Outperform OpenAI GPT-3 with SetFit for text-classification
In many Machine Learning applications, the amount of available labeled data is a barrier to producing a high-performing model. In the last 2 years developments have shown that you can overcome this data limitation by using Large Language Models, like OpenAI GPT-3 together wit a few examples as prompts at inference time to achieve good results. These developments are improving the missing labeled data situation but are introducing a new problem, which is the access and cost of Large Language Models.
But a group of research led by Intel Labs and the UKP Lab, Hugging Face released an new approach, called "SetFit" (https://arxiv.org/abs/2209.11055), that can be used to create high accuracte text-classification models with limited labeled data. SetFit is outperforming GPT-3 in 7 out of 11 tasks, while being 1600x smaller.
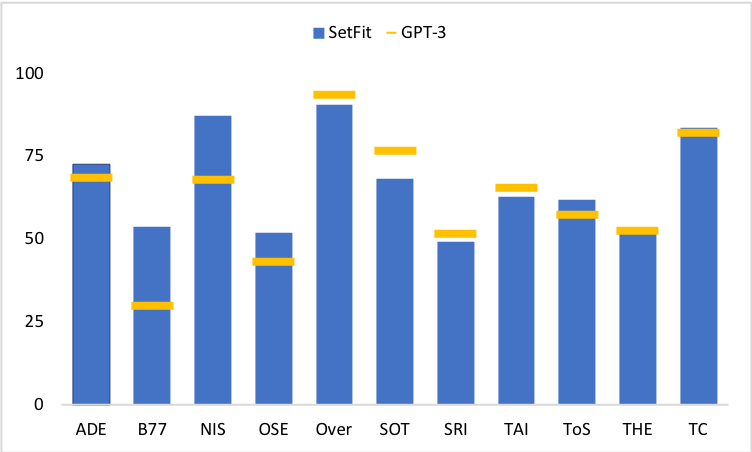
In this blog, you will learn how to use SetFit to create a text-classification model with only a 8 labeled samples per class, or 32 samples in total. You will also learn how to improve your model by using hyperparamter tuning.
You will learn how to:
- Setup Development Environment
- Create Dataset
- Fine-Tune Classifier with SetFit
- Use Hyperparameter search to optimize results
Why SetFit is better
Compared to other few-shot learning methods, SetFit has several unique features:
🗣 No prompts or verbalisers: Current techniques for few-shot fine-tuning require handcrafted prompts. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples. 🏎 Fast to train: SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. 🌎 Multilingual support: SetFit can be used with any Sentence Transformer on the Hub.
Now we know why SetFit is amazing, let's get started. 🚀
Note: This tutorial was created and run on a g4dn.xlarge AWS EC2 Instance including a NVIDIA T4.
1. Setup Development Environment
Our first step is to install the Hugging Face Libraries, including SetFit. Running the following cell will install all the required packages.
%pip install setfit[optuna]==0.3.0 datasets -U2. Create Dataset
We are going to use the ag_news dataset, which a news article classification dataset with 4 classes: World (0), Sports (1), Business (2), Sci/Tech (3).
The test split of the dataset contains 7600 examples, which is will be used to evaluate our model. The train split contains 120000 examples, which is a nice amount of data for fine-tuning a regular model.
But to shwocase SetFit, we wanto to create a dataset with only a 8 labeled samples per class, or 32 data points.
from datasets import load_dataset,concatenate_datasets
# Load the dataset
dataset = load_dataset("ag_news")
# create train dataset
seed=20
labels = 4
samples_per_label = 8
sampled_datasets = []
# find the number of samples per label
for i in range(labels):
sampled_datasets.append(dataset["train"].filter(lambda x: x["label"] == i).shuffle(seed=seed).select(range(samples_per_label)))
# concatenate the sampled datasets
train_dataset = concatenate_datasets(sampled_datasets)
# create test dataset
test_dataset = dataset["test"]
3. Fine-Tune Classifier with SetFit
When using SetFit we first fine-tune a Sentence Transformer model using our labeled data and contrastive training, where positive and negative pairs are created by in-class and out-class selection. The second step a classification head is trained on the encoded embeddings with their respective class labels.
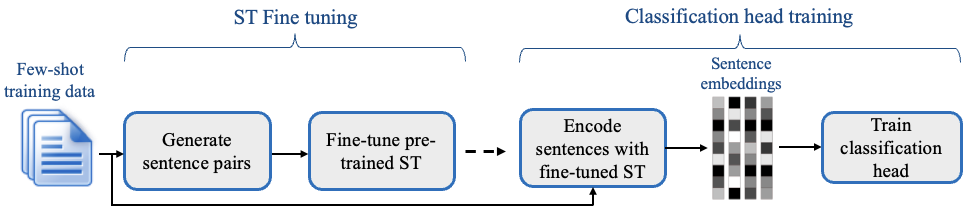
As Sentence Transformers we are going to use sentence-transformers/all-mpnet-base-v2. (you could replace the model with any available sentence transformer on hf.co).
The Python SetFit package is implementing useful classes and functions to make the fine-tuning process straightforward and easy. Similar to the Hugging Face Trainer class, SetFits implmenets the SetFitTrainer class is responsible for the training loop.
from setfit import SetFitModel, SetFitTrainer
from sentence_transformers.losses import CosineSimilarityLoss
# Load a SetFit model from Hub
model_id = "sentence-transformers/all-mpnet-base-v2"
model = SetFitModel.from_pretrained(model_id)
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=test_dataset,
loss_class=CosineSimilarityLoss,
metric="accuracy",
batch_size=64,
num_iterations=20, # The number of text pairs to generate for contrastive learning
num_epochs=1, # The number of epochs to use for constrastive learning
)
# Train and evaluate
trainer.train()
metrics = trainer.evaluate()
print(f"model used: {model_id}")
print(f"train dataset: {len(train_dataset)} samples")
print(f"accuracy: {metrics['accuracy']}")
# model used: sentence-transformers/all-mpnet-base-v2
# train dataset: 32 samples
# accuracy: 0.86473684210526314. Use Hyperparameter search to optimize result
The SetFitTrainer provides a hyperparameter_search() method that you can use to find the perefect hyperparameters for the data. SetFit is leveraging optuna under the hood to perform the hyperparameter search. To use the hyperparameter search, we need to define a model_init method, which creates our model for every "run" and a hp_space method that defines the hyperparameter search space.
from setfit import SetFitModel, SetFitTrainer
from sentence_transformers.losses import CosineSimilarityLoss
# model specfic hyperparameters
def model_init(params):
params = params or {}
max_iter = params.get("max_iter", 100)
solver = params.get("solver", "liblinear")
model_id = params.get("model_id", "sentence-transformers/all-mpnet-base-v2")
model_params = {
"head_params": {
"max_iter": max_iter,
"solver": solver,
}
}
return SetFitModel.from_pretrained(model_id, **model_params)
# training hyperparameters
def hp_space(trial):
return {
"learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
"num_epochs": trial.suggest_int("num_epochs", 1, 5),
"batch_size": trial.suggest_categorical("batch_size", [4, 8, 16, 32]),
"num_iterations": trial.suggest_categorical("num_iterations", [5, 10, 20, 40, 80]),
"seed": trial.suggest_int("seed", 1, 40),
"max_iter": trial.suggest_int("max_iter", 50, 300),
"solver": trial.suggest_categorical("solver", ["newton-cg", "lbfgs", "liblinear"]),
"model_id": trial.suggest_categorical(
"model_id",
[
"sentence-transformers/all-mpnet-base-v2",
"sentence-transformers/all-MiniLM-L12-v1",
],
),
}
trainer = SetFitTrainer(
train_dataset=train_dataset,
eval_dataset=test_dataset,
model_init=model_init,
)
best_run = trainer.hyperparameter_search(direction="maximize", hp_space=hp_space, n_trials=100)
After running 100 trials (runs) the bes model was found with the following hyperparameters:
{'learning_rate': 2.2041595048800003e-05, 'num_epochs': 2, 'batch_size': 64, 'num_iterations': 20, 'seed': 34, 'max_iter': 182, 'solver': 'lbfgs', 'model_id': 'sentence-transformers/all-mpnet-base-v2'}Achieving an accuracy of 0.873421052631579, which is 1.1% better than the model we trained without hyperparameter search.
best_run.hyperparametersAfter, we have found the perfect hyperparameters we need to run a last training using those.
trainer.apply_hyperparameters(best_run.hyperparameters, final_model=True)
trainer.train()
metrics = trainer.evaluate()
print(f"model used: {best_run.hyperparameters['model_id']}")
print(f"train dataset: {len(train_dataset)} samples")
print(f"accuracy: {metrics['accuracy']}")
# model used: sentence-transformers/all-mpnet-base-v2
# train dataset: 32 samples
# accuracy: 0.873421052631579Conclusion
Thats it, we have created a high-performing text-classification model with only 32 labeled samples or 8 samples per class using the SetFit approach. Our SetFit classifier achieved an accuracy of 0.873421052631579 on the test set. For comparison a regular model fine-tuned on the whole dataset (12 000) achieves a performance ~94% accuracy.
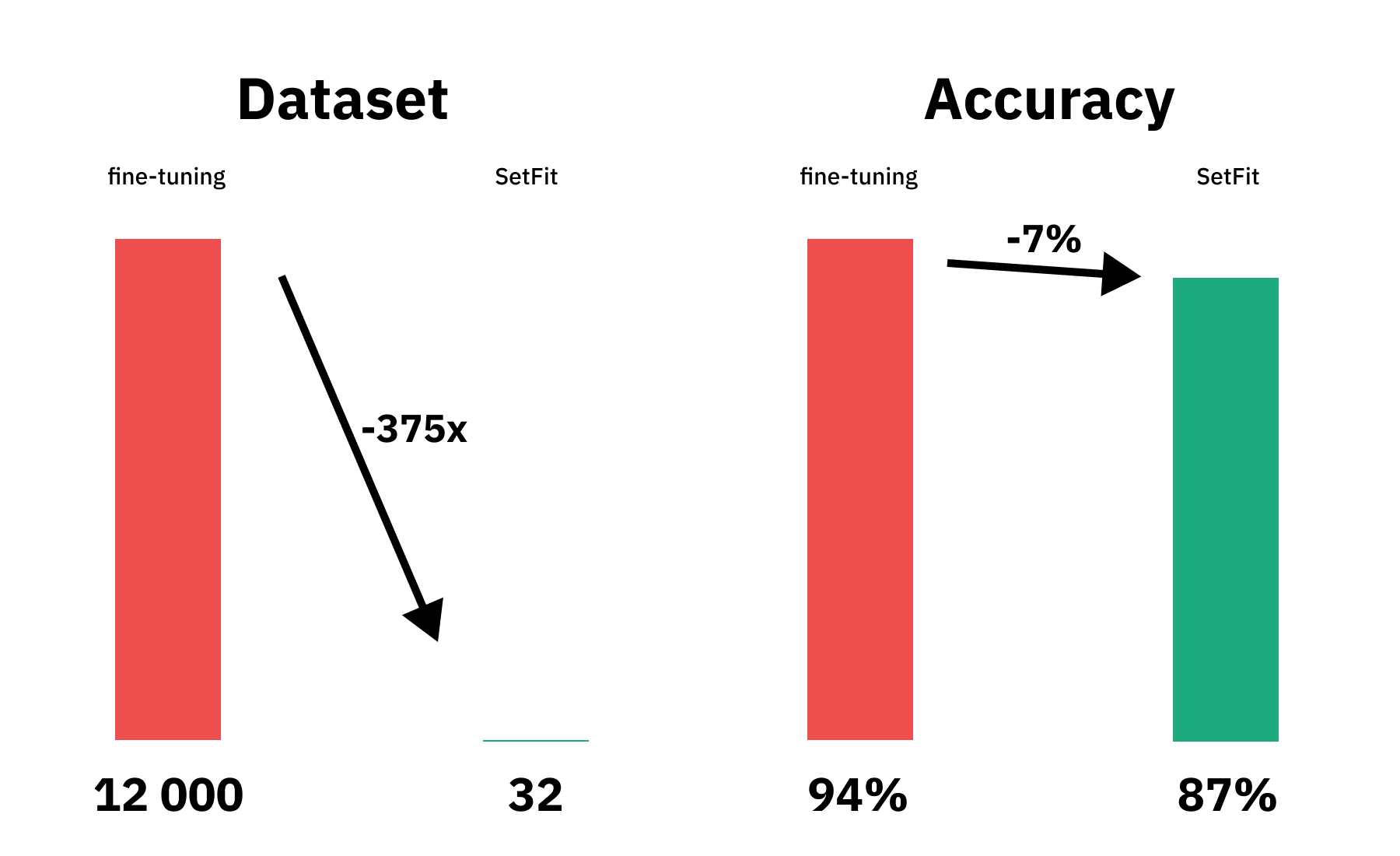
This means you with 375x less data you lose only ~7% accuracy. 🤯
This is huge! SetFit will help so many company to get started with text-classification and transformers, without the need to label a lot of data and compute power. Compared to LLM training s SetFit classifier takes less than 1 hour on a small GPU (NIVIDA T4) to train or less than $1 so to speak.
Thanks for reading! If you have any questions, feel free to contact me, through Github, or on the forum. You can also connect with me on Twitter or LinkedIn.