How Autoresearch will change Small Language Models adoption
What if you could optimize a model overnight without any ML experience? What if an AI agent runs hundreds of training experiments autonomously, keeping only the improvements? That is the idea behind autoresearch. You give an AI agent a training script and a metric. It edits the code, runs a short experiment, checks if the metric improved, keeps or discards, and repeats. Karpathy used it to squeeze 11% more speed out of his GPT-2 training. Tobi Lütke, Shopify's CEO, trained a 0.8B model overnight that outscored his previous 1.6B.
How Autoresearch Works
An LLM agent that can edit training code, runs a short experiment, checks if the metric improved, and repeats, without human involvement.
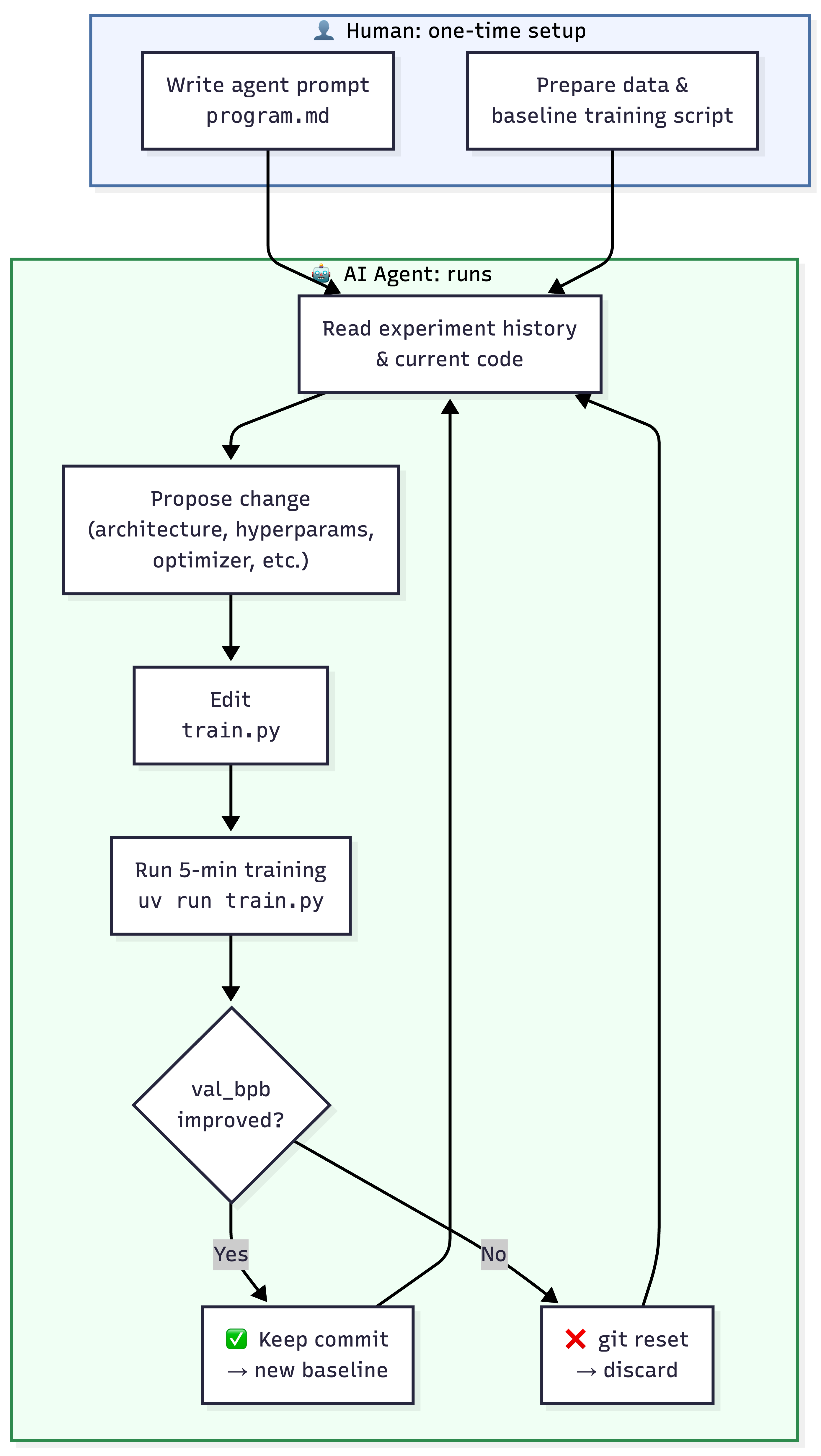
Design constraints that make it work:
- Fixed 5-min time budget. Results stay comparable regardless of what the agent changes.
- Single file scope. Agent edits
train.pyonly. Data prep and evaluation are locked down. - Git as memory. Each experiment is a commit. The agent reads branch history to plan what to try next.
- Binary keep/discard. No human judgment needed.
Roughly 12 experiments/hour. Around 100 overnight.
Two Early Experiments
Both examples below are small-scale and early. The setups are minimal, the models are small, and neither is a controlled study. But they show where this is headed.
Karpathy: 700 experiments on nanochat
Karpathy pointed autoresearch at nanochat, his already well-tuned GPT-2 training codebase. Over two days the agent ran ~700 experiments and found ~20 real improvements. Stacked together, time-to-GPT-2 dropped from 2.02 to 1.80 hours (11% faster). The agent caught things Karpathy had missed:
- Parameterless QKNorm had no scaler multiplier, making attention too diffuse
- Value Embeddings had no regularization applied
- Banded attention window was too conservative
- AdamW betas, weight decay schedule, and initialization were all suboptimal
All improvements transferred from depth-12 to depth-24 models.
Tobi Lütke query expansion overnight
Tobi adapted the pattern for a query-expansion model for the QMD Open source project:
- Told an AI agent to read the autoresearch repo and build a version for QMD. Get training data from tobi/qmd github.
- Went to sleep
- Woke up to a 0.8B model scoring 19% higher than the previous 1.6B model after 37 experiments in 8 hours
A smaller model outperformed one twice its size. He then pointed the same loop at a reranker and beat that baseline too.
How to apply this
The loop hinges on your eval. If the metric is gamed or leaky, the model looks better on paper and fails in production. Your eval set must be held out completely — the agent never touches it, never trains on it, never sees it during optimization. You need a training script the agent can modify, training data (manually labeled or synthetic), and a metric that reflects what the model will actually do in production.
When experiments run 100x faster than a human can manage, your eval becomes the bottleneck. Static benchmarks get saturated. Build your eval pipeline so it can evolve, refresh from real production data, harder edge cases.
The pattern fits search ranking, product categorization, clinical NER, fraud scoring, contract extraction, intent classification, and similar tasks. Small models work well — training runs finish in minutes and improvements transfer when you scale up. Open models like Gemma are a good starting point: small enough for a single GPU, performant for production tasks, commercially licensed.
How this differs from GEPA and prompt optimizers
GEPA (Genetic-Pareto prompt evolution, ICLR 2026) optimizes prompts using genetic evolution and reflection. It works on frozen models and APIs where you cannot change weights.
Autoresearch optimizes weights — it modifies training code, architectures, and hyperparameters to produce a better model.
- GEPA / prompt optimization: No training. Works on frozen models and APIs.
- Autoresearch / weight optimization: Changes the model itself. Requires training infra and data.
For teams building domain SLMs, both layers compound.
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.