Bite: How Deepseek R1 was trained
DeepSeek AI released DeepSeek-R1, an open model that rivals OpenAI's o1 in complex reasoning tasks, introduced using Group Relative Policy Optimization (GRPO) and RL-focused multi-stage training approach.
Understanding Group Relative Policy Optimization (GRPO)
Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm to improve the reasoning capabilities of LLMs. It was introduced in the DeepSeekMath paper in the context of mathematical reasoning. GRPO modifies the traditional Proximal Policy Optimization (PPO) by eliminating the need for a value function model. Instead, it estimates baselines from group scores, reducing memory usage and computational overhead. GRPO, now also used by the Qwen team, can be used with rule/binary-based Rewards as well as General Reward Models to improve models on helpfulness.
- Sampling: Generate multiple outputs for each prompt using the current policy
- Reward Scoring: Each generation is scored using a reward function, could be (rule-based or outcome-based)
- Advantage Calculation: The average reward of the generated outputs is used as a baseline. The advantage of each solution within the group is then computed relative to this baseline. The reward is normalized within a group.
- Policy Optimization: The policy tries to maximize the GRPO objective, which includes the calculated advantages and a KL divergence term. This is different from how PPO implements the KL term within the reward.

The Key Differences from Proximal Policy Optimization (PPO) are
- No Value Function: Unlike PPO, GRPO does not rely on a separate value function model, which simplifies training and reduces memory consumption.
- Group-Based Advantage: GRPO uses the average reward of a group of outputs as a baseline. This approach better aligns with the nature of reward model training, which often examines multiple outputs for one single input.
- KL Divergence: GRPO directly incorporates the KL divergence term into the loss function, while PPO often uses it as part of the reward signal.
Exhibit: Pure Reinforcement Learning (R1-zero)
In building DeepSeek R1, the team gained deep insights from experimenting with reinforcement learning on their base model. Starting with DeepSeek V3, they applied GRPO to unsupervised reasoning text completions rule-based reward models that focused on aspects like format, mathematics, and coding:
- Accuracy rewards: Evaluate whether the response is correct, correct result or compiled LeetCode problem.
- Format rewards: Evaluate the format that enforces the model to put its thinking process between ‘
’ and ‘ ’ tags.

This leads to a pass@1 score on AIME 2024 increasing from 15.6% to 71.0%, reaching performance levels comparable to OpenAI-o1-0912 alongside output token length per problem increasing, indicating the model naturally learns to solve tasks with more thinking time/token generation.
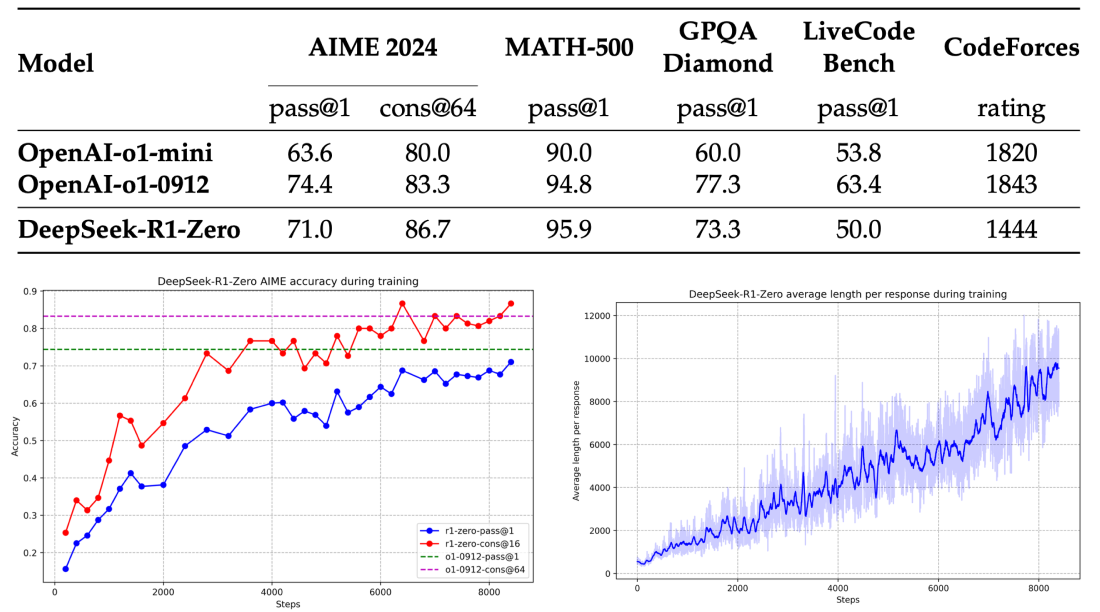
This has the drawback of leading to poor readability and language mixing but it was solved for R1 using a multi-stage approach with alternating SFT → RL steps.
The Multi-Stage Training of DeepSeek R1
To prevent the early unstable cold start phase of reinforcement training (RL) training from the base model, the team started with supervised fine-tuning.
Stage 1/4 Base to Supervised Fine-Tuning (SFT)
Collected up to 10k token-long chain-of-thought (CoT) using the fine-tuned models, R1-zero and human annotator. The data is used to fine-tune Deepseek V3 base to improve readbility and coherence.
Stage 2/4 RL for Reasoning
Used the same RL pipeline as R1-Zero, focusing on reasoning-intensive tasks such as coding and math using the same Rule-Based Reward Models. This time, an additional reward for "language consistency" is used to help the model stick to the same language.
Stage 3/4 Rejection Sampling and SFT
Generated large synthetic dataset using Reject Sampling (RS) focusing on writing, role-playing, and other general-purpose tasks. The model from Stage 2 was used with Deepseek V3 as a Judge to generate 600k reasoning-related samples and 200k for writing, role-playing, and other general-purpose tasks using portions of the SFT dataset of DeepSeek-V3 or regenerating them with CoT included.
Stage 4/4 RL for Helpfulness
In the Final Stage, GRPO is used again with a combination of Rule-Based and Outcome Reward Models to improve the model's helpfulness and harmlessness. Leading to the Deepseek R1 model.
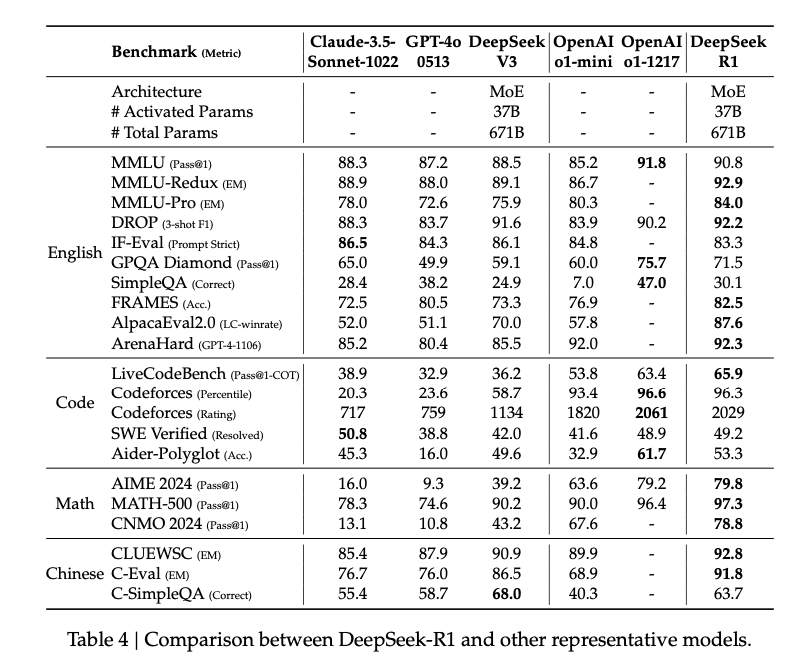
Surprises
- DeepSeek didn't use Monte Carlo Tree Search (MCTS) or Process Reward Models (PRM).
- Fine-tuning before applying GRPO can actually make the training process faster and more stable.
- Rule-based rewards focused on accuracy and format are more effective than complex rewards models.