can retrieve data from a local, networked or web based Sqlite database (I’m writing this tutorial while I’'4. Evaluate the performance and speed
As the last step, we want to take a detailed look at the performance of our optimized model. Applying optimization techniques, like graph optimizations or mixed-precision, not only impact performance (latency) those also might have an impact on the accuracy of the model. So accelerating your model comes with a trade-off.
Let's test the performance (latency) of our optimized model. We will use the same generation args as for our vanilla model.
payload = (
"Hello my name is Philipp. I am getting in touch with you because i didn't get a response from you. What do I need to do to get my new card which I have requested 2 weeks ago? Please help me and answer this email in the next 7 days. Best regards and have a nice weekend but it"
* 2
)
print(f'Payload sequence length is: {len(tokenizer(payload)["input_ids"])}')
# generation arguments
generation_args = dict(do_sample=False, num_beams=1, min_length=128, max_new_tokens=128)
ds_results = measure_latency(ds_model, tokenizer, payload, generation_args, ds_model.module.device)
print(f"DeepSpeed model: {ds_results[0]}")
# Payload sequence length is: 128
# DeepSpeed model: P95 latency (ms) - 6577.044982599967; Average latency (ms) - 6569.11 +\- 6.57;Our Optimized DeepsPeed model achieves latency of 6.5s for 128 tokens or 50ms/token.
We managed to accelerate the GPT-J-6B model latency from 8.9s to 6.5 for generating 128 tokens. This results into an improvement from 69ms/token to 50ms/token or 1.38x.
Conclusion
We successfully optimized our GPT-J Transformers with DeepSpeed-inference and managed to decrease our model latency from 69ms/token to 50ms/token or 1.3x.
Those are good results results thinking of that we only needed to add 1 additional line of code, but applying the optimization was as easy as adding one additional call to deepspeed.init_inference.
But I have to say that this isn't a plug-and-play process you can transfer to any Transformers model, task, or dataset. Also, make sure to check if your model is compatible with DeepSpeed-Inference.
Thanks for reading! If you have any questions, feel free to contact me, through Github, or on the forum. You can also connect with me on Twitter or LinkedIn.