Amazon Bedrock: How good (bad) is Titan Embeddings?
Update (November 29, 2023): Since the time of writing the blog AWS reached out to me and also released new features and added missing information:
- Amazon Bedrock now supports batch inference
- Documentation has been added detailing the supported languages, which now includes: English, Arabic, Chinese (Sim.), French, German, Hindi, Japanese, Spanish, Czech, Filipino, Hebrew, Italian, Korean, Portuguese, Russian, Swedish, Turkish, Chinese (trad), Dutch, Kannada, Malayalam, Marathi, Polish, Tamil, Telugu and "others".
I've left the original content of my post intact to preserve the context around what features were initially missing.
Amazon recently announced Bedrock, a fully managed service that provides access to foundation models for text, image, and chat through an API. One of the initial models included is Titan Embeddings, which generates vector representations of input text. Embeddings can be a powerful tool for semantic search, document clustering, and finding semantic similarity. Over the last few weeks, I took a closer look at Amazon Titan Embeddings using the Multitask Text Embedding Benchmark (MTEB).
MTEB is a comprehensive benchmark to measure how well text embedding models capture semantics and meaning. It includes tasks like semantic similarity, text classification, and information retrieval. By evaluating Titan Embeddings on MTEB, we can get a sense of its capabilities on a diverse set of embedding tasks. Key questions we will explore through the post will be:
- How does Titan Embeddings compare to other state-of-the-art embedding models on MTEB?
- What kinds of use cases could Titan Embeddings be well-suited for based on its performance?
What is Amazon Titan Embeddings?
The Titan Embeddings model is one of the initial offerings included with Amazon Bedrock, providing text embedding capabilities. Amazon states that Titan Embeddings is a "large language model" capable of handling up to 8K tokens of input text and outputting embeddings with a dimension of 1536. It supports over 25 languages and is intended for use cases like text retrieval, semantic similarity, and clustering.
However, Amazon has not provided details on the architecture, training data, or model performance of Titan Embeddings. The lack of transparency is disappointing. Without further technical documentation, potential users have little insight into the quality or biases of the Titan embeddings.
The code examples are easy and straightforward using the Bedrock API to generate embeddings but lack any evaluation of the resulting emebeddings. Are they high quality? Do they capture semantics well across languages and use cases? What languages are included in the 25? How do they compare to other publicly available embedding models? These are open questions for those considering using Titan.
Ideally, Amazon would release a technical report with an in-depth analysis of Titan's embeddings on established benchmarks like MTEB. The lack of transparency makes me doubt the claims that Titan is a cutting-edge embedding model.
Evaluating Titan Embeddings on MTEB
Based on my doubts, I evaluated Amazon Titan Embeddings on MTEB, a comprehensive benchmark for evaluating text embedding models across a diverse set of tasks and datasets. With over 50 datasets covering 8 task types and 112 languages, MTEB aims to provide a holistic assessment of embedding models to determine the current state-of-the-art across different use cases. Hugging Face hosts an open Leaderboard for the MTEB benchmark.
At the time of writing, Amazon Bedrock is not offering batching, meaning I could only send one document at a time with strict load limits. This made it impossible to evaluate Titan Embeddings on all 50 datasets. I hand-selected 8 datasets across all tasks:
- MSMARCO: A collection of datasets focused on deep learning in search
- ArguAna: A Full-Text Learning to Rank Dataset for Medical Information Retrieval
- Amazon Counterfactual Classification: Amazon customer reviews annotated for counterfactual detection pair classification.
- Banking77: Online banking queries annotated with their corresponding intents.
- SciDocsRR: Ranking of related scientific papers based on their title.
- SciFact: Scientific claims using evidence from the research literature containing scientific paper abstracts.
- NQ: Question answering dataset of google.com query and a corresponding Wikipedia page.
- TRECCOVID: Scientific articles related to the COVID-19 pandemic
Note: Evaluating Titan on those datasets took ~3 weeks and cost ~150$.
I wrote a small custom module to benchmark Amazon Bedrock with the MTEBpython package, which allowed me to use the Bedrock API. You can find the code on Github to reproduce my results. During the evaluation, I ran into several painful errors, all included in the “The ugly parts about Titan Embedding” section.
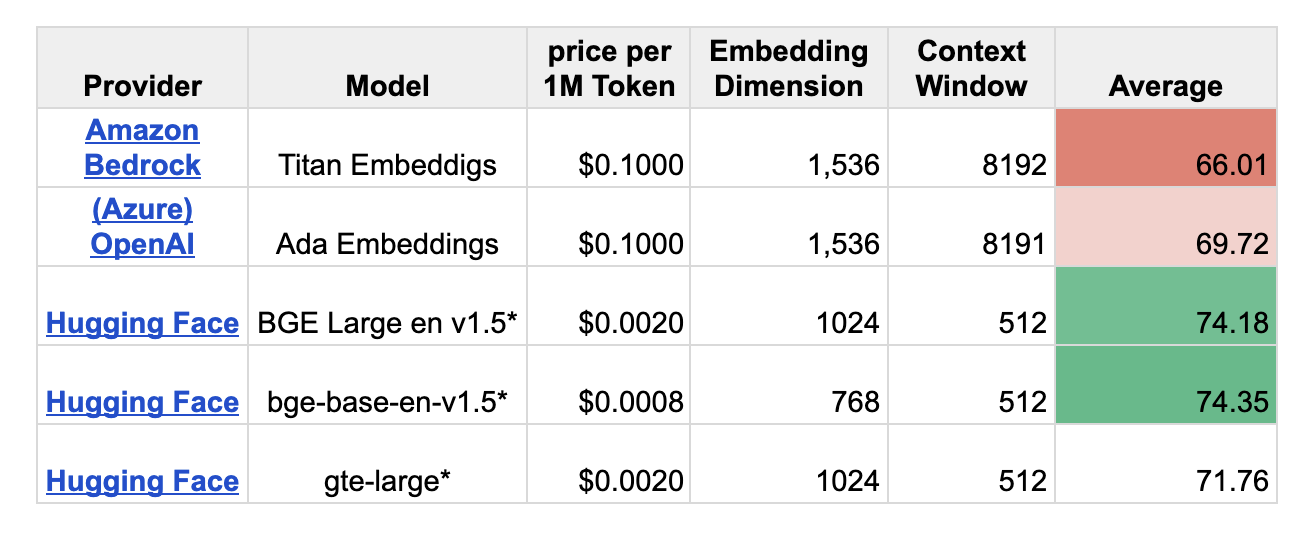
Okay, and now, how good is Amazon Titan Embedding? Well, not as good as you might think. I compared the performance of Titan to the top 3 open-source models and OpenAIs Embedding model (text-embedding-ada-002). Amazon Titan achieves an average score of 66.01, the worst of the five evaluated models. The best open-source model achieves an average of 74.35. You can find an excerpt of the results in the table below or in this Google Sheet.
| Provider | Model | Embedding Dimension | Context Window | Average |
|---|---|---|---|---|
| Amazon Bedrock | Titan Embeddings | 1,536 | 8192 | 66.01 |
| (Azure) OpenAI | Ada Embeddings | 1,536 | 8191 | 69.72 |
| Hugging Face | bge-large-en-v1.5* | 1024 | 512 | 74.18 |
| Hugging Face | bge-base-en-v1.5* | 768 | 512 | 74.35 |
| Hugging Face | gte-large* | 1024 | 512 | 71.76 |
But I didn’t stop there. I also took a look at the pricing. How does Amazon Bedrock compare to OpenAI or to hosting open-source Models?
For The pricing of open-source models, I ran a benchmark with Text-Embedding-Inference using documents with a sequence length of 512 and batch size of 32. The duration was then multiplied by the compute cost of the instance.
Amazon Bedrock is equally expensive as OpenAI with $0.1 per 1M tokens, or 125x more expensive than running bge-base-en-v1.5 (74.35).
| Provider | Model | price per 1M Token | Embedding Dimension | Context Window |
|---|---|---|---|---|
| Amazon Bedrock | Titan Embeddings | $0.1000 | 1,536 | 8192 |
| (Azure) OpenAI | Ada Embeddings | $0.1000 | 1,536 | 8191 |
| Hugging Face | bge-large-en-v1.5* | $0.0020 | 1024 | 512 |
| Hugging Face | bge-base-en-v1.5* | $0.0008 | 768 | 512 |
| Hugging Face | gte-large* | $0.0020 | 1024 | 512 |
Amazon Titan Embeddings Model is not only significantly worse than current open source models, it is also significantly more expensive than open source models.
The ugly parts about Amazon Bedrock and Titan Embeddings
While testing Titan Embedding, I encountered several limitations and pain points that made using the model and evaluation difficult:
- The model supposedly supports 25 languages, but I couldn’t find any documentation about what languages. That makes the whole point of multilingualism useless.
- Titan should accept up to 8K tokens of text input but doesn’t provide a tokenizer. What does Amazon think how someone should know how long your document is? During the evaluation, I ran into
Too many input tokens. Max input tokens: 8192, request input token count: 18422. To overcome this, I recursively reduced the length of the document until the error was gone. - Amazon Bedrock is currently not supporting batching. This means you can only send one document at a time, which is a huge waste of computing and additional network overhead, especially for embeddings. During my test, I only achieved a through of 6 documents per second (single-threaded). For example, embedding 1 million documents would take ~46 hours.
Going back to our initial questions from the introduction.
How does Titan Embeddings compare to other state-of-the-art embedding models on MTEB?
- Amazon Titan Embeddings not only lags behind top open-source models like BGE and GTE, it is also worse than competitive managed solutions.
What kinds of use cases could Titan Embeddings be well-suited for based on its performance?
- At the current state, I can not recommend investing in building applications on Amazon Titan Embeddings.
Conclusion
Overall, evaluating and using Titan Embeddings was less exciting and smooth than I thought when starting the benchmark. The benchmark of Amazon's new Titan Embeddings and Amazon Bedrock showed significant room for improvement.
The service lacks critical features like batching and access to Tokenizer, which are standards for building production-ready applications. The low throughput and quota limits makes it almost impoossible for Titan Embeddings to be used in real applications.
If Amazonians are reading this and are interested in collaborating to improve Titan Embeddings, please let me know. I believe with transparency and technical collaboration, Bedrock could become a very good solution for using hosted foundations and embedding models.
Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.