Evaluating Open LLMs with MixEval: The Closest Benchmark to LMSYS Chatbot Arena
Last updated: 2024-09-23.
Traditional ground-truth-based benchmarks, while efficient and reproducible, often fail to capture the complexity and nuance of real-world applications to evaluate LLMs. LLM-as-judge benchmarks attempt to address this by using models to evaluate responses, but they can suffer from grading biases and limited query quantity. User-facing evaluations like LMSYS Chatbot Arena are currently one of the most trusted sources for assessing the quality of LLMs. While they provide reliable signals, they have significant drawbacks—they are costly, time-consuming, and not easily reproducible.
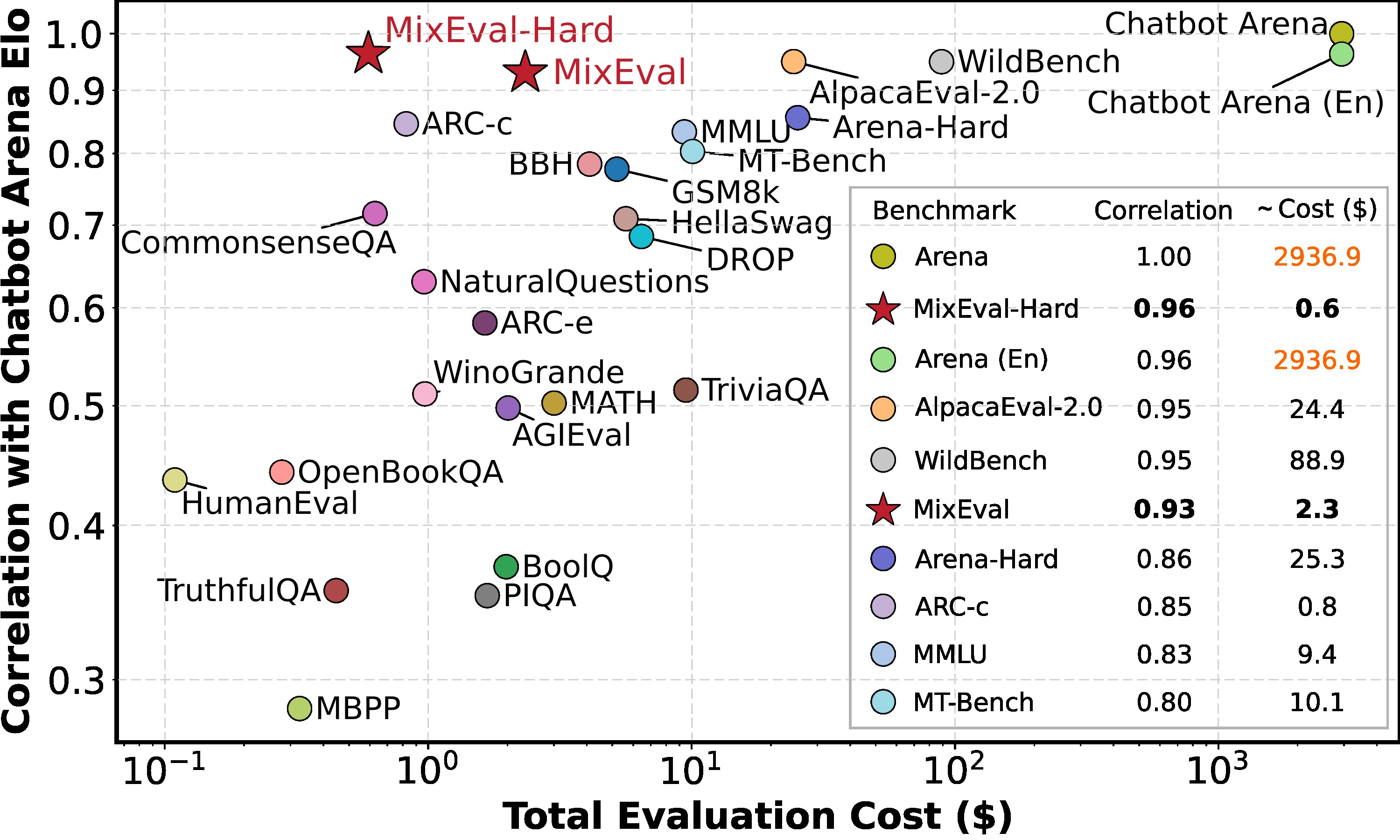
MixEval tries to bridge the gap between real-world user queries and efficient ground-truth-based benchmarks. It currently has a 0.96 model ranking correlation with Chatbot Arena and costs less than $1 dollar to run.
What is MixEval?
MixEval and MixEval-Hard combine existing benchmarks with real-world user queries from the web to close the gap between academic and real-world use. They match queries mined from the web with similar queries from existing benchmarks.
- High Correlation: Achieves a 0.96 model ranking correlation with Chatbot Arena, ensuring accurate model evaluation.
- Cost-Effective: Costs only around $0.6 to run using GPT-3.5 as a judge, which is about 6% of the time and cost of running MMLU.
- Dynamic Evaluation: Utilizes a rapid and stable data update pipeline to mitigate contamination risk.
- Comprehensive Query Distribution: Based on a large-scale web corpus, providing a less biased evaluation.
- Fair Grading: Ground-truth-based nature ensures an unbiased evaluation process.
MixEval comes in two versions:
- MixEval: The standard benchmark that balances comprehensiveness and efficiency.
- MixEval-Hard: A more challenging version designed to offer more room for model improvement and enhance the benchmark's ability to distinguish strong models.
Evaluate open LLM on MixEval
MixEval offers comes with a public GitHub repository to evaluate LLMs. However, this comes with some limitations. I created this fork to make the integration and use of MixEval easier during the training of new models. This Fork includes several improved features to make usage easier and more flexible. Including:
- Local Model Evaluation: Support for evaluating local models during or post-training with
transformers. - Hugging Face Datasets Integration: Eliminates the need for local files by integrating with Hugging Face Datasets.
- Accelerated Evaluation: Utilizes Hugging Face TGI or vLLM to speed up evaluation
- Enhanced Output: Improved markdown outputs and timing for training.
- Simplified Installation: Fixed pip install for remote or CI integration.
To install this enhanced version of MixEval, use the following command:
pip install git+https://github.com/philschmid/MixEval --upgradeFor more detailed instructions on evaluating models not included by default, refer to the MixEval documentation.
Note: Make sure you have a valid OpenAI Key, since GPT-3.5 will be used as “parser”.
Evaluate Local LLMs during or post training
A single command can evaluate local LLMs on MixEval (mixeval_hard).
MODEL_PARSER_API=$(echo $OPENAI_API_KEY) python -m mix_eval.evaluate \
--data_path hf://zeitgeist-ai/mixeval \
--model_path my/local/path \
--output_dir results/agi-5 \
--model_name local_chat \
--benchmark mixeval_hard \
--version 2024-08-11 \
--batch_size 20 \
--api_parallel_num 20Let's try to better understand this:
data_path: Location of the mixeval set we want to use, here hosted on hugging face.model_path: Path to our trained model, this can also be a Hugging Face ID, e.g.organization/modeloutput_dir: Where the results will be storedmodel_name: Here, you would normally specify themixevalmodel as defined in the GitHub, but in the fork, we implemented an agnosticlocal_chatversion. (if you want to customize the .generate args, you need to register a new model.)benchmark: Eithermixevalormixeval_hardversion: Version of MixEval, the team plans to update the prompts and tasks regularlybatch_size: The batch size of the generator modelapi_parallel_num: Number of parallel requests sent to OpenAI.
You can find all possible args in the code.
After running the evaluation, MixEval provides a comprehensive breakdown of the model's performance across various metrics.
| Metric | Score |
| --------------------------- | ------- |
| MBPP | 100.00% |
....
| overall score (final score) | 35.15% |Accelerated evaluation LLMs using vLLM
When training new models or experimenting, you want to iterate quickly. Therefore, I added support for any “API” that implements the OpenAI API, e.g., vLLM or Hugging Face TGI. This allows us to evaluate LLMs quickly and without the need to register or implement custom code, including the evaluation of Hosted.
- Start your LLM serving framework, e.g. vLLM
python -m vllm.entrypoints.openai.api_server --model alignment-handbook/zephyr-7b-dpo-full- Run MixEval in another terminal.
MODEL_PARSER_API=$(echo $OPENAI_API_KEY) API_URL=http://localhost:8000/v1 python -m mix_eval.evaluate \
--data_path hf://zeitgeist-ai/mixeval \
--model_name local_api \
--model_path alignment-handbook/zephyr-7b-dpo-full \
--benchmark mixeval_hard \
--version 2024-08-11 \
--batch_size 20 \
--output_dir results \
--api_parallel_num 20In comparison to the local evaluation, we need to make some changes:
API_URL: Domain/URL where our model is hostedAPI_KEY: Optional in case you need authorizationmodel_name: similar to the “local_chat” model we added a “local_api” modelmodel_path: the model id in your Hosted API, e.g., for vLLM, it is the Hugging Face model id
After running the evaluation, MixEval provides a comprehensive breakdown of the model's performance across various metrics.
| Metric | Score |
| --------------------------- | ------- |
| MBPP | 100.00% |
...
| overall score (final score) | 34.85% |
Evaluating Zephyr 7b on 1x H100 with vLLM took 398s or ~7 minutes. That is very quick and also allows evaluation during training. But as you might have noticed, the score is slightly different; instead of 35.15, we achieved 34.85.
Conclusion
MixEval offers a powerful and easy way to evaluate open LLMs. The 0.96 correlation to the LMSYS Chatbot Arena provides reliable results at a fraction of the cost and time. Running MixEval costs just $0.6 using GPT-3.5 as a judge—only 6% of the time and expense of running MMLU.
The improved fork of MixEval allows you to evaluate models using vLLM or TGI in just 7 minutes on a single H100 GPU.
This combination of accuracy, speed, and cost-effectiveness makes MixEval a perfect benchmark to use when building new models.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.