Fine-tune FLAN-T5 for chat & dialogue summarization
In this blog, you will learn how to fine-tune google/flan-t5-base for chat & dialogue summarization using Hugging Face Transformers. If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.
In this example we will use the samsum dataset a collection of about 16k messenger-like conversations with summaries. Conversations were created and written down by linguists fluent in English.
You will learn how to:
- Setup Development Environment
- Load and prepare samsum dataset
- Fine-tune and evaluate FLAN-T5
- Run Inference and summarize ChatGPT dialogues
Before we can start, make sure you have a Hugging Face Account to save artifacts and experiments.
Quick intro: FLAN-T5, just a better T5
FLAN-T5 released with the Scaling Instruction-Finetuned Language Models paper is an enhanced version of T5 that has been finetuned in a mixture of tasks. The paper explores instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. The paper discovers that overall instruction finetuning is a general method for improving the performance and usability of pretrained language models.
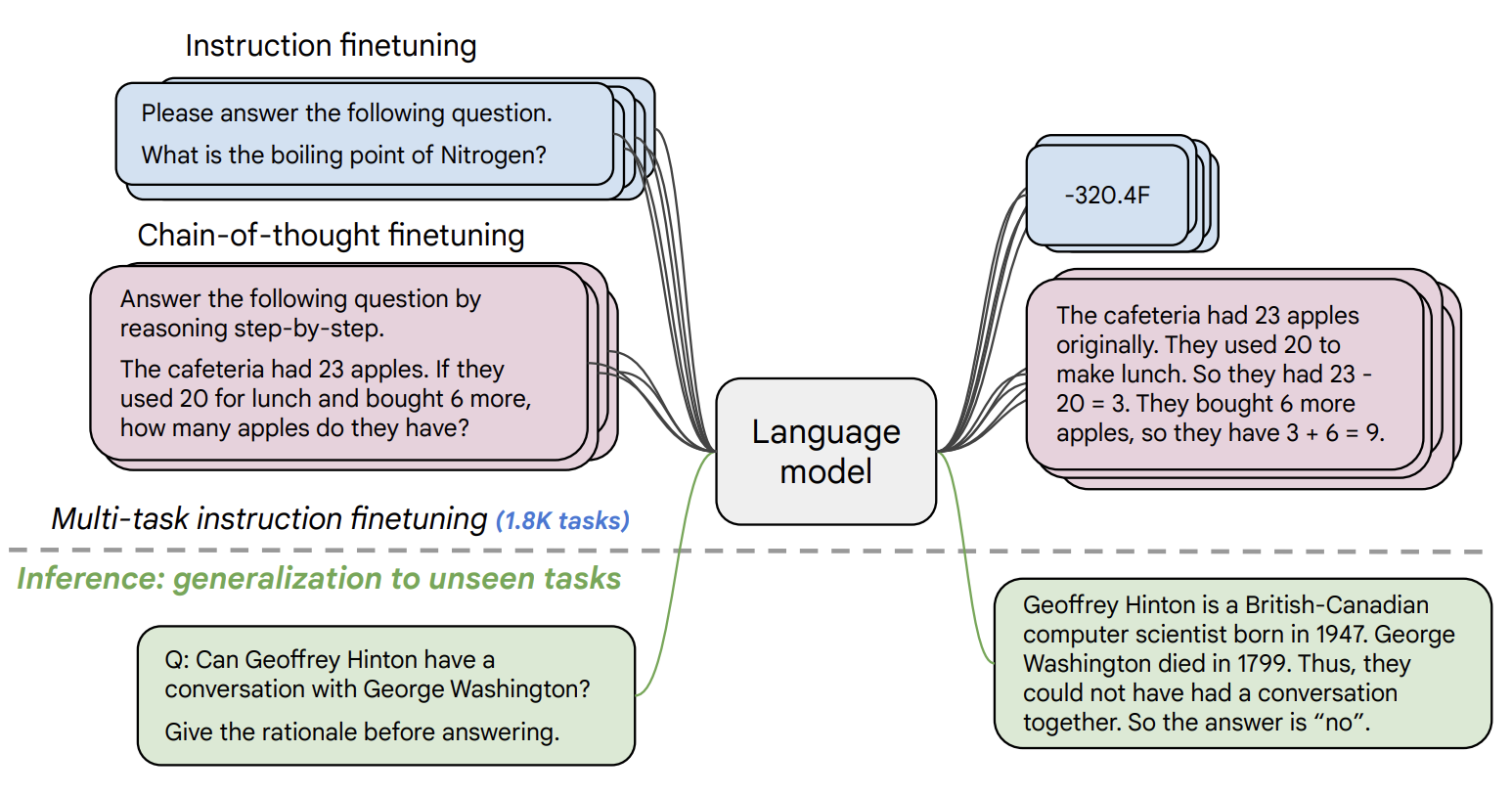
- Paper: https://arxiv.org/abs/2210.11416
- Official repo: https://github.com/google-research/t5x
Now we know what FLAN-T5 is, let's get started. 🚀
Note: This tutorial was created and run on a p3.2xlarge AWS EC2 Instance including a NVIDIA V100.
1. Setup Development Environment
Our first step is to install the Hugging Face Libraries, including transformers and datasets. Running the following cell will install all the required packages.
!pip install pytesseract transformers datasets rouge-score nltk tensorboard py7zr --upgrade
# install git-fls for pushing model and logs to the hugging face hub
!sudo apt-get install git-lfs --yesThis example will use the Hugging Face Hub as a remote model versioning service. To be able to push our model to the Hub, you need to register on the Hugging Face.
If you already have an account, you can skip this step.
After you have an account, we will use the notebook_login util from the huggingface_hub package to log into our account and store our token (access key) on the disk.
from huggingface_hub import notebook_login
notebook_login()2. Load and prepare samsum dataset
we will use the samsum dataset a collection of about 16k messenger-like conversations with summaries. Conversations were created and written down by linguists fluent in English.
{
"id": "13818513",
"summary": "Amanda baked cookies and will bring Jerry some tomorrow.",
"dialogue": "Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I'll bring you tomorrow :-)"
}dataset_id = "samsum"To load the samsum dataset, we use the load_dataset() method from the 🤗 Datasets library.
from datasets import load_dataset
# Load dataset from the hub
dataset = load_dataset(dataset_id)
print(f"Train dataset size: {len(dataset['train'])}")
print(f"Test dataset size: {len(dataset['test'])}")
# Train dataset size: 14732
# Test dataset size: 819Lets checkout an example of the dataset.
from random import randrange
sample = dataset['train'][randrange(len(dataset["train"]))]
print(f"dialogue: \n{sample['dialogue']}\n---------------")
print(f"summary: \n{sample['summary']}\n---------------")To train our model we need to convert our inputs (text) to token IDs. This is done by a 🤗 Transformers Tokenizer. If you are not sure what this means check out chapter 6 of the Hugging Face Course.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_id="google/flan-t5-base"
# Load tokenizer of FLAN-t5-base
tokenizer = AutoTokenizer.from_pretrained(model_id)
before we can start training we need to preprocess our data. Abstractive Summarization is a text2text-generation task. This means our model will take a text as input and generate a summary as output. For this we want to understand how long our input and output will be to be able to efficiently batch our data.
from datasets import concatenate_datasets
# The maximum total input sequence length after tokenization.
# Sequences longer than this will be truncated, sequences shorter will be padded.
tokenized_inputs = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["dialogue"], truncation=True), batched=True, remove_columns=["dialogue", "summary"])
max_source_length = max([len(x) for x in tokenized_inputs["input_ids"]])
print(f"Max source length: {max_source_length}")
# The maximum total sequence length for target text after tokenization.
# Sequences longer than this will be truncated, sequences shorter will be padded."
tokenized_targets = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["summary"], truncation=True), batched=True, remove_columns=["dialogue", "summary"])
max_target_length = max([len(x) for x in tokenized_targets["input_ids"]])
print(f"Max target length: {max_target_length}")def preprocess_function(sample,padding="max_length"):
# add prefix to the input for t5
inputs = ["summarize: " + item for item in sample["dialogue"]]
# tokenize inputs
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)
# Tokenize targets with the `text_target` keyword argument
labels = tokenizer(text_target=sample["summary"], max_length=max_target_length, padding=padding, truncation=True)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length":
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True, remove_columns=["dialogue", "summary", "id"])
print(f"Keys of tokenized dataset: {list(tokenized_dataset['train'].features)}")3. Fine-tune and evaluate FLAN-T5
After we have processed our dataset, we can start training our model. Therefore we first need to load our FLAN-T5 from the Hugging Face Hub. In the example we are using a instance with a NVIDIA V100 meaning that we will fine-tune the base version of the model.
I plan to do a follow-up post on how to fine-tune the xxl version of the model using Deepspeed.
from transformers import AutoModelForSeq2SeqLM
# huggingface hub model id
model_id="google/flan-t5-base"
# load model from the hub
model = AutoModelForSeq2SeqLM.from_pretrained(model_id)We want to evaluate our model during training. The Trainer supports evaluation during training by providing a compute_metrics.
The most commonly used metrics to evaluate summarization task is rogue_score short for Recall-Oriented Understudy for Gisting Evaluation). This metric does not behave like the standard accuracy: it will compare a generated summary against a set of reference summaries
We are going to use evaluate library to evaluate the rogue score.
import evaluate
import nltk
import numpy as np
from nltk.tokenize import sent_tokenize
nltk.download("punkt")
# Metric
metric = evaluate.load("rouge")
# helper function to postprocess text
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# rougeLSum expects newline after each sentence
preds = ["\n".join(sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(sent_tokenize(label)) for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
result = {k: round(v * 100, 4) for k, v in result.items()}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
return resultBefore we can start training is to create a DataCollator that will take care of padding our inputs and labels. We will use the DataCollatorForSeq2Seq from the 🤗 Transformers library.
from transformers import DataCollatorForSeq2Seq
# we want to ignore tokenizer pad token in the loss
label_pad_token_id = -100
# Data collator
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8
)
The last step is to define the hyperparameters (TrainingArguments) we want to use for our training. We are leveraging the Hugging Face Hub integration of the Trainer to automatically push our checkpoints, logs and metrics during training into a repository.
from huggingface_hub import HfFolder
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
# Hugging Face repository id
repository_id = f"{model_id.split('/')[1]}-{dataset_id}"
# Define training args
training_args = Seq2SeqTrainingArguments(
output_dir=repository_id,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
predict_with_generate=True,
fp16=False, # Overflows with fp16
learning_rate=5e-5,
num_train_epochs=5,
# logging & evaluation strategies
logging_dir=f"{repository_id}/logs",
logging_strategy="steps",
logging_steps=500,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
# metric_for_best_model="overall_f1",
# push to hub parameters
report_to="tensorboard",
push_to_hub=False,
hub_strategy="every_save",
hub_model_id=repository_id,
hub_token=HfFolder.get_token(),
)
# Create Trainer instance
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
compute_metrics=compute_metrics,
)We can start our training by using the train method of the Trainer.
# Start training
trainer.train()
Nice, we have trained our model. 🎉 Lets run evaluate the best model again on the test set.
trainer.evaluate()The best score we achieved is an rouge1 score of 47.23.
Lets save our results and tokenizer to the Hugging Face Hub and create a model card.
# Save our tokenizer and create model card
tokenizer.save_pretrained(repository_id)
trainer.create_model_card()
# Push the results to the hub
trainer.push_to_hub()4. Run Inference and summarize ChatGPT dialogues
Now we have a trained model, we can use it to run inference. We will use the pipeline API from transformers and a test example from our dataset.
from transformers import pipeline
from random import randrange
# load model and tokenizer from huggingface hub with pipeline
summarizer = pipeline("summarization", model="philschmid/flan-t5-base-samsum", device=0)
# select a random test sample
sample = dataset['test'][randrange(len(dataset["test"]))]
print(f"dialogue: \n{sample['dialogue']}\n---------------")
# summarize dialogue
res = summarizer(sample["dialogue"])
print(f"flan-t5-base summary:\n{res[0]['summary_text']}")output
dialogue:
Abby: Have you talked to Miro?
Dylan: No, not really, I've never had an opportunity
Brandon: me neither, but he seems a nice guy
Brenda: you met him yesterday at the party?
Abby: yes, he's so interesting
Abby: told me the story of his father coming from Albania to the US in the early 1990s
Dylan: really, I had no idea he is Albanian
Abby: he is, he speaks only Albanian with his parents
Dylan: fascinating, where does he come from in Albania?
Abby: from the seacoast
Abby: Duress I believe, he told me they are not from Tirana
Dylan: what else did he tell you?
Abby: That they left kind of illegally
Abby: it was a big mess and extreme poverty everywhere
Abby: then suddenly the border was open and they just left
Abby: people were boarding available ships, whatever, just to get out of there
Abby: he showed me some pictures, like <file_photo>
Dylan: insane
Abby: yes, and his father was among the people
Dylan: scary but interesting
Abby: very!
---------------
flan-t5-base summary:
Abby met Miro yesterday at the party. Miro's father came from Albania to the US in the early 1990s. He speaks Albanian with his parents. The border was open and people were boarding ships to get out of there.Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.