Context Engineering for AI Agents: Part 2
Earlier this year, Manus published a post on Context Engineering for AI Agents: lessons from building Manus (If you haven't read this first). However, the field moves fast. In a recent webinar, Peak Ji from Manus shared how their Agent Harness has evolved beyond the original post, specifically addressing the challenges of "Context Rot" and multi-agent coordination, and action space management.
This blog dives into learnings from Peak Ji (Manus), Lance Martin (LangChain) and the latest industry research. But before we begin we need a common language.
Context Engineering is the discipline of designing a system that provides the right information and tools, in the right format, to give an LLM everything it needs to accomplish a task. Context Engineering includes Context Offloading (move information to external system), Context Reduction (compress history), Context Retrieval (add information dynamically), Context Isolation (separate context).
Agent Harness is the software that wraps the model, executing tool calls, managing the message history loop, and handling Context Engineering logic. While the LLM provides the reasoning and generates a structured "tool call", the harness is responsible for the actual execution and management.
Context Rot is the phenomenon where an LLM's performance degrade as the context window fills up, even if the total token count is well within the technical limit (e.g., 1 million tokens). The "effective context window", where the model performs at high quality, is often much smaller than the advertised token limit at the moment < 256k tokens for most models.
Context Pollution is the presence of too much irrelevant, redundant, or conflicting information within the context that distracts the LLM and degrades its reasoning accuracy.
Context Confusion is the failure mode where an LLM cannot distinguish between instructions, data, and structural markers, or encounters logically incompatible directives. This frequently occurs when the System Instructions (global rules) clash in itself, have too many similar instructions or with user instructions.
1. Context Compaction and Summarization prevent Context Rot
Context reduction is a general concept to prevent Context Rot, we see two distinct methods Compaction and Summarization emerging as standards with prioritizing reversibility over compression.
Context Compaction (Reversible): Strip out information that is redundant because it exists in the environment. Context Compactions are reversible, this means that If the agent needs to read the code later, it can use a tool to read the file.
- Example: If an agent writes a 500-line code file, the chat history should not contain the file content. It should only contain the file path (e.g.,
Output saved to /src/main.py).
Summarization (Lossy): Use an LLM to summarize the history including tool calls and messages, ofter triggered at context rot threshold, e.g. 128k tokens. When summarizing, Manus keeps the most recent tool calls in their raw, full-detail format. This ensures the model maintains its "rhythm", formatting style and prevents degradation of output quality.
- Example: If context > 128k tokens summarize the oldest 20 turns using JSON structure, while keeping the last 3 turns raw to preserve the model's momentum.
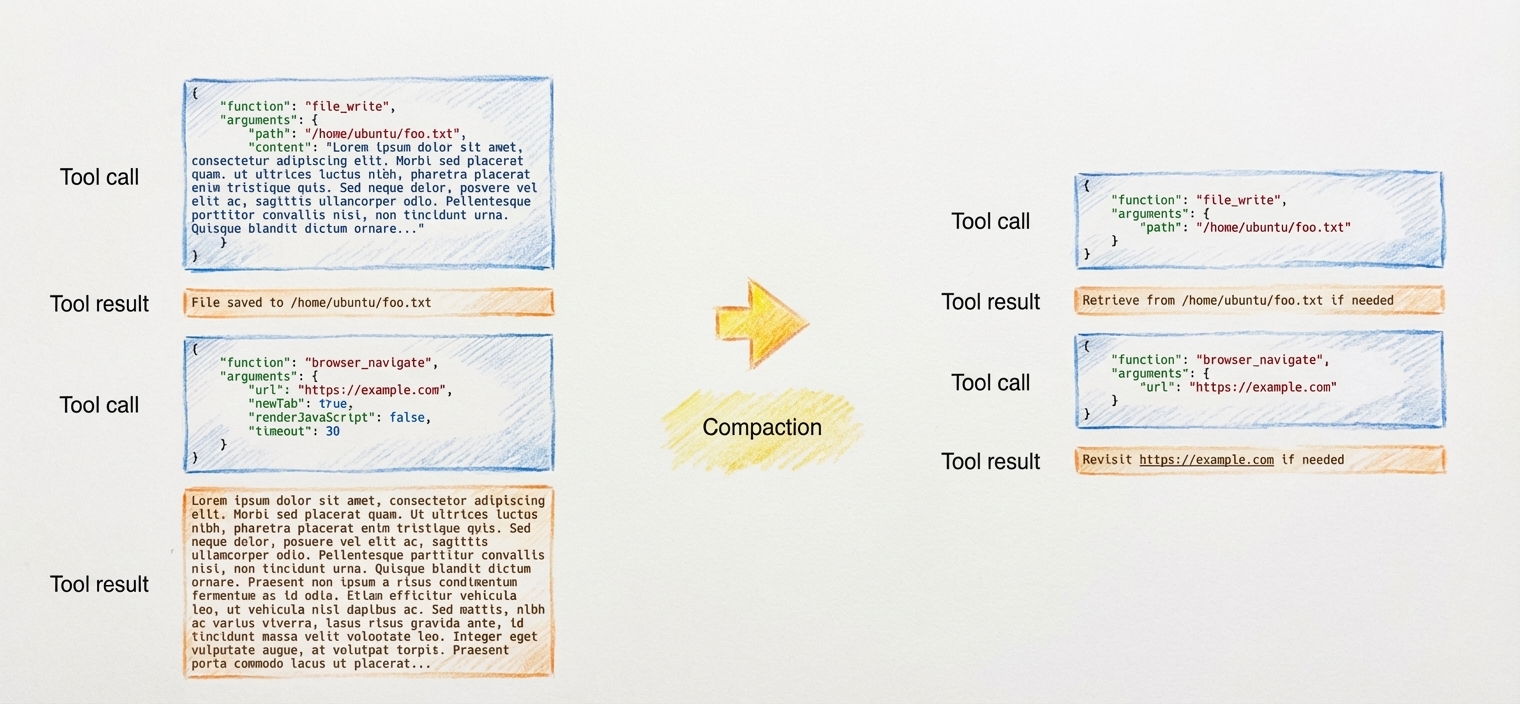
Prefer raw > Compaction > Summarization only when compaction no longer yields enough space.
2. Share Context by communicating, not communicate by sharing context
Multi-agent systems fail due to Context pollution. If every sub-agent shares the same context, you pay a massive KV-cache penalty and confuse the model with irrelevant details. Manus applies a principle from GoLang concurrency to agent architecture: "Share memory by communicating, don't communicate by sharing memory."
Discrete Tasks: For tasks with clear inputs/outputs (e.g., "Search this documentation for X"), spin up a fresh sub-agent with its own context and pass only the specific instruction.
Complex Reasoning: Only share the full memory/context history when the sub-agent must understand the entire trajectory of the problem to function (e.g., a debugging agent that needs to see previous error attempts). Treat shared context as an expensive dependency to be minimized, forking context breaks the Cache.
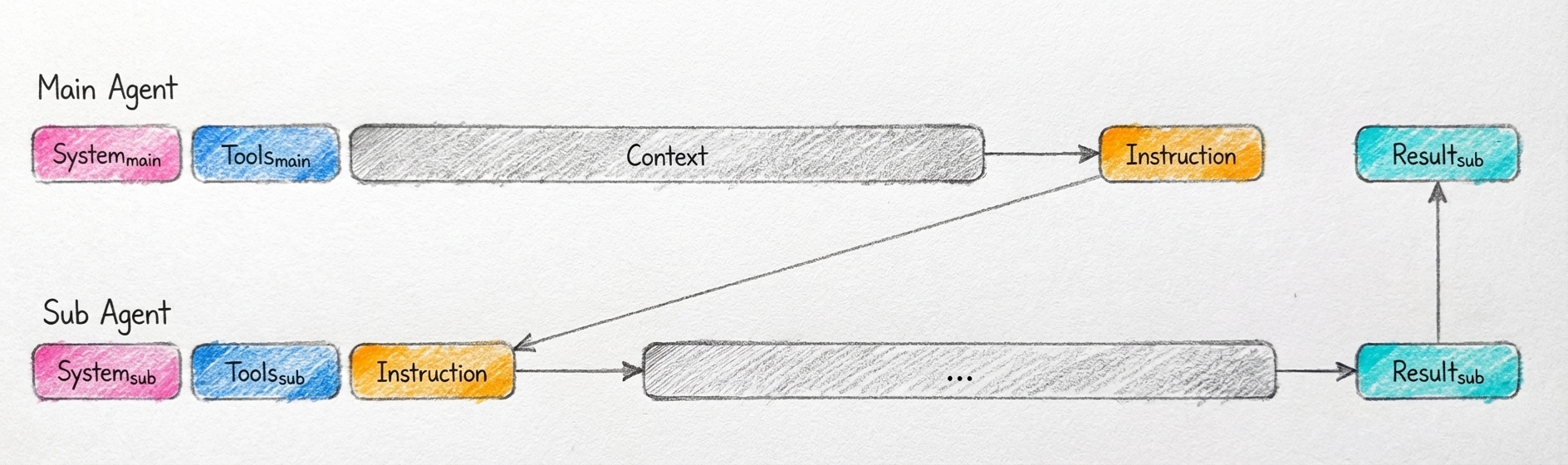
3. Keep the model's toolset small
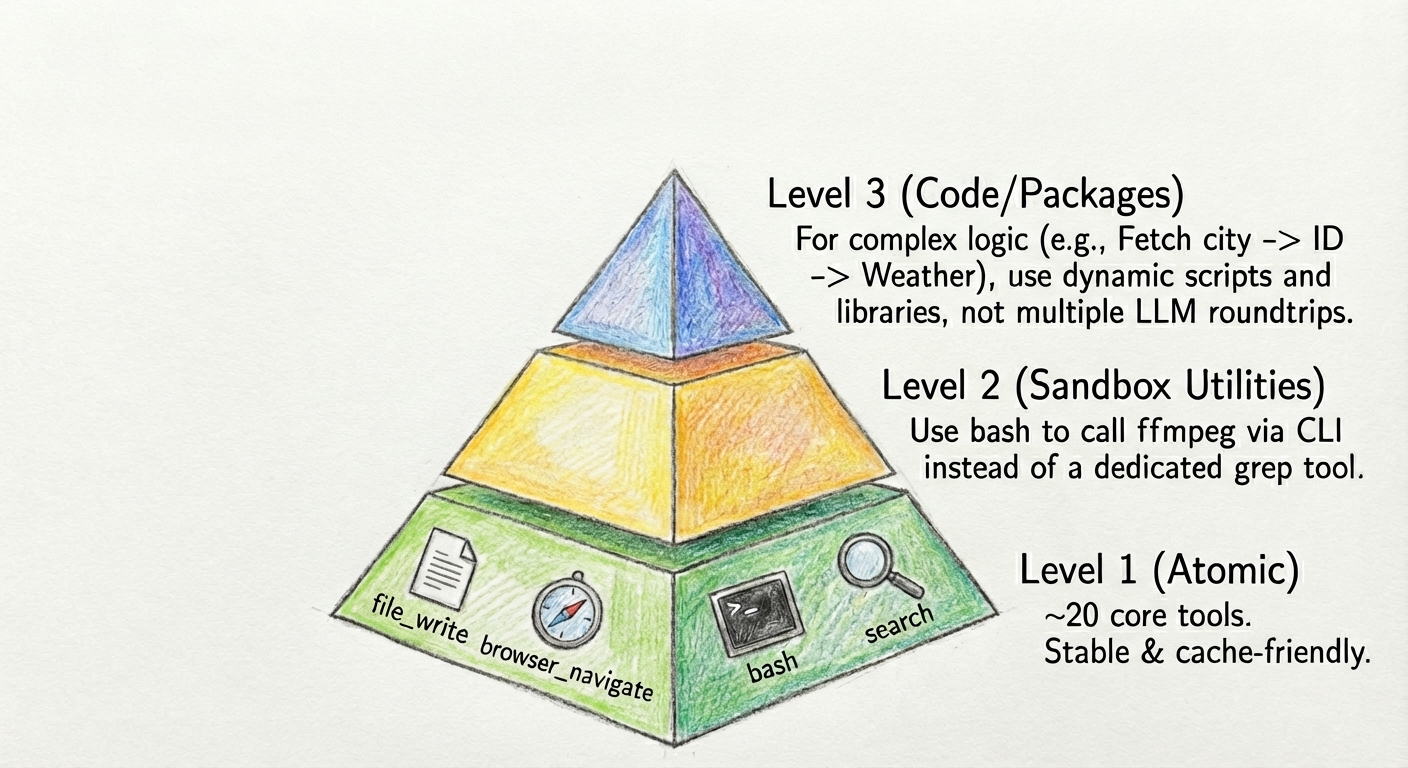
Providing an LLM with 100+ tools leads to Context Confusion where the model hallucinates parameters or calls the wrong tool. Manus solves this with a Hierarchical Action Space:
Level 1 (Atomic): The model sees ~20 core tools (e.g., file_write, browser_navigate, bash, search ...). These are stable and cache-friendly.
Level 2 (Sandbox Utilities): Instead of a specific tool for grep, instruct the model to use the bash tool to call ffmpeg via CLI. Manus has mcp-cli <command>, keeping the tool definitions out of the context window.
Level 3 (Code/Packages): For complex logic chains (e.g., "Fetch city -> Get ID -> Get Weather"), don't make 3 LLM roundtrips. Provide libraries/functions that handle the logic, and let the agent write a dynamic script.
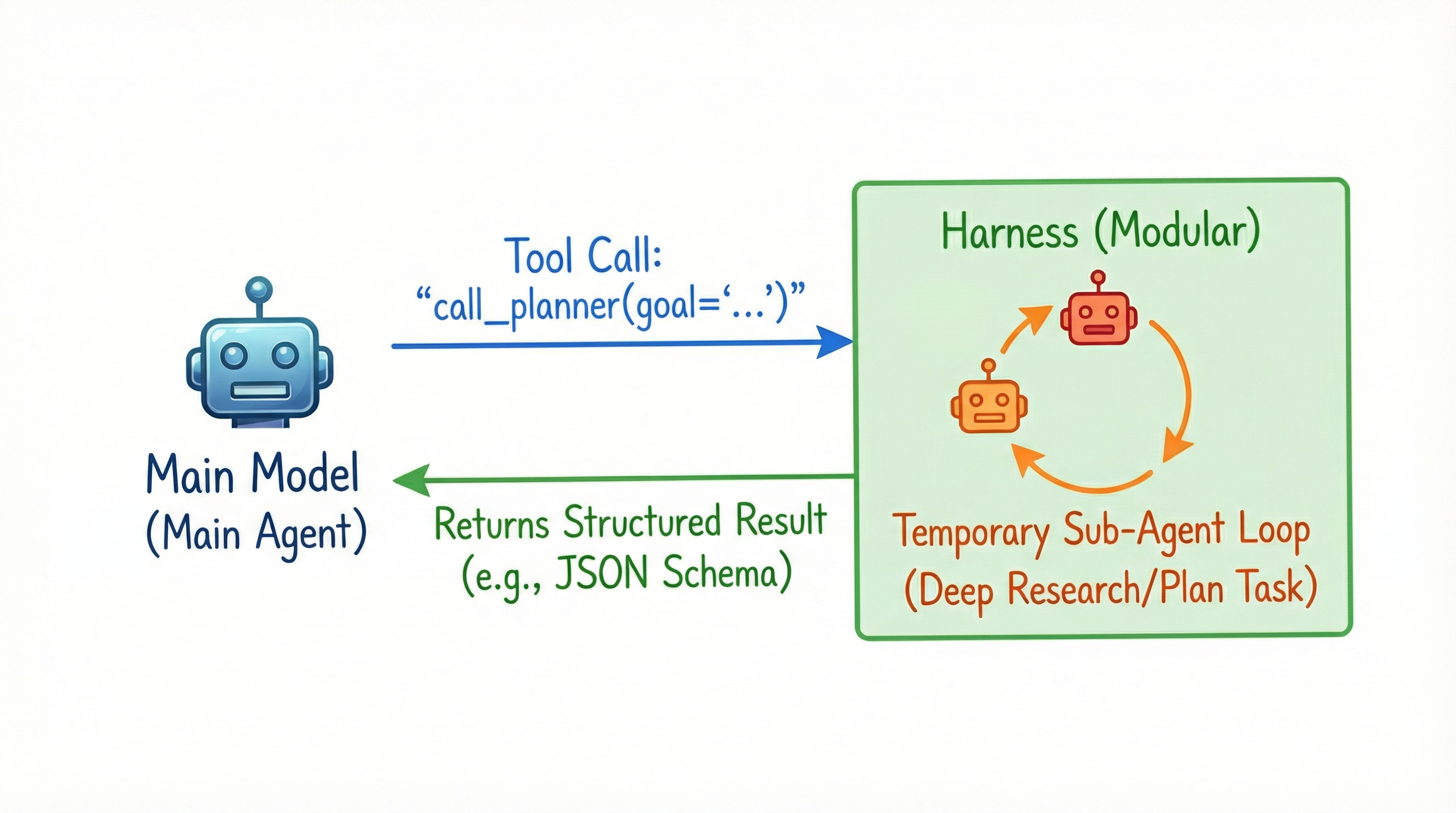
4. Treat "Agent as Tool" with Structured Schemas
Don't over-anthropomorphize your agents. You don't need an "Org Chart" of agents (Manager, Designer, Coder) that chat with each other. Instead, treat Agents as Tools.
For the main model, "Deep Research" or "Plan Task" should just be a tool call. The main agent invokes call_planner(goal="..."), the harness spins up a temporary sub-agent loop and returns a structured result. This flattens complexity and keeps the harness modular.
This "MapReduce" Pattern allows the main agent to treat the sub-agent exactly like a deterministic code function. It can define the goal, tools and output schema (e.g., a specific JSON structure). This ensures the data returned is instantly usable without further parsing or conversation.
5. Best Practices & Implementation Tips
Don't use RAG to manage tool definitions: Fetching tool definitions dynamically per step based on semantic similarity often fails. It creates a shifting context that breaks the KV cache and confuses the model with "hallucinated" tools that were present in turn 1 but disappeared in turn 2.
Don't train your own models (yet): We are living the Bitter Lesson. The harness you build today will likely be obsolete when the next frontier model drops. If you spend weeks fine-tuning a model or training an RL policy on a specific action space, you are locking yourself into a local optimum. Use Context Engineering as the flexible interface that adapts to rapidly improving models.
Define a "Pre-Rot Threshold": If a model has a 1M context window, performance often degrades around < 256k. Don't wait for the API to throw an error. Monitor your token count and implement Compaction or Summarization cycle before you hit the "rot" zone to maintain reasoning quality.
Use "Agent-as-a-Tool" for Planning: In early versions, Manus used a todo.md file that was constantly rewritten. This wasted tokens (~30% in earlier versions of Manus). A better pattern is a specific Planner sub-agent that returns a structured Plan object. This object is injected into the context only when needed, rather than consuming tokens in every turn.
Security & Manual Confirmation: When giving agents browser or shell access, sandbox isolation isn't enough. Try to enforce rules that tokens not leave the sandbox and use human in the loop interrupts for Manual Confirmation before proceeding.
The "Intern Test": Static benchmarks like GAIA saturated quickly and didn't align with user satisfaction. Focus on tasks that are computationally verifiable. Did the code compile? Did the file exist after the command ran? Can the sub-agent verify the output of the parent? Try to use binary success/fail metrics on real environments rather than subjective LLM-as-a-Judge scores.
Embrace "Stochastic Gradient Descent": Manus was rewritten five times in the last six months. LangChain re-architected Open Deep Research four times. This is normal. As models get smarter, your harness changes. If your harness is getting more complex while models improve, you are likely over-engineering.
Conclusion
Perhaps the biggest takeaway was Peak's explanation of complexity. They have rewritten Manus five times. In the last six months, their biggest performance gains didn't come from adding complex RAG pipelines or fancy routing logic. The gains came from removing things.
They removed complex tool definitions in favor of general shell execution.They removed "management agents" in favor of simple structured handoffs. They rely on Agent-as-a-Tool.
As models get stronger, we shouldn't be building more scaffolding, we should be getting out of the model's way. Context Engineering is not about adding more context. It is about finding the minimal effective context required for the next step.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.