Financial Text Summarization with Hugging Face Transformers, Keras & Amazon SageMaker
Welcome to this end-to-end Financial Summarization (NLP) example using Keras and Hugging Face Transformers. In this demo, we will use the Hugging Faces transformers and datasets library together with Tensorflow & Keras to fine-tune a pre-trained seq2seq transformer for financial summarization.
We are going to use the Trade the Event dataset for abstractive text summarization. The benchmark dataset contains 303893 news articles range from 2020/03/01 to 2021/05/06. The articles are downloaded from the PRNewswire and Businesswire.
More information for the dataset can be found at the repository.
We are going to use all of the great Feature from the Hugging Face ecosystem like model versioning and experiment tracking as well as all the great features of Keras like Early Stopping and Tensorboard.
You can find the notebook and scripts in this repository: philschmid/keras-financial-summarization-huggingfacePublic.
Installation
!pip install git+https://github.com/huggingface/transformers.git@master --upgrade#!pip install "tensorflow==2.6.0"
!pip install transformers "datasets>=1.17.0" tensorboard rouge_score nltk --upgrade
# install gdown for downloading the dataset
!pip install gdowninstall git-lfs to push models to hf.co/models
!sudo apt-get install git-lfsThis example will use the Hugging Face Hub as a remote model versioning service. To be able to push our model to the Hub, you need to register on the Hugging Face.
If you already have an account you can skip this step.
After you have an account, we will use the notebook_login util from the huggingface_hub package to log into our account and store our token (access key) on the disk.
from huggingface_hub import notebook_login
notebook_login()
Setup & Configuration
In this step, we will define global configurations and parameters, which are used across the whole end-to-end fine-tuning process, e.g. tokenizer and model we will use.
In this example are we going to fine-tune the sshleifer/distilbart-cnn-12-6 a distilled version of the BART transformer. Since the original repository didn't include Keras weights I converted the model to Keras using from_pt=True, when loading the model.
model_id = "philschmid/tf-distilbart-cnn-12-6"You can easily adjust the model_id to another Vision Transformer model, e.g. google/pegasus-xsum
Dataset & Pre-processing
We are going to use the Trade the Event dataset for abstractive text summarization. The benchmark dataset contains 303893 news articles range from 2020/03/01 to 2021/05/06. The articles are downloaded from the PRNewswire and Businesswire.
The we will use the column text as INPUT and title as summarization TARGET.
sample
{
"text": "PLANO, Texas, Dec. 8, 2020 /PRNewswire/ --European Wax Center(EWC), the leading personal care franchise brand that offers expert wax services from certified specialists is proud to welcome a new Chief Financial Officer, Jennifer Vanderveldt. In the midst of European Wax Center\"s accelerated growth plan, Jennifer will lead the Accounting and FP&A teams to continue to widen growth and organizational initiatives. (PRNewsfoto/European Wax Center) ...",
"title": "European Wax Center Welcomes Jennifer Vanderveldt As Chief Financial Officer",
"pub_time": "2020-12-08 09:00:00-05:00",
"labels": {
"ticker": "MIK",
"start_time": "2020-12-08 09:00:00-05:00",
"start_price_open": 12.07,
"start_price_close": 12.07,
"end_price_1day": 12.8,
"end_price_2day": 12.4899,
"end_price_3day": 13.0,
"end_time_1day": "2020-12-08 19:11:00-05:00",
"end_time_2day": "2020-12-09 18:45:00-05:00",
"end_time_3day": "2020-12-10 19:35:00-05:00",
"highest_price_1day": 13.2,
"highest_price_2day": 13.2,
"highest_price_3day": 13.2,
"highest_time_1day": "2020-12-08 10:12:00-05:00",
"highest_time_2day": "2020-12-08 10:12:00-05:00",
"highest_time_3day": "2020-12-08 10:12:00-05:00",
"lowest_price_1day": 11.98,
"lowest_price_2day": 11.98,
"lowest_price_3day": 11.98,
"lowest_time_1day": "2020-12-08 09:13:00-05:00",
"lowest_time_2day": "2020-12-08 09:13:00-05:00",
"lowest_time_3day": "2020-12-08 09:13:00-05:00"
}
}The TradeTheEvent is not yet available as a dataset in the datasets library. To be able to create a Dataset instance we need to write a small little helper function, which converts the downloaded .json to a jsonl file to then be then loaded with load_dataset.
As a first step, we need to download the dataset to our filesystem using gdown.
!gdown "https://drive.google.com/u/0/uc?export=download&confirm=2rTA&id=130flJ0u_5Ox5D-pQFa5lGiBLqILDBmXX"We should now have a file called evluate_news.jsonl in our filesystem and can write a small helper function to convert the .json to a jsonl file.
src_path="evaluate_news.json"
target_path='tde_dataset.jsonl'
import json
with open(src_path,"r+") as f, open(target_path, 'w') as outfile:
JSON_file = json.load(f)
for entry in JSON_file:
json.dump(entry, outfile)
outfile.write('\n')
We can now remove the evaluate_news.json to save some space and avoid confusion.
!rm -rf evaluate_news.jsonTo load our dataset we can use the load_dataset function from the datasets library.
from datasets import load_dataset
target_path='tde_dataset.jsonl'
ds = load_dataset('json', data_files=target_path)Pre-processing & Tokenization
To train our model we need to convert our "Natural Language" to token IDs. This is done by a 🤗 Transformers Tokenizer which will tokenize the inputs (including converting the tokens to their corresponding IDs in the pretrained vocabulary). If you are not sure what this means check out chapter 6 of the Hugging Face Course.
before we tokenize our dataset we remove all of the unused columns for the summarization task to save some time and storage.
to_remove_columns = ["pub_time","labels"]
ds = ds["train"].remove_columns(to_remove_columns)from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)Compared to a text-classification in summarization our labels are also text. This means we need to apply truncation to both the text and title title to ensure we don’t pass excessively long inputs to our model. The tokenizers in 🤗 Transformers provide a nifty as_target_tokenizer() function that allows you to tokenize the labels in parallel to the inputs.
In addition to this we define values for max_input_length (maximum lenght before the text is trubcated) and max_target_length (maximum lenght for the summary/prediction).
max_input_length = 512
max_target_length = 64
def preprocess_function(examples):
model_inputs = tokenizer(
examples["text"], max_length=max_input_length, truncation=True
)
# Set up the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(
examples["title"], max_length=max_target_length, truncation=True
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_datasets = ds.map(preprocess_function, batched=True)Since our dataset doesn't includes any split we need to train_test_split ourself to have an evaluation/test dataset for evaluating the result during and after training.
# test size will be 15% of train dataset
test_size=.15
processed_dataset = tokenized_datasets.shuffle().train_test_split(test_size=test_size)Fine-tuning the model using Keras
Now that our dataset is processed, we can download the pretrained model and fine-tune it. But before we can do this we need to convert our Hugging Face datasets Dataset into a tf.data.Dataset. For this, we will use the .to_tf_dataset method and a data collator (Data collators are objects that will form a batch by using a list of dataset elements as input).
Hyperparameter
from huggingface_hub import HfFolder
import tensorflow as tf
num_train_epochs = 5
train_batch_size = 8
eval_batch_size = 8
learning_rate = 5.6e-5
weight_decay_rate=0.01
num_warmup_steps=0
output_dir=model_id.split("/")[1]
hub_token = HfFolder.get_token() # or your token directly "hf_xxx"
hub_model_id = f'{model_id.split("/")[1]}-tradetheevent'
fp16=True
# Train in mixed-precision float16
# Comment this line out if you're using a GPU that will not benefit from this
if fp16:
tf.keras.mixed_precision.set_global_policy("mixed_float16")
Converting the dataset to a tf.data.Dataset
to create our tf.data.Dataset we need to download the model to be able to initialize our data collator.
from transformers import TFAutoModelForSeq2SeqLM
# load pre-trained model
model = TFAutoModelForSeq2SeqLM.from_pretrained(model_id)to convert our dataset we use the .to_tf_dataset method.
from transformers import DataCollatorForSeq2Seq
# Data collator that will dynamically pad the inputs received, as well as the labels.
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model, return_tensors="tf")
# converting our train dataset to tf.data.Dataset
tf_train_dataset = processed_dataset["train"].to_tf_dataset(
columns=["input_ids", "attention_mask", "labels"],
shuffle=True,
batch_size=train_batch_size,
collate_fn=data_collator)
# converting our test dataset to tf.data.Dataset
tf_eval_dataset = processed_dataset["test"].to_tf_dataset(
columns=["input_ids", "attention_mask", "labels"],
shuffle=True,
batch_size=eval_batch_size,
collate_fn=data_collator)Create optimizer and compile the model
from transformers import create_optimizer
import tensorflow as tf
# create optimizer wight weigh decay
num_train_steps = len(tf_train_dataset) * num_train_epochs
optimizer, lr_schedule = create_optimizer(
init_lr=learning_rate,
num_train_steps=num_train_steps,
weight_decay_rate=weight_decay_rate,
num_warmup_steps=num_warmup_steps,
)
# compile model
model.compile(optimizer=optimizer)Callbacks
As mentioned in the beginning we want to use the Hugging Face Hub for model versioning and monitoring. Therefore we want to push our model weights, during training and after training to the Hub to version it.
Additionally, we want to track the performance during training therefore we will push the Tensorboard logs along with the weights to the Hub to use the "Training Metrics" Feature to monitor our training in real-time.
import os
from transformers.keras_callbacks import PushToHubCallback
from tensorflow.keras.callbacks import TensorBoard as TensorboardCallback
callbacks=[]
callbacks.append(TensorboardCallback(log_dir=os.path.join(output_dir,"logs")))
if hub_token:
callbacks.append(PushToHubCallback(output_dir=output_dir,
tokenizer=tokenizer,
hub_model_id=hub_model_id,
hub_token=hub_token))
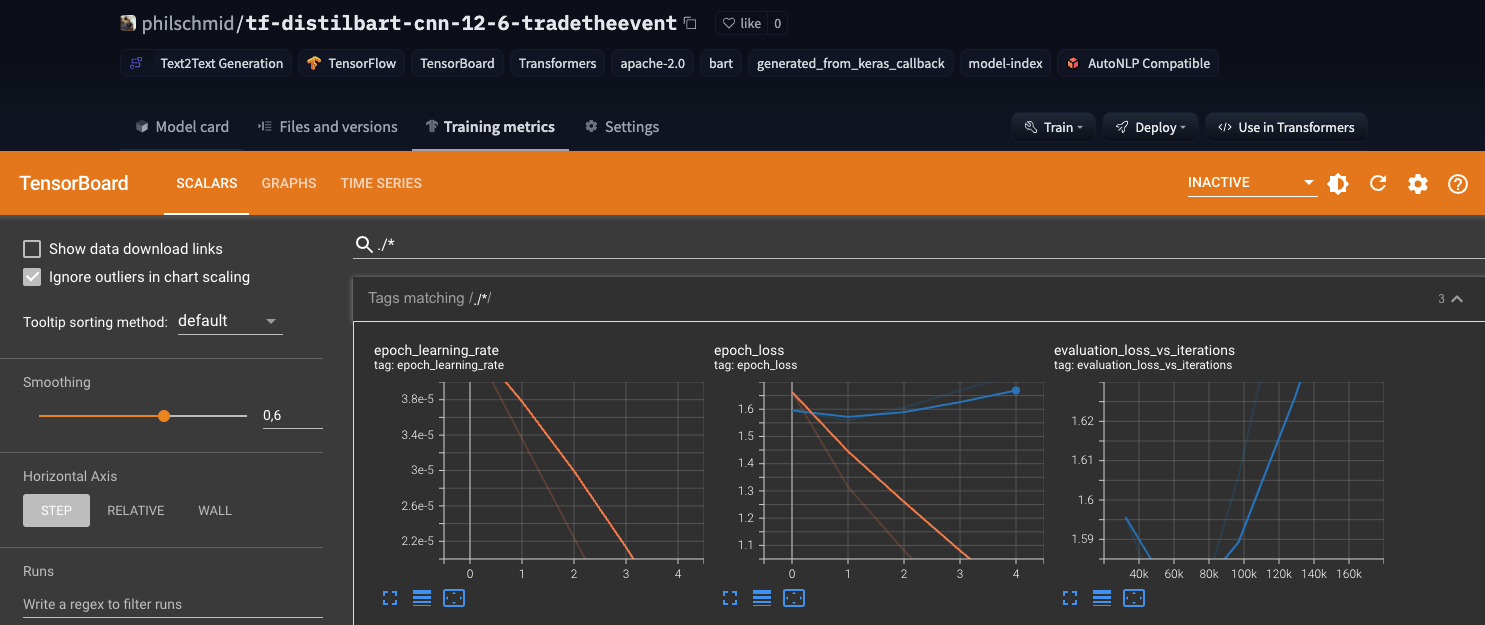
You can find the the Tensorboard on the Hugging Face Hub at your model repository at Training Metrics. We can clearly see that the experiment I ran is not perfect since the validation loss increases again after time. But this is a good example of how to use the Tensorboard callback and the Hugging Face Hub. As a next step i would probably switch to Amazon SageMaker and run multiple experiments with the Tensorboard integration and EarlyStopping to find the best hyperparameters.
Training
Start training with calling model.fit
train_results = model.fit(
tf_train_dataset,
validation_data=tf_eval_dataset,
callbacks=callbacks,
epochs=num_train_epochs,
)Evaluation
The most commonly used metrics to evaluate summarization task is rogue_score short for Recall-Oriented Understudy for Gisting Evaluation). This metric does not behave like the standard accuracy: it will compare a generated summary against a set of reference summaries
from datasets import load_metric
from tqdm import tqdm
import numpy as np
import nltk
nltk.download("punkt")
from nltk.tokenize import sent_tokenize
metric = load_metric("rouge")
def evaluate(model, dataset):
all_predictions = []
all_labels = []
for batch in tqdm(dataset):
predictions = model.generate(batch["input_ids"])
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = batch["labels"].numpy()
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]
all_predictions.extend(decoded_preds)
all_labels.extend(decoded_labels)
result = metric.compute(
predictions=decoded_preds, references=decoded_labels, use_stemmer=True
)
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
return {k: round(v, 4) for k, v in result.items()}
results = evaluate(model, tf_eval_dataset)Run Managed Training using Amazon Sagemaker
If you want to run this examples on Amazon SageMaker to benefit from the Training Platform follow the cells below. I converted the Notebook into a python script train.py, which accepts same hyperparameter and can we run on SageMaker using the HuggingFace estimator.
install SageMaker and gdown.
#!pip install sagemaker gdownDownload the dataset and convert it to jsonlines.
!gdown "https://drive.google.com/u/0/uc?export=download&confirm=2rTA&id=130flJ0u_5Ox5D-pQFa5lGiBLqILDBmXX"
src_path="evaluate_news.json"
target_path='tde_dataset.jsonl'
import json
with open(src_path,"r+") as f, open(target_path, 'w') as outfile:
JSON_file = json.load(f)
for entry in JSON_file:
json.dump(entry, outfile)
outfile.write('\n')
As next step we create a SageMaker session to start our training. The snippet below works in Amazon SageMaker Notebook Instances or Studio. If you are running in a local environment check-out the documentation for how to initialize your session.
import sagemaker
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")Now, we can define our HuggingFace estimator and Hyperparameter.
from sagemaker.huggingface import HuggingFace
# gets role for executing training job
role = sagemaker.get_execution_role()
hyperparameters = {
'model_id': 'philschmid/tf-distilbart-cnn-12-6',
'dataset_file_name': 'tde_dataset.jsonl',
'num_train_epochs': 5,
'train_batch_size': 8,
'eval_batch_size': 8,
'learning_rate': 5e-5,
'weight_decay_rate': 0.01,
'num_warmup_steps': 0,
'hub_token': HfFolder.get_token(),
'hub_model_id': 'sagemaker-tf-distilbart-cnn-12-6',
'fp16': True
}
# creates Hugging Face estimator
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.12.3',
tensorflow_version='2.5.1',
py_version='py36',
hyperparameters = hyperparameters
)
Opload our raw dataset to s3
from sagemaker.s3 import S3Uploader
dataset_uri = S3Uploader.upload(local_path="tde_dataset.jsonl",desired_s3_uri=f"s3://{sess.default_bucket()}/TradeTheEvent/tde_dataset.jsonl")
After the dataset is uploaded we can start the training a pass our s3_uri as argument.
# starting the train job
huggingface_estimator.fit({"dataset": dataset_uri})Conclusion
We managed to successfully fine-tune a Seq2Seq BART Transformer using Transformers and Keras, without any heavy lifting or complex and unnecessary boilerplate code. The new utilities like .to_tf_dataset are improving the developer experience of the Hugging Face ecosystem to become more Keras and TensorFlow friendly. Combining those new features with the Hugging Face Hub we get a fully-managed MLOps pipeline for model-versioning and experiment management using Keras callback API. Through SageMaker we could easily scale our Training. This was especially helpful since the training takes 10-12h depending on how many epochs we ran.
You can find the code here and feel free to open a thread on the forum.
Thanks for reading. If you have any questions, feel free to contact me, through Github, or on the forum. You can also connect with me on Twitter or LinkedIn.